
Abstract
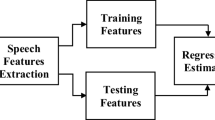
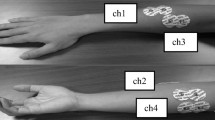
Athlete’s respiratory frequency and the physical energy consumption model based on speech recognition technology is presented in this paper. We use the series of rotation angles reflects changes in the electrical axis of the heart caused by breathing, and then power spectrum analysis of the breathing signal is used to then estimate the breathing rate. The novelties of the paper are summarized as three aspects. (1) Gaussian mixture model is used to model the speaker. This system has the better noise robustness than the traditional feature parameters at low signal-to-noise ratio. (2) We use the photoelectric sensor technology to measure the heart rate of the human body, which can detect weak pulse signals. (3) The collected respiratory sound signals are processed by the dedicated data compression module and then displayed on the entire screen, as the system will show the analytic results. The experimental results have proven the effectiveness of the proposed methodology.







Similar content being viewed by others

References
Allen, T. T., Sui, Z., & Akbari, K. (2018). Exploratory text data analysis for quality hypothesis generation. Quality Engineering,30(4), 701–712. https://doi.org/10.1080/08982112.2018.1481216.
Allen, T. T., Sui, Z., & Parker, N. L. (2017). Timely decision analysis enabled by efficient social media modeling. Decision Analysis,14(4), 250–260. https://doi.org/10.1287/deca.2017.0360.
Badshah, A. M., Rahim, N., Ullah, N., Ahmad, J., Muhammad, K., Lee, M. Y., et al. (2019). Deep features-based speech emotion recognition for smart affective services. Multimedia Tools and Applications,78(5), 5571–5589.
Boeddeker, C., Erdogan, H., Yoshioka, T., & Haeb-Umbach, R., (2018, April). Exploring practical aspects of neural mask-based beamforming for far-field speech recognition. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 6697–6701). IEEE.
Bogomolov, A.V., Dragan, S.P., & Erofeev, G.G., (2019, July). Mathematical model of sound absorption by lungs with acoustic stimulation of the respiratory system. In Doklady Biochemistry and Biophysics (Vol. 487, No. 1, pp. 247–250). Pleiades Publishing.
Chen, Z. & Droppo, J., (2018, April). Sequence modeling in unsupervised single-channel overlapped speech recognition. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 4809–4813). IEEE.
Chen, X., Liu, X., Wang, Y., Ragni, A., Wong, J. H., & Gales, M. J. (2019). Exploiting future word contexts in neural network language models for speech recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing,27(9), 1444–1454.
Chen, Q., Zhang, G., Yang, X., Li, S., Li, Y., & Wang, H. H. (2018). Single image shadow detection and removal based on feature fusion and multiple dictionary learning. Multimedia Tools and Applications,77(14), 18601–18624.
Debi, R., Lakin, R., & Spector, S. (2019). Mid-life crisis or mid-life gains: 2 years of high-intensity exercise is highly beneficial for the middle-aged heart. The Journal of physiology,597(7), 1787–1788.
Deschodt-Arsac, V., Lalanne, R., Spiluttini, B., Bertin, C., & Arsac, L. M. (2018). Effects of heart rate variability biofeedback training in athletes exposed to stress of university examinations. PLoS ONE,13(7), e0201388.
Hodgson, T., Magrabi, F., & Coiera, E. (2018). Evaluating the usability of speech recognition to create clinical documentation using a commercial electronic health record. International Journal of Medical Informatics,113, 38–42.
Lemire, M., Lonsdorfer-Wolf, E., Isner-Horobeti, M. E., Kouassi, B. Y., Geny, B., Favret, F., et al. (2018). Cardiorespiratory responses to downhill versus uphill running in endurance athletes. Research Quarterly for Exercise and Sport,89(4), 511–517.
Liu, Y., Nie, L., Han, L., Zhang, L. & Rosenblum, D.S., (2015, June). Action2Activity: recognizing complex activities from sensor data. In Twenty-fourth international joint conference on artificial intelligence.
Liu, Y., Nie, L., Liu, L., & Rosenblum, D. S. (2016). From action to activity: sensor-based activity recognition. Neurocomputing,181, 108–115.
McRackan, T. R., Bauschard, M., Hatch, J. L., Franko-Tobin, E., Droghini, H. R., Nguyen, S. A., et al. (2018). Meta-analysis of quality-of-life improvement after cochlear implantation and associations with speech recognition abilities. The Laryngoscope,128(4), 982–990.
Merawati, D., Kinanti, R.G., Susanto, H. & Taufiq, A., (2018, September). The attenuation of physical-physiological stresses through musical-high intensity exercise co-treatment in non-athlete individual. In Journal of Physics (vol. 1093, No. 1, p. 012026). IOP Publishing.
Mustafa, M. K., Allen, T., & Appiah, K. (2019). A comparative review of dynamic neural networks and hidden Markov model methods for mobile on-device speech recognition. Neural Computing and Applications,31(2), 891–899.
Plageras, A. P., Psannis, K. E., Stergiou, C., Wang, H., & Gupta, B. B. (2018). Efficient IoT-based sensor BIG Data collection–processing and analysis in smart buildings. Future Generation Computer Systems,82, 349–357.
Ritchie, S., Sproat, R., Gorman, K., van Esch, D., Schallhart, C., Bampounis, N., Brard, B., Mortensen, J.F., Holt, M., & Mahon, E., (2019). Unified verbalization for speech recognition & synthesis across languages. In Proc. Interspeech 2019, pp. (3530–3534).
Shan, C., Weng, C., Wang, G., Su, D., Luo, M., Yu, D. & Xie, L., (2019, May). Investigating End-to-end Speech Recognition for Mandarin-english Code-switching. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6056–6060). IEEE.
Snyder, D., Garcia-Romero, D., Sell, G., Povey, D., & Khudanpur, S. (2018, April). X-vectors: Robust dnn embeddings for speaker recognition. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 5329–5333). IEEE.
Sun, Y. (2019). Analysis for center deviation of circular target under perspective projection. Engineering Computations,36(7), 2403–2413. https://doi.org/10.1108/EC-09-2018-0431.
Susanto, H., Merawati, D., & Andiana, O., (2019, April). The effect of tempo of musical treatment and acute exercise on vascular tension and cardiovascular performance: A case study on trained non-athletes. In IOP Conference Series: Materials Science and Engineering (Vol. 515, No. 1, p. 012033). IOP Publishing.
Tao, F., & Busso, C. (2018). Gating neural network for large vocabulary audiovisual speech recognition. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP),26(7), 1286–1298.
Toshniwal, S., Kannan, A., Chiu, C.C., Wu, Y., Sainath, T.N. & Livescu, K., (2018, December). A comparison of techniques for language model integration in encoder-decoder speech recognition. In 2018 IEEE spoken language technology workshop (SLT) (pp. 369–375). IEEE.
Van Engen, K. J., & McLaughlin, D. J. (2018). Eyes and ears: Using eye tracking and pupillometry to understand challenges to speech recognition. Hearing Research,369, 56–66.
Xiong, W., Wu, L., Alleva, F., Droppo, J., Huang, X., & Stolcke, A. (2018, April). The Microsoft 2017 conversational speech recognition system. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 5934–5938). IEEE.
Zeghidour, N., Usunier, N., Kokkinos, I., Schaiz, T., Synnaeve, G., & Dupoux, E., (2018, April). Learning filterbanks from raw speech for phone recognition. In 2018 IEEE international conference on acoustics, speech and signal Processing (ICASSP) (pp. 5509–5513). IEEE.
Zhang, C., Yu, C., Weng, C., Cui, J. & Yu, D., (2018, December). An exploration of directly using word as ACOUSTIC modeling unit for speech recognition. In 2018 IEEE spoken language technology workshop (SLT) (pp. 64–69). IEEE.
Zhang, X., & Samuel, A. G. (2018). Is speech recognition automatic? Lexical competition, but not initial lexical access, requires cognitive resources. Journal of Memory and Language,100, 32–50.
Zhang, Z., Geiger, J., Pohjalainen, J., Mousa, A. E. D., Jin, W., & Schuller, B. (2018b). Deep learning for environmentally robust speech recognition: An overview of recent developments. ACM Transactions on Intelligent Systems and Technology (TIST),9(5), 49.
Zhou, Y., Xiong, C. & Socher, R., (2018, April). Improving end-to-end speech recognition with policy learning. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 5819–5823). IEEE.
Acknowledgements
This research was supported by the Application Form for General Projects of Philosophy and Social Science Research in Colleges and Universities in Jiangsu Province, Title: Research on the Dilemma and Management Path of Tennis Professionalization in China. Applicant: Yin Shulai 2019SJA0083.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Yin, S., Fang, H. & Hou, X. Athlete’s respiratory frequency and physical energy consumption model based on speech recognition technology. Int J Speech Technol 23, 389–397 (2020). https://doi.org/10.1007/s10772-020-09685-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-020-09685-z