
Abstract
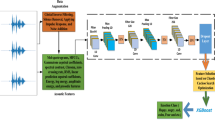
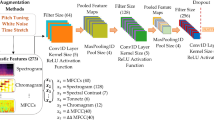
Humans are considered as emotional beings and so the uttered speech reflect the human emotions. Human computer interaction can be done more effectively by automatically identifying the emotions from speech. Automatic speech emotion recognition is applied in many areas like computer gaming, call centre, speech therapy controlling robots etc. Emotion recognition can be considered as feature space to label space mapping. From the uttered speech, the different features are calculated. Then, to automatically recognize the emotions, the relationship between the emotions and the features are learned. The required preprocessing is done with the collected training samples and the features are extracted from the speech signals. The extracted feature vectors are stored in the database. When the input signal comes, the preprocessing and feature extraction are done and the extracted features are compared with the feature vectors in the database to determine the emotion in that speech signal. We have developed a deep learning model for speech emotion recognition with GRU which take the filterbank energies of the speech signals as input. To overcome the problem with the availability of database and to increase the number of input samples, we have applied data augmentation.













Similar content being viewed by others

References
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., Corrado, G. S., Davis, A., Dean, J., Devin, M., & Ghemawat, S. (2015). Tensorflow: Large-scale machine learning on heterogeneous systems. Software Available from Tensorflow. Org, 1(2), 2015.
Bergstra, J., Breuleux, O., Bastien, F., Lamblin, P., Pascanu, R., Desjardins, G., Turian, J., Warde-Farley, D., & Bengio, Y. (2010). Theano: A CPU and GPU math compiler in python. In Proc. 9th Python in Science Conf, vol. 1, pp. 3–10.
Bhatti, M. W., Wang, Y., & Guan, L. (2004). A neural network approach for human emotion recognition in speech. In 2004 IEEE International Symposium on Circuits and Systems (IEEE Cat. No. 04CH37512) (Vol. 2, pp. II-181). IEEE.
Chernykh, V., & Prikhodko, P. (2017). Emotion recognition from speech with recurrent neural networks. http://arxiv.org/abs/1701.08071.
Cowie, R., Douglas-Cowie, E., Tsapatsoulis, N., Votsis, G., Kollias, S., Fellenz, W., & Taylor, J. G. (2001). Emotion recognition in human–computer interaction. IEEE Signal Processing Magazine, 18(1), 32–80.
Devillers, L., Vidrascu, L., & Lamel, L. (2005). Challenges in real-life emotion annotation and machine learning based detection. Neural Networks, 18(4), 407–422.
Eyben, F., Wöllmer, M., & Schuller, B. (2009). OpenEAR—introducing the Munich open-source emotion and affect recognition toolkit. In ACII 2009. 3rd International Conference on Affective Computing and Intelligent Interaction and Workshops, (pp. 1–6). IEEE.
Ghosh, S., Laksana, E., Morency, L. P., & Scherer, S. (2015). Learning representations of affect from speech. http://arxiv.org/abs/1511.04747.
Han, K., Yu, D., & Tashev, I. (2014). Speech emotion recognition using deep neural network and extreme learning machine. In Fifteenth annual conference of the International Speech Communication Association.
Haoxiang, W. (2020). Emotional analysis of Bogus statistics in social media. Journal of Ubiquitous Computing and Communication Technologies (UCCT), 2(03), 178–186.
Hu, H., Xu, M. X., & Wu, W. (2007). GMM supervector based SVM with spectral features for speech emotion recognition. In 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP'07 (Vol. 4, pp. IV-413). IEEE.
Huang, Z., Dong, M., Mao, Q., & Zhan, Y. (2014). Speech emotion recognition using CNN. In Proceedings of the 22nd ACM International Conference on Multimedia (pp. 801–804).
Jacob, I. J. (2019). Capsule network based biometric recognition system. Journal of Artificial Intelligence, 1(02), 83–94.
Kanda, N., Takeda, R., & Obuchi, Y. (2013). Elastic spectral distortion for low resource speech recognition with deep neural networks. In 2013 IEEE Workshop on Automatic Speech Recognition and Understanding (pp. 309–314). IEEE.
Keren, G., & Schuller, B. (2016). Convolutional RNN: an enhanced model for extracting features from sequential data. In 2016 International Joint Conference on Neural Networks (IJCNN), (pp. 3412–3419). IEEE.
Kim, Y., Lee, H., & Provost, E. M. (2013,). Deep learning for robust feature generation in audiovisual emotion recognition. In 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), (pp. 3687–3691). IEEE.
Ko, T., Peddinti, V., Povey, D., & Khudanpur, S. (2015). Audio augmentation for speech recognition. In Sixteenth Annual Conference of the International Speech Communication Association.
Lee, J., & Tashev, I. (2015). High-level feature representation using recurrent neural network for speech emotion recognition. In Sixteenth Annual Conference of the International Speech Communication Association.
Manoharan, S. (2019). Study on Hermitian graph wavelets in feature detection. Journal of Soft Computing Paradigm (JSCP), 1(01), 24–32.
Mao, X., Chen, L., & Fu, L. (2009). Multi-level speech emotion recognition based on HMM and ANN. In 2009 WRI World Congress on Computer Science and Information Engineering (Vol. 7, pp. 225–229). IEEE.
Mao, Q., Dong, M., Huang, Z., & Zhan, Y. (2014). Learning salient features for speech emotion recognition using convolutional neural networks. IEEE Transactions on Multimedia, 16(8), 2203–2213.
Neiberg, D., Elenius, K., & Laskowski, K. (2006). Emotion recognition in spontaneous speech using GMMs. In Ninth International Conference on Spoken Language Processing.
Nicholson, J., Takahashi, K., & Nakatsu, R. (2000). Emotion recognition in speech using neural networks. Neural Computing & Applications, 9(4), 290–296.
Ntalampiras, S., & Fakotakis, N. (2012). Modeling the temporal evolution of acoustic parameters for speech emotion recognition. IEEE Transactions on Affective Computing, 3(1), 116–125.
Nwe, T. L., Foo, S. W., & De Silva, L. C. (2003). Speech emotion recognition using hidden Markov models. Speech Communication, 41(4), 603–623.
Prasomphan, S. (2015). Improvement of speech emotion recognition with neural network classifier by using speech spectrogram. In 2015 International Conference on Systems, Signals and Image Processing (IWSSIP) (pp. 73–76). IEEE.
Schuller, B., Rigoll, G., & Lang, M. (2003). Hidden Markov model-based speech emotion recognition. In 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP'03). (Vol. 2, pp. II-1). IEEE.
Schuller, B., Reiter, S., Muller, R., Al-Hames, M., Lang, M., & Rigoll, G. (2005). Speaker independent speech emotion recognition by ensemble classification. In IEEE International Conference on Multimedia and Expo. ICME 2005, (pp. 864–867). IEEE.
Stuhlsatz, A., Meyer, C., Eyben, F., Zielke, T., Meier, G., & Schuller, B. (2011). Deep neural networks for acoustic emotion recognition: Raising the benchmarks. In 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 5688–5691). IEEE.
Trigeorgis, G., Ringeval, F., Brueckner, R., Marchi, E., Nicolaou, M. A., Schuller, B., & Zafeiriou, S. (2016). Adieu features? End-to-end speech emotion recognition using a deep convolutional recurrent network. In 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 5200–5204). IEEE.
Wang, S., Ling, X., Zhang, F., & Tong, J. (2010). Speech emotion recognition based on principal component analysis and back propagation neural network. In 2010 International Conference on Measuring Technology and Mechatronics Automation (Vol. 3, pp. 437–440). IEEE.
Wang, Z. Q., & Tashev, I. (2017). Learning utterance-level representations for speech emotion and age/gender recognition using deep neural networks. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), (pp. 5150–5154). IEEE.
Wongsuphasawat, K., Smilkov, D., Wexler, J., Wilson, J., Mane, D., Fritz, D., Krishnan, D., Viégas, F. B., & Wattenberg, M. (2017). Visualizing dataflow graphs of deep learning models in tensorflow. IEEE Transactions on Visualization and Computer Graphics, 24(1), 1–12.
Wu, C. H., & Liang, W. B. (2011). Emotion recognition of affective speech based on multiple classifiers using acoustic-prosodic information and semantic labels. IEEE Transactions on Affective Computing, 2(1), 10–21.
Zheng, W. L., Zhu, J. Y., Peng, Y., & Lu, B. L. (2014). EEG-based emotion classification using deep belief networks. In 2014 IEEE International Conference on Multimedia and Expo (ICME), (pp. 1–6). IEEE.
Zheng, W. Q., Yu, J. S., & Zou, Y. X. (2015). An experimental study of speech emotion recognition based on deep convolutional neural networks. In 2015 International Conference on Affective Computing and Intelligent Interaction (ACII) (pp. 827–831). IEEE.
Zhou, J., Wang, G., Yang, Y., & Chen, P. (2006). Speech emotion recognition based on rough set and SVM. In 2006 5th IEEE International Conference on Cognitive Informatics (Vol. 1, pp. 53–61). IEEE.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Praseetha, V.M., Joby, P.P. Speech emotion recognition using data augmentation. Int J Speech Technol 25, 783–792 (2022). https://doi.org/10.1007/s10772-021-09883-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-021-09883-3