
Abstract
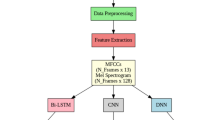
The paper developing a resilient speech classification system for individuals with voice disorders poses a formidable challenge due to the significant variability and distortions inherent in vocal signals. This article outlines the steps to create an effective classification system for pathological speech. The first step involved applying speech enhancement processing using the minimum mean square error (MMSE) enhancer to improve voice input data quality and intelligibility. Secondly, a multi-stream approach combined various acoustic vectors based on human auditory perception, including mel-spectrogram images, mel frequency cepstral coefficients (MFCC), power normalized cepstral coefficients (PNCC), and prosodic parameters like F0, Jitter, and Shimmer. Finally, a deep machine learning incorporating both a convolutional neural network (CNN) and a bidirectional long short-term memory (BiLSTM) network was employed to process these enhanced characteristics in a multi-stream framework, resulting in a powerful classification system architecture. In our experiments, we utilized two subsets from the Massachusetts Eye and Ear Infirmary (MEEI) database, each involving distinct causes of voice disorders. The first subset consisted of voice recordings from patients with vocal nodules, paralysis, and polyps, while the second subset included recordings from patients with mild ventricular compression, A–P squeezing, and gastric reflux. The results we obtained reveal that the CNN-BiLSTM system, coupled with a robust speech analysis interface based on the multi-stream approach and enhanced by the minimum mean square error (MMSE) processing, achieved the highest accuracy rates.









Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.References
Albawi, S., Mohammed, T. A., & Al-Zawi, S. (2017). Understanding of a convolutional neural network. In International conference on engineering and technology (ICET) (pp. 1–6). https://doi.org/10.1109/ICEngTechnol.2017.8308186.
Alhussein, M., & Muhammad, G. (2019). Automatic voice pathology monitoring using parallel deep models for smart healthcare. IEEE Access, 7, 46474–46479. https://doi.org/10.1109/ACCESS.2019.2905597
Amara, F., Fezari, M., & Bourouba, H. (2016). An improved GMM-SVM system based on distance metric for voice pathology detection. An International Journal of Applied Mathematics & Information Sciences, 10(3), 1061–1070. https://doi.org/10.18576/amis/100324
American Speech-Language-Hearing Association. (1993). Definitions of communication disorders and variations [relevant paper]. Retrieved from https://www.asha.org/policy/rp1993-00208/.
Ankışhan, H., & İnam, S. C. (2021). Voice pathology detection by using the deep network architecture. Applied Soft Computing, 106, 107310. https://doi.org/10.1016/j.asoc.2021.107310
Bailly, L., Bernardoni, N. H., Müller, F., Rohlfs, A. K., & Hess, M. (2014). Ventricular-fold dynamics in human phonation. Journal of Speech, Language, and Hearing Research, 57(4), 1219–1242. https://doi.org/10.1044/2014_JSLHR-S-12-0418
Behrman, A., Dahl, L. D., Abramson, A. L., & Schutte, H. K. (2003). Anterior-posterior and medial compression of the supraglottis: Signs of nonorganic dysphonia or normal postures? Journal of Voice, 17(3), 403–410. https://doi.org/10.1067/s0892-1997(03)00018-3
Berouti, M., Schwartz, R., & Makoul, J. (1979). Enhancement of speech corrupted by additive noise. IEEE Transactions on Acoustics, Speech, and Signal Processing. https://doi.org/10.1109/ICASSP.1979.1170788
Brijesh Anilbhai, S., & Kinnar, V. (2017). Spectral subtraction and MMSE: A hybrid approach for speech enhancement. International Research Journal of Engineering and Technology (IRJET), 4(4), 2340–2343.
Brockmann, M., Drinnan, M. J., Storck, C., & Carding, P. N. (2011). Reliable jitter and shimmer measurements in voice clinics: The relevance of vowel, gender, vocal intensity, and fundamental frequency effects in a typical clinical task. Journal of Voice, 25(1), 44–53. https://doi.org/10.1016/j.jvoice.2009.07.002
Brockmann-Bauser, M. (2012). Improving jitter and shimmer measurements in normal voices. Phd Thesis of Newcastle University. http://theses.ncl.ac.uk/jspui/handle/10443/1472.
Carding, P., Bos-Clark, M., Fu, S., Gillivan-Murphy, P., Jones, S. M., & Walton, C. (2016). Evaluating the efficacy of voice therapy for functional, organic, and neurological voice disorders. National Library of Medicine, 42(2), 201–217. https://doi.org/10.1111/coa.12765
Chaiani, M., Selouani, S. A., Boudraa, M., & Sidi Yakoub, M. (2022). Voice disorder classification using speech enhancement and deep learning models. Biocybernetics and Biomedical Engineering, 42, 463–480. https://doi.org/10.1016/j.bbe.2022.03.002
Chung, D. S., Wettroth, C., Hallett, M., & Maurer, C. W. (2018). Functional speech and voice disorders: Case series and literature review. Movement Disorders Clinical Practices, 5(3), 312–316. https://doi.org/10.1002/mdc3.12609
Davis, S. B., & Mermelstein, P. (1980). Comparison of parametric representations for monosyllabic word recognition in continuously spokens entences. IEEE Transactions on Acoustics, Speech, and Signal Processing, 28(4), 357–366. https://doi.org/10.1109/TASSP.1980.1163420
Deli, F., Xuehui, Z., Dandan, C., & Weiping, H. (2022). Pathological voice detection based on phase reconstitution and convolutional neural network. Journal of Voice. https://doi.org/10.1016/j.jvoice.2022.08.028
Disordered Voice Database. (1994). Version 1.03 (CD-ROM), MEEI, Voice and Speech Lab, Kay Elemetrics Corp, Boston, MA, USA.
Duffy, J. R. (2019). Motor speech disorders: Substrates, differential diagnosis, and management, 4th Ed. Retrieved from https://shop.elsevier.com/books/motor-speech-disorders/duffy/978-0-323-53054-5.
El Emary, I. M. M., Fezari, M., & Amara, F. (2014). Towards developing a voice pathologies detection system. Journal of Communications Technology and Electronics, 59, 1280–1288. https://doi.org/10.1134/S1064226914110059
Ephraim, Y., & Malah, D. (1985). Speech enhancement using a minimum mean-square error log-spectral amplitude estimator. IEEE Transactions on Acoustics, Speech, and Signal Processing, 33(2), 443–445. https://doi.org/10.1109/TASSP.1985.1164550
Farhadipour, A., Veisi, H., Asgari, M., & Keyvanrad, M. A. (2018). Dysarthric speaker identification with different degrees of dysarthria severity using deep belief networks. ETRI Journal, 40(5), 643–652. https://doi.org/10.4218/etrij.2017-0260
Gholamalinezhad, H., & Khosravi, H. (2020). Pooling methods in deep neural networks, a review. https://doi.org/10.48550/arXiv.2009.07485.
Guedes, V., Teixeira, F., Oliveira, A., Fernandes, J., Silva, L., Junior, A., & Teixeira, J. P. (2019). Transfer learning with audioset to voice pathologies identification in continuous speech. Procedia Computer Science, 164, 662–669. https://doi.org/10.1016/j.procs.2019.12.233
Gupta, V. K., Bhowmick, A., Mahesh, C., & Saran, S. N. (2011). Speech enhancement using MMSE estimation and spectral subtraction methods. In International conference on devices and communications (ICDeCom) (pp. 1–5). https://doi.org/10.1109/ICDECOM.2011.5738532.
Hamdi, R., Hajji, S., & Cherif, A. (2018). Voice pathology recognition and classification using noise related features. International Journal of Advanced Computer Science and Applications (IJACSA), 9(11), 82–87. https://doi.org/10.14569/IJACSA.2018.091112
Hara, K., Saito, D., Shouno, H. (2015). Analysis of function of rectified linear unit used in deep learning. In International joint conference on neural networks (IJCNN) (pp. 1–8). https://doi.org/10.1109/IJCNN.2015.7280578.
Harar, P., Alonso-Hernandezy, J. B., Mekyska, J., Galaz, Z., Burget, R., & Smekal, Z. (2019). Voice pathology detection using deep learning: a preliminary study. In International conference and workshop on bioinspired intelligence (IWOBI) (pp. 1–4). https://doi.org/10.1109/IWOBI.2017.7985525.
Hossain, M. S., & Muhammad, G. (2016). Healthcare big data voice pathology assessment framework. IEEE Access, 4, 7806–7815. https://doi.org/10.1109/ACCESS.2016.2626316
Janbakhshi, P., Kodrasi. I. (2022a). Adversarial-free speaker identity-invariant representation learning for automatic dysarthric speech classification. In Proceedings of the annual conference of the international speech communication (Interspeech) (pp. 2138–2142). https://doi.org/10.21437/Interspeech.2022-402.
Janbakhshi, P., Kodrasi. (2022b). Experimental investigation on stft phase representations for deep learning-based dysarthric speech detection. In Proceedings of the IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 6477–6481). https://doi.org/10.48550/arXiv.2110.03283.
Jayaraman, D. K., & Das, J. M. (2023). Dysarthria. StatPearls [Internet]. StatPearls Publishing.
Joshy, A. A., & Rajan, R. (2021). Automated dysarthria severity classification using deep learning frameworks. In 28th European signal processing conference (EUSIPCO) (pp. 116–120). https://doi.org/10.23919/Eusipco47968.2020.9287741.
Kadi, K. L., Selouani, S. A., Boudraa, B., & Boudraa, M. (2016). Fully automated speaker identification and intelligibility assessment in dysarthria disease using auditory knowledge. Biocybernetics and Biomedical Engineering, 36, 233–247. https://doi.org/10.1016/j.bbe.2015.11.004
Kaladharan, N. (2014). Speech enhancement by spectral subtraction method. International Journal of Computer Applications, 96(13), 45–48. https://doi.org/10.5120/16858-6739
Karkos, P. D., & McCormick, M. (2009). The etiology of vocal fold nodules in adults. Current Opinion in Otolaryngology & Head and Neck Surgery, 17(6), 420–423. https://doi.org/10.1097/MOO.0b013e328331a7f8
Kent, R. D., & Kim, Y. (2008). Acoustic analysis of speech. In The handbook of clinical linguistics(pp. 360–380). https://doi.org/10.1002/9781444301007.ch22
Kim, C., & Stern, R. M. (2016). Power-normalized cepstral coefficients (PNCC) for robust speech recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 24(7), 1315–1329. https://doi.org/10.1109/TASLP.2016.2545928
Kishore, P. (2011). Speech technology: A practical introduction, topic: spectrogram, cepstrum, and mel frequency analysis. Retrieved from https://www.cs.brandeis.edu/~cs136a/CS136a_docs/KishorePrahallad_CMU_mfcc.pdf.
Klambauer, G., Unterthiner, T., Mayr, A., & Hochreiter, S. (2017). Self-normalizing neural networks. In 31st conference on neural information processing systems (NIPS) (pp. 972–981). https://doi.org/10.48550/arXiv.1706.02515.
Ksibi, A., Hakami, N. A., Alturki, N., Asiri, M. M., Zakariah, M., & Ayadi, M. (2023). Voice pathology detection using a two-level classifier based on combined CNN–RNN architecture. Sustainability, 15(4), 3204. https://doi.org/10.3390/su15043204
Kulkarni, D. S., Deshmukh, R. R., & Shrishrimal, P. (2016). A review of speech signal enhancement techniques. International Journal of Computer Applications, 139(14), 23–26. https://doi.org/10.5120/ijca2016909507
Lee, M. (2023). GELU activation function in deep learning: A comprehensive mathematical analysis and performance. https://doi.org/10.48550/arXiv.2305.12073.
Lim, J. S., & Oppenheim, A. V. (1979). Enhancement and bandwidth compression of noisy speech. Proceedings of the IEEE, 12, 197–210. https://doi.org/10.1109/PROC.1979.11540
Loizou, P. C. (2007). Speech enhancement: Theory and practice. CRC Press. https://doi.org/10.1201/9781420015836
Mayle, A., Mou, Z., Bunescu, R., Mirshekarian, S., Xu, L., & Liu, C. (2019). Diagnosing dysarthria with long short-term memory networks. In Proceedings of the annual conference of the international speech communication (Interspeech) (pp. 4514–4518). https://doi.org/10.21437/Interspeech.2019-2903.
Mediratta, I., Saha, S., Mathur, S. (2021). LipARELU: ARELU networks aided by Lipschitz Acceleration. In International joint conference on neural networks (IJCNN) (pp. 1–8). https://doi.org/10.1109/IJCNN52387.2021.9533853.
Mohammed, H. M. A., Omergolu, A. N., & Oral, E. A. (2023). MMHFNet: Multi-modal and multi-layer hybrid fusion network for voice pathology detection. Expert Systems and Applications, 223, 119790. https://doi.org/10.1016/j.eswa.2023.119790
Narendra, N. P., Schuller, B., & Alku, P. (2021). The detection of Parkinson’s disease from speech using voice source information. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29, 1925–1936. https://doi.org/10.1109/TASLP.2021.3078364
Peng, X., Xu, H., Liu, J., Wang, J., & He, C. (2023). Voice disorder classification using convolutional neural network based on deep transfer learning. Scientific Reports, 13, 7264. https://doi.org/10.1038/s41598-023-34461-9
Picone, J. W. (1993). Signal modeling techniques in speech recognition. Proceedings of the IEEE, 81(9), 1215–1247. https://doi.org/10.1109/5.237532
Pouchoulin, G., Fredouille, C., Bonastre, J. F., Ghio, A., & Giovanni, A. (2007). Frequency study for the characterization of the dysphonic voices. In Interspeech. https://doi.org/10.21437/Interspeech.2007-386
Pützer, M., & Barry, W. J. (2007). Saarbruecken Voice Database. Institut für Phonetik. Universität des Saarlandes. Retrieved from https://stimmdb.coli.uni-saarland.de/help_en.php4.
Shakeel, A. S., Sahidullah, M. D., Fabrice, H., & Slim, O. (2023). Stuttering detection using speaker representations and self-supervised contextual embeddings. International Journal of Speech Technology, 26, 521–530. https://doi.org/10.48550/arXiv.2306.00689
Shakeel, A. S., Sahidullah, M. D., Fabrice, H., & Slim, O. (2021). StutterNet: Stuttering detection using time delay neural network. In 29th European signal processing conference (EUSIPCO) (pp. 426–430). https://doi.org/10.48550/arXiv.2105.05599.
Souissi, N., & Cherif, A. (2015). Dimensionality reduction for voice disorders identification system based on mel frequency cepstral coefficients and support vector machine. In 7th international conference on modelling, identification and control (ICMIC) (pp. 1–6). https://doi.org/10.1109/ICMIC.2015.7409479.
Souli, S., Amami, R., & Ben Yahia, S. (2021). A robust pathological voices recognition system based on DCNN and scattering transform. Applied Acoustics, 177, 107854. https://doi.org/10.1016/j.apacoust.2020.107854
Staudemeyer, R. C., & Morris, E. R. (2019). Understanding LSTM—a tutorial into long short-term memory recurrent neural networks. https://doi.org/10.48550/arXiv.1909.09586.
Strand, O. M., & Egeberg, A. (2004). Cepstral mean and variance normalization in the model domain. In Proceedings of the COST/ISCA tutorial and research workshop on robustness issues in conversational interaction, paper 38.
Sumin, K., Chung, W., & Lee, J. (2021). Acoustic full waveform inversion using discrete cosine transform (DCT). Journal of Seismic Exploration, 30, 365–380.
Suresh, M., & Thomas, J. (2023). Review on dysarthric speech severity level classification frameworks. In International conference on control, communication and computing (ICCC). https://doi.org/10.1109/ICCC57789.2023.10165636.
Teixeira, J. P., Oliveira, C., & Lopes, C. (2013). Vocal acoustic analysis jitter, shimmer and hnr parameters. Procedia Technology, 9(5), 1112–1122. https://doi.org/10.1016/j.protcy.2013.12.124
Toutounchi, S. J. S., Eydi, M., Ej Golzari, S., Ghaffari, M. R., & Parvizian, N. (2014). Vocal cord paralysis and its etiologies: A prospective study. Journal of Cardiovascular and Thoracic Research, 6(1), 47–50. https://doi.org/10.5681/jcvtr.2014.009
Vaiciukynas, E., Gelzinis, A., Verikas, A., & Bacauskiene, M. (2018). Parkinson’s disease detection from speech using convolutional neural networks. In Smart objects and technologies for social good: Third international conference, (Vol. 233, pp. 206–215). https://doi.org/10.1007/978-3-319-76111-4_21
Vakil, N., van Zanten, S. V., Kahrilas, P., Dent, J., & Jones, R. (2006). The Montreal definition and classification of gastroesophageal reflux disease: A global evidence-based consensus. The American Journal of Gastroenterology, 101(8), 1900–1920. https://doi.org/10.1111/j.1572-0241.2006.00630.x
Vásquez-Correa, J. C., Orozco-Arroyave, J. R., & Nöth, E. (2017). Convolutional neural network to model articulation impairments in patients with Parkinson’s disease. In Proceedings of the annual conference of the international speech communication (Interspeech) (pp. 314–318). https://doi.org/10.21437/Interspeech.2017-1078.
Wang, S. S., Wang, C. T., Lai, C. C., Tsao, Y., & Fang, S. H. (2022). Continuous speech for improved learning pathological voice disorders. IEEE Open Journal of Engineering in Medicine and Biology, 3, 25–33. https://doi.org/10.1109/OJEMB.2022.3151233
Westzner, H. F., Schreiber, S., & Amaro, L. (2005). Analysis of fundamental frequency, jitter, shimmer and vocal intensity in children with phonological disorders. Brazilian Journal of Orthinolaryngology, 71(5), 582–588. https://doi.org/10.1016/s1808-8694(15)31261-1
Wu, H., Soraghan, J., Lowit, A., & Di-Caterina, G. (2018). A deep learning method for pathological voice detection using convolutional deep belief networks. In Proceedings of the annual conference of the international speech communication (Interspeech) (pp. 446–450). https://doi.org/10.21437/Interspeech.2018-1351.
Xiaoyu, L. (2018). Deep convolutional and LSTM neural networks for acoustic modelling in automatic speech recognition. Retrieved from https://cs231n.stanford.edu/reports/2017/pdfs/804.pdf.
Xing Luo, O. (2019). Deep learning for speech enhancement- a study on WaveNet, GANs and general RNN architectures. Retrieved from http://www.divaportal.org/smash/get/diva2:1355369/FULLTEXT01.pdf.
Zabret, M., Hočevar Boltežar, I., & Šereg Bahar, M. (2018). The importance of the occupational vocal load for the occurrence and treatment of organic voice disorders. National Library of Medicine. https://doi.org/10.2478/sjph-2018-0003
Zhaoyan, Z. (2016). Mechanics of human voice production and control. The Journal of Acoustical Society of America, 140(4), 2614–2635. https://doi.org/10.1121/1.4964509
Zhou, C., Wu, Y., Fan, Z., Zhang, X., Wu, D., & Tao, Z. (2022). Gammatone spectral latitude features extraction for pathological voice detection and classification. Applied Acoustics, 185(1), 108417. https://doi.org/10.1016/j.apacoust.2021.108417
Zhuge, P., You, H., Wang, H., Zhang, Y., & Du, H. (2016). An analysis of the effects of voice therapy on patients with early vocal fold polyps. Journal of Voice, 30, 698–704. https://doi.org/10.1016/j.jvoice.2015.08.013
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Belabbas, S., Addou, D. & Selouani, S.A. Pathological voice classification system based on CNN-BiLSTM network using speech enhancement and multi-stream approach. Int J Speech Technol 27, 483–502 (2024). https://doi.org/10.1007/s10772-024-10120-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-024-10120-w