
Abstract
Generative Adversarial Networks (GANs) have demonstrated promising results as end-to-end models for whispered to voiced speech conversion. Leveraging non-autoregressive systems like GANs capable of performing conditional waveform generation eliminates the need for separate models to estimate voiced speech features, and leads to faster inference compared to autoregressive methods. This study aims to identify the optimal GAN architecture for the whispered to voiced speech conversion task by comparing six state-of-the-art models. Furthermore, we present a method for evaluating the preservation of speaker identity and local accent, using embeddings obtained from speaker- and language identification systems. Our experimental results show that building the speech conversion system based on the HiFi-GAN architecture yields the best objective evaluation scores, outperforming the baseline by \(\sim\) 9% relative using frequency-weighted Signal-to-Noise Ratio and Log Likelihood Ratio, as well as by \(\sim\) 29% relative using Root Mean Squared Error. In subjective tests, HiFi-GAN yielded a mean opinion score of 2.9, significantly outperforming the baseline with a score of 1.4. Furthermore, HiFi-GAN enhanced ASR performance and preserved speaker identity and accent, with correct language detection rates of up to \(\sim\) 98%.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Whispering is a method of speech communication that is widely used for conveying secret and confidential information. The physiological process of whispered speech production differs from regular speech mainly due to the lack of phonation and the absence of vocal fold vibrations. Without vocal fold vibration, voicing information is lost, consequently, neither a fundamental frequency (F0) nor harmonics are present in whispered speech.
Whispered speech conversion is relevant for various speech processing applications. The performance of automatic speech recognition (ASR) systems often deteriorates, when the recording environment or speaking style is changed. Whispered speech is a change in speaking style that can have a substantial negative effect on recognition accuracy, since most ASR models are trained on regular high-quality speech recordings. Therefore, converting whispered speech as a preprocessing step may improve ASR performance. Furthermore, alaryngeal speech, i.e., the speech produced by a substitute voice after surgical larynx removal (laryngectomy) can be described as a form of whispering without the larynx known as “pseudo-whispering” (Mouret et al., 2022). Hence, the ability to convert whispered speech into voiced speech can also be applied to the problem of voice reconstruction of laryngeal cancer patients, which can potentially improve their quality of life by allowing them to speak with their voice prior to surgery.
In recent years, Generative Adversarial Networks (GANs) (Goodfellow et al., 2014) have achieved state-of-the-art results in conditional waveform generation tasks (Jang et al., 2021; Kong et al., 2020; Yamamoto et al., 2020). GANs are generative models that consist of two separate neural networks; a generator (G) and a discriminator (D). The generator learns a distribution of waveforms by trying to trick the discriminator into classifying the generated samples as ground truth samples. Conditional waveform generation refers to the task of modeling distributions of raw audio waveforms with conditioning information such as text or audio (Kong et al., 2020). GANs achieve considerably faster inference speeds than autoregressive systems (Kalchbrenner et al., 2018; van den Oord et al., 2016) and diffusion probabilistic models (Kong et al., 2021), which makes them particularly interesting for real-time applications, potentially aiding laryngeal cancer patients or individuals who suffer from severe hoarseness. With fewer trainable parameters, they are able to achieve results comparable to or better than models based on normalizing flows (Prenger et al., 2019).
Our goal in this work is to identify the optimal GAN architecture for whispered to voiced speech conversion by using a comprehensive set of subjective and objective measures to evaluate overall quality, naturalness, and intelligibility. Additionally, we assess the ability of the best system to preserve local accents and speaker identities, as well as its potential to improve ASR performance. We are motivated by the state-of-the-art performance GANs have achieved in conditional waveform generation, as well as the promising results from previous studies using GANs specifically for whispered to voiced speech conversion (Gao et al., 2021; Parmar et al., 2019; Pascual et al., 2018; Patel et al., 2019; Shah et al., 2018; Wagner et al., 2022).
Our main contributions are:
-
We train and evaluate six different GAN architectures for transforming whispered speech into voiced speech and show that a model based on HiFi-GAN (Kong et al., 2020) performed best in terms of subjective and objective evaluation results.
-
We conduct an extensive analysis using a wide range of objective performance measures and multiple subjective listening tests to assess overall speech quality, intelligibility and naturalness.
-
We develop a method for evaluating the preservation of speaker identity and local accent, using neural representations obtained from speaker- and language identification systems.
-
We show that the HiFi-GAN-based system not only preserves speaker identity and accent after speech conversion but can also enhance ASR performance on whispered utterances.
2 Related work
Whispered to voiced speech conversion has been explored through various techniques. In Wagner et al. (2022), the authors show that MelGANs (Kumar et al., 2019) and vector-quantized variational autoencoders (VQ-VAEs) (Oord et al., 2017) can be adapted to perform whispered to voiced speech conversion (Wagner et al., 2022). Notably the systems based on MelGAN outperformed VQ-VAEs in this work.
The studies (Parmar et al., 2019; Patel et al., 2019; Shah et al., 2018) use GANs that were originally designed for image generation, such as DiscoGAN (Kim et al., 2017). The models in these works operate only at the feature level and require an additional parametric vocoder for waveform analysis and synthesis. The overall process usually involves two separate models; one for the prediction of voiced Mel cepstral features, and another one for the prediction of the F0 contour based on the whispered features and/or the previously converted ones.
In another GAN-based study (Gao et al., 2021), the generator component is parameterized by a convolutional encoder-decoder structure, enhanced with a Siamese network and a self-attention mechanism, to achieve implicit time alignment between whispered and voiced speech.
In Pascual et al. (2018), voiced waveforms are directly predicted from artificially generated whispered speech using an adaptation of speech enhancement GAN (Pascual et al., 2017). In Rekimoto (2023), whispered speech is encoded into self-supervised speech units obtained with a HuBERT (Hsu et al., 2021) model and decoded into Mel-spectrogram features by a modified FastSpeech2 (Ren et al., 2021) model, which are then converted into the voiced waveform by a GAN-based vocoder.
Other works on whispered to voiced speech conversion employ Gaussian mixture models (Toda & Shikano, 2005), autoencoders (Malaviya et al., 2022), transformers (Niranjan et al., 2021), bidirectional long short-term memory networks (Meenakshi & Ghosh, 2018), and other sequence-to-sequence models (Lian et al., 2019).
3 Method
3.1 Preprocessing
All models used in this work require parallel whispered input and voiced target data. Therefore, all training utterances need to be aligned before they can be used for training.
We use dynamic time warping (DTW) for the whispered and voiced pairs of data to equalize the sequence lengths. First, we apply volume normalization and trimming of leading and trailing silences to each audio sample. Silent frames are detected using an off-the-shelf voice activity detector. The trimming procedure reduced the average length of whispered signals by \(\approx\) 3 s and the length of voiced signals by \(\approx\) 1.5 s. Trimming proved to be crucial to obtain alignments of sufficient quality, since long periods of silence at the beginning and end of utterances caused undesirable artifacts due to the increased length mismatch. DTW is performed in the frequency domain using Mel-spectrogram features extracted from each volume-normalized and trimmed waveform with a window length of 1024, hop length of 256 and 80 Mel channels at a sampling rate of 22.05 kHz. Unless otherwise stated, the same parameters are also used to compute input features for the models used in this study. We experimented with varying hop lengths and window sizes, but found the impact on the overall alignment quality negligible. The extracted whispered and voiced Mel-spectrogram features are passed to the DTW algorithm to compute the optimal alignment path using \(\ell _2\)-distance as the cost function. We also experimented with other distances metrics, but found \(\ell _2\)-distance yielded the most robust overall results. We use linear interpolation to bootstrap the alignment path to the resolution of the raw audio signal. Finally, the sample indices along the bootstrapped time-domain alignment are used to equalize the lengths of each signal pair.
We noticed that how alignments are computed can significantly impact convergence speed and the overall quality achievable by our speech conversion models. First, we experimented with DTW alignment paths computed over the entire length of the utterance. However, despite the trimming of leading and trailing silences, artifacts and occasional dysfluencies remained present in the aligned speech waveforms, since many whispered utterances still had a considerably longer duration than their voiced counterparts. To mitigate this problem further, we leverage the transcripts available for the wTIMIT corpus, apply DTW on word-level after forced alignment, and subsequently concatenate the word-level alignment paths for each utterance. We use the Montreal Forced Aligner tool (McAuliffe et al., 2017) to obtain the word-to-audio alignment for each utterance. Overall, the preprocessing steps had a greater influence on the final results than DTW’s specific hyperparameters.
3.2 GAN architectures
In our experiments, we compare six GAN architectures: MelGAN (Kumar et al., 2019), MB-MelGAN (Yang et al., 2021), HiFi-GAN (Kong et al., 2020), UnivNet (Jang et al., 2021), CARGAN (Morrison et al., 2022), and DiscoGAN (Kim et al., 2017). MelGAN and DiscoGAN have previously been employed for whispered to voiced speech conversion (Parmar et al., 2019; Wagner et al., 2022), and thus serve as baseline models in this study. MB-MelGAN, HiFi-GAN, UnivNet, and CARGAN demonstrated state-of-the-art performance in speech generation tasks and have been widely adopted as neural vocoders in recent years. Therefore, these models are used as candidates to improve the speech conversion results. We describe the key components of these architectures using a unified notation for formulas and provide the most critical hyperparameters used during training.
3.2.1 MelGAN
MelGAN (Kumar et al., 2019) is one of the first fully convolutional feedforward architectures for audio waveform synthesis trained in an adversarial manner. Several components of the other models used in this work have been inspired by MelGAN.
Its generator employs stacks of transposed 1D convolutional layers, which are used to upsample the input Mel-spectrogram until the same temporal resolution as the target waveform is reached. Upsampling is done in four stages with strides \(u \in \lbrace 8, 8, 2, 2 \rbrace\), which corresponds to an overall upsampling factor of 256. The kernel size c in each upsampling layer is tied to the upsampling factor: \(c = 2 \times u\). Three residual blocks (He et al., 2016) with dilated convolutional layers are inserted after each upsampling layer. Dilation grows as a power of the kernel size. The kernel size is 3, which leads to dilation factors of 1, 3, and 9 in each residual block. Additionally, each layer of the generator is weight-normalized. Except for the tanh activation function at the output layer, leaky rectified linear unit (leaky ReLU) is used for activation throughout the generator. The MelGAN generator does not use a global noise vector as input. The process of waveform generation with the MelGAN generator is depicted in Fig. 1.

Structure of the MelGAN generator (Kumar et al., 2019)
The multi-scale discriminator (MSD) employed by MelGAN (cf. Fig. 2) is comprised of three blocks \(D_k\) with identical structure, each receiving differently scaled versions of the audio. The first MSD block \(D_1\) acts on the scale of the final raw audio, whereas \(D_2\) and \(D_3\) act on audio that is downsampled by factors of 2 and 4, respectively. Downsampling is achieved via average pooling with kernel size 4. Each discriminator block consists of a convolutional input layer (kernel size 15, stride 1), four intermediate convolutional layers (kernel size 41, stride 4), and two final convolutional layers (kernel sizes 5 and 3). All discriminator components use the leaky ReLU activation function.

Structure of the MelGAN multi-scale discriminator (Kumar et al., 2019)
MelGAN is trained using the hinge loss version of the GAN objective. The discriminator training objective is defined as follows (Kumar et al., 2019):
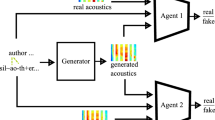
where s is the Mel-spectrogram of the whispered speech and x represents the raw audio waveform of the voiced target. The voiced training target x is passed through each of the k discriminator components. The conditioning information represented by the Mel-spectrogram of the whispered speech s is passed to the generator G and subsequently processed by each of the discriminator components \(D_k\).
The adversarial loss of the generator is given by Kumar et al. (2019):
The cost of feature matching is represented by the \(\ell _1\)-loss between the discriminator outputs of the voiced target audio x and the waveform generated from whispered Mel-spectrograms (s) (Kumar et al., 2019):
T is the number of layers in each discriminator block and N denotes the number of discriminator blocks.
The final objective to train the generator \(\mathcal {L}_{G}\), is the weighted sum of the adversarial loss and the feature matching loss (Kumar et al., 2019):
We use the same parameter \(\lambda _{f m} = 10\) as in Kumar et al. (2019).
3.2.2 Multiband-MelGAN
Multiband-MelGAN (MB-MelGAN) (Yang et al., 2021) aims to improve the original MelGAN by increasing the receptive field of the generator and by replacing the feature matching loss with a multi-resolution STFT loss (cf. Equation 11) (Yamamoto et al., 2019, 2020). The generator takes Mel-spectrograms as input and produces sub-band signals which are subsequently summed to create the full signal. The sub-band target waveforms are obtained through an analysis filter. All sub-band audio signals are passed through a synthesis filter to obtain the full-band scale. The applied filters follow (Yu et al., 2020). The overall process is illustrated in Fig. 3.

Waveform analysis and synthesis process used in the Multiband-MelGAN architecture (Yang et al., 2021)
We use the same parameters as (Yang et al., 2021) for the multi-resolution STFT loss (FFTs (384, 683, 171), window sizes (150, 300, 60), and hop sizes (30, 60, 10)). Upsampling is conducted with factors (strides) of 8, 4, and 2, leading to an overall upsampling factor of 256, since 4 sub-bands are predicted simultaneously. The output channels of the upsampling layers are 192, 96 and 48. As in the original MelGAN, each upsampling layer is composed of transposed convolutions, whose kernel size is twice the size of the stride parameter. MB-MelGAN employs deeper residual stacks than the original MelGAN model, to increase the receptive field. Each residual stack has 4 layers with dilation rates of 1, 3, 9 and 27 and kernel size 3. The output channel of the last convolutional layer is 4 to predict 4-band audio.
MB-MelGAN uses the same 3-block discriminator structure as the original MelGAN, except that each discriminator block has only 3 strided convolutions instead of 4.
3.2.3 HiFi-GAN
HiFi-GAN (Kong et al., 2020) consists of a generator and multiple discriminator blocks. Multi-period discriminators (MPDs) are used to provide adversarial feedback based on disjoint audio samples, and multi-scale discriminators (MSDs) provide feedback based on the waveform at different resolutions. HiFi-GAN is trained using adversarial loss terms for generator and discriminator combined with a Mel-spectrogram loss and a feature matching loss to improve training stability and model performance.
Similar to MelGAN, the generator makes use of transposed convolutions to upsample Mel-spectrogram features until the length of the output sequence matches the temporal resolution of the raw waveform. Additionally, a multi-receptive field fusion (MRF) component consisting of multiple residual blocks with different kernel sizes and dilations is used to generate features based on varying receptive fields in parallel. The outputs from all residual blocks are added to compose the output of the MRF module.
The components of the HiFi-GAN generator are shown in Fig. 4. Mel-spectrograms are upsampled \(|k_u|\) times to match the temporal resolution of the target waveforms. The MRF module adds features from \(|k_r|\) residual blocks of varying kernel sizes and dilation rates. We use the following parameters to implement the generator: The strides u are \(u \in \lbrace 8, 8, 2, 2 \rbrace\). The kernel sizes \(k_u\) of the transposed convolutions are \(k_u \in \lbrace 16, 16, 4, 4 \rbrace\) and the number of channels \(h_u\) in each convolutional layer is \(h_u=512\). The kernel sizes \(k_r\), and dilation rates \(d_r\) of the MRF component are \(k_r \in \lbrace 3, 7, 11 \rbrace\) and \(d_r \in \lbrace 1, 3, 5 \rbrace\).

Structure of the HiFi-GAN generator (Kong et al., 2020)
HiFi-GAN introduces a new discriminator type called multi-period discriminator. Its architecture is depicted in Fig. 5. MPDs consist of five discriminator blocks \(D_k\), each of which operates on different periodic patterns of the audio data. Each discriminator block receives equally spaced samples of the input audio with a spacing determined by a period p. The aim of each MPD block is to capture different implicit structures by attending to different parts of the input audio. We employ the set of periods used in Kong et al. (2020) (\(p \in \lbrace 2, 3, 5, 7, 11 \rbrace\)).

Structure of the HiFi-GAN multi-period discriminator (Kong et al., 2020)
The second discriminator type used in HiFi-GAN is the MSD proposed in MelGAN (Kumar et al., 2019) (cf. Fig. 2).
The training objectives follow (Mao et al., 2017), which replaces the binary cross-entropy terms of the original GAN (Goodfellow et al., 2014) with least squares loss functions.
The adversarial losses for the discriminator \(\mathcal {L}_{Adv}(D; G)\) and the generator \(\mathcal {L}_{Adv}(G; D)\) are defined as (Kong et al., 2020):
where x denotes the target audio waveform (i.e., the voiced speech in our case) and s denotes the Mel-spectrogram condition (obtained from whispered speech in our case).
The Mel-spectrogram loss is the \(\ell _1\) distance between the Mel-spectrogram of the generated waveform and that of the target waveform (Kong et al., 2020):
where \(\mathcal {F}\) represents the transformation of the waveform into the corresponding Mel-spectrogram. Finally, HiFi-GAN adopts the feature matching loss introduced by Kumar et al. (2019) (cf. Eq. 3) to train the generator.
The overall training objective of the generator is a weighted sum of adversarial loss, feature matching loss and Mel-spectrogram loss (Kong et al., 2020):
where \(D_k\) represents the k-th MPD/MSD discriminator block. We follow (Kong et al., 2020) and use \(\lambda _{fm}=2\) and \(\lambda _{mel} = 45\) in our experiments.
The discriminator is trained on the sum of the adversarial losses for each of the K discriminator blocks (Kong et al., 2020):
HiFi-GAN employs a total of 8 discriminator blocks (3 MSD and 5 MPD) to provide adversarial feedback to the generator.
3.2.4 UnivNet
Jang et al. (2021) observe that most neural vocoder implementations use Mel-spectrograms with band-limited frequency range to generate waveforms. The use of full-band Mel-spectrograms can even lead to an over-smoothing problem (Yamamoto et al., 2020). To mitigate these problems, they propose a multi-resolution spectrogram discriminator (MRSD) that operates on linear spectrogram magnitudes computed with various parameter sets, thereby allowing for the use of full-band Mel-spectrograms as input features without over-smoothing.
The architecture of the generator is based on the generators of MelGAN and MB-MelGAN. However, UnivNet includes a noise vector \(z \sim \mathcal {N}(0,1)\). A log-Mel-spectrogram s is used as input to a kernel predictor consisting of 1D convolutions, leaky ReLU activations, and a residual stack. The predicted kernels are passed to a location-variable convolution (LVC) (Zeng et al., 2021) module. Finally, the LVC outputs are fed into a gated activation unit (GAU).
The generator consists of three main blocks. Each block contains a transposed convolutional layer with strides \(s \in \lbrace 8,8,4 \rbrace\) for upsampling. The transposed convolutional layer has a channel size of 32 and a kernel size of \(2 \times s\). All 1D convolutional layers in the generator have the same channel size of 32, except for the last layer, the LVC component and the kernel predictor. The channel dimensions in the last layer are 1 and 64 in the LVC component. Each generator block uses 4 LVC components with dilations \(s \in \lbrace 1,3,9,27 \rbrace\). The convolutional layers of the kernel predictor have a channel size of 64 and kernel sizes of 3, except for the first layer, which has a kernel size set to 5. The slope \(\alpha = -0.2\) is used for each leaky ReLU activation, and weight normalization (Salimans & Kingma, 2016) is applied to all layers. The overall architecture of the generator is illustrated in Fig. 6.

Structure of the UnivNet generator (Jang et al., 2021)
UnivNet employs two types of discriminators: a multi-resolution spectrogram discriminator (MRSD) and multi-period discriminator (MPD). All discriminators provide individual real/fake predictions.
The MRSD architecture is depicted in Fig. 7. The real (x) or generated waveform (\(\hat{x}\)) is first transformed into linear spectrogram magnitudes \(s_m\) and \(\hat{s}_m\) using different parameters in each MRSD block. For M short-time Fourier transform (STFT) parameter sets (i.e., bins in the Fourier transform, frame shift interval, and window length), the final input to the m-th MRSD is given by Jang et al. (2021):
where \(F_m\) is the STFT using the parameter set m.

Structure of the UnivNet multi-resolution spectrogram discriminator (Jang et al., 2021)
The MPD is adopted from HiFi-GAN (Kong et al., 2020) (cf. Fig. 5). The periodic waveform components serving as the input to each MPD block are extracted at intervals of \(p \in \lbrace 2, 3, 5, 7, 11 \rbrace\).
The generator G is trained on an auxiliary multi-resolution STFT loss (Yamamoto et al., 2019, 2020) in addition to the least squares loss (Mao et al., 2017), which is used as the adversarial loss component. The multi-resolution STFT loss is comprised of a spectral convergence loss part \(\mathcal {L}_{sc}\) and a log STFT magnitude loss part \(\mathcal {L}_{mag}\). The auxiliary multi-resolution STFT loss \(\mathcal {L}_{aux}\) is given by Jang et al. (2021):
where \(\Vert \cdot \Vert _\mathfrak {F}\) is the Frobenius norm, \(\Vert \cdot \Vert _1\) is the \(\ell _1\) norm, and S denotes the number of spectrogram elements. The number of loss terms M is the same as the number of MRSD discriminator blocks.
The overall objective of the generator is given by Jang et al. (2021):
where \(\mathcal {L}_{A d v}(G; D)\) is the same as in Eq. (6), except that the noise vector z and the spectrogram of the input speech s are both passed to the generator (G(z, s)). The scalar \(\lambda\) is set to \(\lambda =2\) in our experiments.
The overall discriminator objective is the same as Eq. (9), except that both noise vector z and input spectrogram s are passed to the generator.
The parameter sets for the MRSD and the auxiliary loss computation are triples consisting of the number of points in the Fourier transform, the sample length of the frame shift, and the window size in samples. We use the same STFT parameter sets as in Jang et al. (2021), i.e., (1024, 120, 600), (2048, 240, 1200), and (512, 50, 240).
The model is trained using the Adam (Kingma & Ba, 2015) optimizer with \(\beta _1 = 0.5, \, \beta _2 = 0.9\), and a learning rate of \(10^{-5}\). In a warm-up phase of 100k steps, the generator is trained exclusively on the auxiliary loss and the weights of the discriminators are frozen.
3.2.5 Chunked autoregressive GAN
Chunked Autoregressive GAN (CARGAN) (Morrison et al., 2022) consists of three main components: an autoregressive conditioning stack, a generator, and a series of discriminators. The autoregressive stack aggregates the previous k audio samples into a fixed-length vector, which is concatenated to each frame of the input Mel-spectrogram. The generator uses a modified version of GAN-TTS (Binkowski et al., 2020), incorporating GBlocks and weight normalization (Salimans & Kingma, 2016) to stabilize training. Each GBlock features two convolutional parts with residual connections, using different dilation factors to capture temporal dependencies. The structure of the autoregressive conditioning stack and the generator is illustrated in Fig. 8.

Structure of the modified GAN-TTS generator and the autoregressive conditioning stack of CARGAN (Morrison et al., 2022)
In our model, we introduced three modifications to enhance whisper-to-voiced speech conversion: adding a perceptual loss, conditioning the HiFi-GAN discriminator on pitch and periodicity features extracted using CREPE (Kim et al., 2018), and employing an additional pitch discriminator for joint pitch estimation and real/fake classification. The pitch discriminator predicts a 256-dimensional distribution, where the first 255 components represent pitch values in \(\log _2\) space, and the last component indicates whether the input is real or fake.
The generator loss function includes adversarial loss (Kong et al., 2020), feature matching loss, Mel-spectrogram loss, perceptual loss, and pitch discriminator loss, weighted as follows (Morrison et al., 2022):
where \(\lambda _{\text {fm}}=7\), \(\lambda _{\text {mel}}=18\), \(\lambda _{\text {per}}=1\), and \(\lambda _{\text {pd}}=5\). The perceptual loss \(\mathcal {L}_{\text {Per}}\) is the \(\ell _1\) error between activations from real and generated waveforms passed through CREPE. The HiFi-GAN discriminator is trained using adversarial loss, while the pitch discriminator is trained with cross-entropy loss between its output and the ground truth pitch sequence.
3.2.6 Discovery GAN
Discovery GAN (DiscoGAN) (Kim et al., 2017) learns mappings between two different domains of data. It was originally proposed to generate a new image in one domain, given an image from another domain. The model learns a mapping from domain A to domain B and also a mapping from domain B back to domain A. The mapping from domain B back to domain A is implemented via a second generator. In our case, domain A represents whispered speech features and domain B represents voiced speech features. The generator \(G_{AB}\) that translates input features \(x_A\) from domain A into features \(x_{AB}\) in domain B, is given by Kim et al. (2017):
The generated features are then translated back into domain A features \(x_{ABA}\) with the second generator \(G_{BA}\) (Kim et al., 2017):
A distance metric d is used to measure the reconstruction quality of \(x_{ABA}\) against the original input \(x_A\). The generator \(G_{AB}\) is trained on the reconstruction loss \(\mathcal {L}_{\textrm{Recon}_A}\), and the traditional adversarial loss \(\mathcal {L}_{\textrm{Adv}_B}\) (Goodfellow et al., 2014):
The overall generator loss is the sum of the reconstruction loss part and the adversarial loss part for each generator (Kim et al., 2017):
The generated feature maps \(x_{BA}\) and \(x_{AB}\) are each passed to separate discriminators \(D_A\) and \(D_B\). Both discriminators are optimized using the traditional adversarial loss (Goodfellow et al., 2014). The loss for \(D_B\) is given by Kim et al. (2017):
The overall discriminator loss \(\mathcal {L}_D\) is the sum of the two partial discriminator losses (Kim et al., 2017):
We use the DiscoGAN implementation for whispered to voiced speech conversion from (Parmar et al., 2019) and Shah et al. (2018). Two independent systems are trained. The first model learns mappings between whispered and voiced cepstral features. The second model learns mappings between the cepstral features converted with the first model and the corresponding F0 features of the voiced speech.
All generators consist of three linear layers with 512 hidden units and ReLU activation functions. The output layer uses a linear activation function. All discriminators have three layers with 512 hidden units and ReLU activations, but a sigmoid activation function is used at the output. Mean squared error is used as the reconstruction loss. The models are trained using Adam optimization, with a learning rate of \(10^{-4}\). The 40-dimensional cepstral coefficients and 1-dimensional F0 features are extracted using a statistical vocoder (Erro et al., 2014). The same vocoder is also used for synthesizing the converted speech.
3.3 Modeling details
All models were trained for up to 25,000 epochs on a single A100 GPU with 40GB HBM. The batch sizes used were 512 for MelGAN, Multiband-MelGAN, and DiscoGAN, 128 for HiFi-GAN and UnivNet, and 32 for CARGAN. Model selection was based on the lowest training loss.
By default, we used the AdamW optimizer (Loshchilov & Hutter, 2019) with \(\lambda = 10^{-4}\), \(\epsilon = 10^{-8}\), \(\beta _1 = 0.8\), \(\beta _2 = 0.99\), and an initial learning rate of \(2 \times 10^{-4}\) for the respective discriminators and generators. The learning rate followed an exponential decay schedule with a factor of \(\gamma = 0.999\) per epoch. All input sequences were padded to a maximum length of 8192.
Multiband-MelGAN deviated from this configuration with a weight decay of \(\lambda = 10^{-2}\) and a step-wise learning rate scheduler that decayed the learning rate by 0.5 at milestones of \(1 \times 10^5\), \(2 \times 10^5\), \(3 \times 10^5\), \(4 \times 10^5\), and \(5 \times 10^5\) training steps, rather than the exponential decay. We found this configuration more stable compared to the default. The DiscoGAN configuration followed the baseline implementation (Parmar et al., 2019) with a fixed learning rate of \(10^{-4}\) and the Adam (Kingma & Ba, 2015) optimizer with \(\beta _1 = 0.9,\, \beta _2 = 0.99\) and \(\lambda = 0\).
4 Experiments
We used the architectures and hyperparameters described in Sect. 3 to train GANs for whispered speech conversion and conducted multiple experiments to assess their subjective and objective performance. We compared all six systems (i.e., MelGAN, MB-MelGAN, HiFi-GAN, UnivNet, CARGAN, and DiscoGAN) in an objective evaluation. Based on informal listening tests and the results obtained from the objective evaluation, we decided to focus on the four best models (HiFi-GAN, CARGAN, UnivNet, and DiscoGAN) in the subjective evaluation.
In the objective evaluation, we employed three quality measures and two intelligibility measures. A detailed description of the applied methods is provided in Sect. 4.2. We conducted crowdsourced listening tests to assess the overall speech quality as well as intelligibility and naturalness relative to the voiced target speech. The setups of the subjective listening tests are described in more detail in Sect. 4.3. To assess the preservation of local accents and speaker identities in the converted speech, we further investigated the results in speaker and language identification experiments. Finally, we tested the ability of the best model to improve automatic speech recognition performance.
4.1 Data
All experiments were conducted on the whispered TIMIT (wTIMIT) corpus (Lim, 2010). Each speaker in the corpus uttered approximately 450 phonetically compact sentences from the TIMIT (Garofolo et al., 1993) database in both a regular (voiced) and a whispered manner. The corpus consists of 24 female speakers and 24 male speakers from two main accent groups (Singaporean-English and North-American English). A total of 20 speakers belongs to the Singaporean-English accent group and 28 speakers belong to the North-American English accent group. The speakers in the corpus are between 15 and 40 years old, most of them (19 in total) are between 20 and 25 years old. As it’s essential to have a fully blind test set of unseen speakers to reliably assess the speech conversion quality, we followed (Wagner et al., 2022) and excluded all utterances spoken by ten speakers (five female and five male) from the training data, to serve as the test set. We also balanced the test set across accent groups, i.e., five speakers belong to the Singaporean-English accent group and the other five belong to the North American English accent group. The goal is to ensure diversity in intelligibility, accents, and prosody, allowing us to thoroughly evaluate the system’s performance across these variables and identify potential weaknesses in handling different speech characteristics.
4.2 Objective evaluation
We employed six objective measures for the assessment of the quality and intelligibility of the conversion results: Mel-cepstral Distortion (MCD), Frequency-weighted Segmental Signal-to-Noise Ratio (fwSNRseg), Root Mean Squared Error (RMSE), Log Likelihood Ratio (LLR), Short-time Objective Intelligibility (STOI) and Normalized Covariance Metric (NCM). STOI and NCM are speech intelligibility measures, whereas the other measures target speech quality (Loizou, 2013).
MCD is a commonly used measure to analyze the effectiveness of whisper to voiced speech conversion models (Parmar et al., 2019; Patel et al., 2020), as well as speaker conversion systems (Toda et al., 2007). MCD refers to the sum of squared distances between the voiced and the converted cepstral coefficients summed over all frames in the aligned signals (Mashimo et al., 2001). We extracted 34 Mel-cepstral coefficients (MCEPs) at a frame period of 5 ms for each recording sampled at 22.05 kHz using the WORLD analysis system (MORISE et al., 2016).
In Hu and Loizou (2008), LLR and fwSNRseg have been found to be good predictors for the quality of automatically enhanced speech. Both measures have also been applied to evaluate whispered speech conversion results in McLoughlin et al. (2013). We followed the methods described in Hu and Loizou (2008) to implement the LLR and fwSNRseg measures. The LLR values were limited in the range of [0, 2] and our fwSNRseg calculations were limited in the range of \([-10 \, dB, 35 \, dB]\).
Similar to Parmar et al. (2019), Patel et al. (2019), we computed the RMSE of logF0 values between the voiced and converted speech signals, after aligning all frames in the utterance via DTW. We considered only the voiced regions of the regular target signal in the RMSE computation. The pitch contour was also extracted using the WORLD analysis system.
The STOI measure (Taal et al., 2011) is based on the correlation of temporal envelope segments between reference and processed speech signals. It was proposed to assess the intelligibility of noisy speech at a sampling rate of 10 kHz. Therefore, all utterances were downsampled accordingly. A total of 15 one-third octave bands with a minimum center frequency of 150 Hz were used for the STOI computation. The output of the metric is limited in the range of [0, 1].
The normalized covariance metric (Holube & Kollmeier, 1996) is based on the covariance between the reference and processed envelope signals and has shown high correlations with the intelligibility of enhanced (Ma et al., 2009) and vocoded speech (Chen & Loizou, 2011). We used the approach described in Loizou (2013) to compute NCM. NCM operates on sampling rates of either 8 kHz or 16 kHz. Therefore, all recordings were downsampled to 16 kHz. The SNR needed for NCM computation is limited in the range of \([-15 \, dB, 15 \, dB]\) in each band, and the transmission index in each band is computed by linearly mapping the SNR values between 0 and 1. The number of bands is fixed to 20, the speech dynamic range was limited to \([-15 \, dB, 15 \, dB]\), and the range of modulation frequencies was limited between 0 and 16 Hz. All NCM outputs are limited in the range of [0, 1].
4.3 Listening tests
We conducted subjective speech quality assessment tests on the Amazon Mechanical Turk (AMT) crowdsourcing platform using the Absolute Category Rating (ACR) method and the Comparison Category Ratings (CCR) method. The ACR test assessed the overall speech quality on a 5-point scale consisting of the choices “excellent” (5), “good” (4), “fair” (3), “poor” (2), and “bad” (1). Two CCR tests aimed to assess the intelligibility and naturalness of converted speech samples relative to the corresponding voiced target sample. The choices consisted of “much better” (3), “better” (2), “slightly better” (1), “about the same” (0), slightly worse (-1), worse (-2), much worse (-3).
We employed an ACR test implementation based on the ITU-T P.808 recommendation (ITU-T: ITU-T, 2021). The CCR test implementations were based on (Naderi & Cutler, 2020). To ensure that only experienced workers participated in the study, we excluded participants with an approval rate of less than 97% or less than 500 approved tasks. As an additional requirement, we accepted only participants located in native English-speaking countries (US, UK, IE, NZ, AU, and CA).
All tests included a qualification section to ensure participant eligibility. We excluded non-native speakers, those with hearing disabilities, and recent participants in similar tests. Participants were required to use headsets in a quiet environment and maintain consistent volume throughout the task.
Participants were asked to adjust their headset volume based on a reference clip and completed a simple math task to confirm their attention. A brief training section familiarized listeners with the quality spectrum and included a sample with a known answer to ensure participants understood the rating process.. For the ACR test, participants had to rate a voiced sample in the highest quality category. In CCR tests, they had to rate two voiced samples as “about the same” (0).
To ensure attentive and complete responses, listeners could only rate samples after full playback and each rating session included clips that asked the participants to explicitly select a specific answer. ACR sessions contained 10 samples, while CCR sessions had 5 sample pairs played in randomized order. Quantity bonuses were awarded for completing 60% of available sessions (9 for ACR, 15 for CCR). Additionally, 20% of raters received a quality bonus based on the Spearman rank-order correlation of their answers with those of other raters.
Additionally, 20% of the raters received a quality bonus based on the Spearman rank-order correlation of their answers to the answers given by all other raters. The raters with the highest correlation to the pool of all raters were chosen for the quality bonus.
4.4 MOS prediction
In addition to the quality ratings provided by humans, we utilized the MOS prediction model proposed in Tseng et al. (2021). The model relies on wav2vec 2.0 (Baevski et al., 2020) as a feature extractor and uses a stack consisting of attention pooling (Safari et al., 2020), a bias network (Leng et al., 2021), and range clipping to predict mean opinion scores from waveform data. We employed a model pre-trained on Voice Conversion Challenge 2018 (VCC 2018) (Lorenzo-Trueba et al., 2018) and Voice Conversion Challenge 2016 (VCC 2016) (Toda et al., 2016) data.
4.5 Speaker and language embeddings
We used pre-trained models based on the ECAPA-TDNN (Desplanques et al., 2020) architecture for both speaker identification (SID) and language identification (LID) tasks.
ECAPA-TDNN proposes several enhancements to the widely used x-vector (Snyder et al., 2018) architecture. It adds 1-dimensional Res2Net (Gao et al., 2021) modules with skip connections as well as squeeze-excitation (SE) blocks (Hu et al., 2018) to capture channel interdependencies. Furthermore, features are aggregated and propagated across multiple layers. ECAPA-TDNN also introduces a channel-dependent self-attention mechanism that uses a global context in the frame-level layers and the statistics pooling layer.
The SID system was trained on the VoxCeleb (Nagrani et al., 2017) dataset with additional augmentations such as noise and reverberation.
The model for LID was trained on the VoxLingua107 (Valk & Alumäe, 2021) dataset. Similar to the SID system, the data was also augmented by adding noise and reverberation.
The main differences between the SID and LID model architecture are the input features, the embedding dimension, and the output dimension of the classification layer. The SID model receives 80-dimensional MFCCs as its input, whereas the LID model uses 60-dimensional MFCCs. The number of hidden units in the embedding layer is 192 for the SID system and 512 for the LID system. The SID system discriminates between 7205 speakers, whereas the LID system classifies 107 different languages.
4.6 Automatic speech recognition
We used the en_video acoustic and language models of the Mod9 ASR EngineFootnote 1 to obtain 1-best hypotheses. The en_video system is a Kaldi-based 16 kHz English ASR model. The acoustic model was trained on more than 10k hours of transcribed videos. The training data contained a variety of foreign accents and exhibits variability in the acoustic quality (e.g. background noises and compression artifacts), which makes the model robust against different dialects and noise conditions. The language model was trained on the transcripts of the Switchboard and Fisher corpora as well as web-scraped text. All audio data was downsampled to the target sampling rate of 16 kHz before it was passed to the ASR model.
5 Results
The results of the objective and subjective quality assessments, as well as our experiments on language identification, automatic speech recognition, and embedding visualization are summarized in this section.
5.1 Objective evaluation
We evaluated the whisper to voiced speech conversion results using six objective quality and intelligibility measures on all utterances spoken by each of the ten speakers in the test set.
The results are summarized in Table 1. Arrows indicate whether lower (\(\downarrow\)) or higher (\(\uparrow\)) values are better for each measure. Bold numbers indicate the model that performed best based on the respective measure. The best overall system was HiFi-GAN, yielding the best results in terms of MCD, fwSNRseg, RMSE, and NCM. UnivNet had the best LLR with 1.097 and DiscoGAN yielded the highest STOI score of 0.618. Except for MelGAN, all systems outperformed the underlying whispered speech across all objective metrics.
Note that the objective measures listed in Table 1 were primarily designed for the evaluation of speech enhancement tasks and can yield misleading results here. Most notable is their inability to distinguish between human-sounding speech and actual human speech production. For example, many samples generated by the MB-MelGAN system contained human sounds that did not constitute discernible words or syllables, whereas CARGAN produced clearly distinguishable words in almost all cases. Nevertheless, MB-MelGAN performed better than CARGAN across all six metrics. Further investigation based on informal listening tests did not indicate any other inconsistencies in the objective evaluation results.
Based on the results presented in Table 1, we conducted subjective quality assessments for the three best performing models HiFi-GAN, UnivNet, and DiscoGAN. Additionally, we included the CARGAN system in the subjective evaluation, since it produced more intelligible outputs than MB-MelGAN.
5.2 ACR test
We evaluated the overall speech quality using a crowdsourced listening test and verified the results with an automatic MOS prediction model (Tseng et al., 2021). Table 2 shows the mean opinion scores (MOS), standard deviation (Std) and 95% confidence interval (CI) obtained via the listening test and the automatic MOS predictor. We conducted each test using a randomly selected subset of 25 utterances from the ten speakers in the test set. However, we ensured that each speaker was present with at least two utterances. The best performing model in both the ACR test and the automatic MOS prediction was HiFi-GAN with average mean opinion scores of 2.90 and 3.04. For the HiFi-GAN experiment, the automatic MOS predictor yielded a higher average score than the whispered input speech.
A comparison of the ACR test results and the automatic MOS predictions reveals differences between the two methods on utterance level. Figure 9 depicts the MOS for each utterance in the ACR test (y-axis) and the MOS predicted by the automatic MOS predictor (x-axis) for the same utterance. There is a strong linear relationship between the MOS prediction and the ACR test results (Pearson \(\rho = 0.88\)). However, the MOS predictions are within a tighter range of 2.1 to 3.5, than the listening test ratings, which range from 1.1 to 4.7. The utterances converted with DiscoGAN are worse than those converted with the other systems. The converted utterances do not reach the quality of the voiced target utterances. However, some utterances converted with HiFi-GAN yielded scores similar to the voiced target speech (between 3.2 and 3.4) based on the automatic MOS prediction, but not based on the ACR test. HiFi-GAN also yielded comparable or better results than the whispered utterances in both the ACR test and the MOS prediction for multiple utterances. Hence, the conversion quality also depends on the speaker, the uttered sentence, and the recording conditions. In fact, several utterances in the wTIMIT corpus contain a considerable amount of background noise (especially in the whispered portion of the data) and the overall intelligibility varies depending on the speaker. UnivNet and CARGAN exhibit the most overlap in their ratings. While the human ratings often attribute a higher quality to the whispered speech, UnivNet and CARGAN also yield MOS predictions comparable to the whispered utterances.

Comparison of MOS predictions and ACR test results on utterance level. Each dot represents an utterance either generated by one of the GANs or the underlying whispered/voiced speech
5.3 CCR tests
The two CCR listening tests on intelligibility and naturalness were conducted using the set of 25 utterances from the ACR test. The results are summarized in Table 3. The results show that the HiFi-GAN experiment yielded the best overall performance. Its comparative naturalness (\(CMOS=-0.87\)) and intelligibility (\(CMOS=-0.89\)) scores were better than those of the underlying whispered speech. CARGAN and UnivNet yielded similar results for both naturalness (\(-\) 1.36 for both models) and intelligibility (\(-\) 1.40 and \(-\) 1.35 respectively). DiscoGAN performed worst in both tests with a naturalness score of − 1.65 and an intelligibility score of − 1.83.
Following (Rosenberg & Ramabhadran, 2017), we conducted a Mann–Whitney U test; a non-parametric test to compare the CMOS results of the best performing model (HiFi-GAN) against all other conditions. The results of the Mann–Whitney U test in Table 4 show significant differences (\(\alpha =0.05\)) between HiFi-GAN and all other conditions for both the CCR test on naturalness and the CCR test on intelligibility, when no bias correction was applied. However, after correcting for utterance bias and participant bias, as suggested in Rosenberg and Ramabhadran (2017), the difference between HiFi-GAN and whispered speech is no longer significant in terms of naturalness and intelligibility. The differences between HiFi-GAN and the other models remain significant for naturalness, but are no longer significant for intelligibility.
5.4 Language identification
We conducted language identification experiments using the language information provided for each speaker in the wTIMIT corpus. Since most speakers in the corpus were labeled with more than one language label, we counted an utterance as correctly detected, when the language classifier detected one of the language labels provided for each speaker. For example, most speakers in the Singaporean-English accent group were labeled with “EN” for English and “MA” for Mandarin to indicate their main language and their accent.
The results are summarized in Table 5. In general, the speakers from the Singaporean-English (SE) accent group were classified less accurately than the speakers in the North-American English (AE) accent group. The percentage of correctly detected utterances for the speech generated with HiFi-GAN varied between 40.0% and 66.4% for the SE accent group and between 70% and 97.6% for the AE accent group. The detection results of the voiced target speech varied between 27.8% and 79.6% for the SE accent group and between 83.1% and 98.2% for the AE accent group On average, \(70.9\%\) (\(\pm 21.7\%\)) of all generated utterances from the ten speakers in the test set were detected correctly. In comparison, the percentage of correctly detected voiced utterances was \(75.9\%\) (\(\pm 23.8\%\)).
We visualized the high-dimensional embeddings extracted from the language identification model by mapping them into two-dimensional space using t-distributed stochastic neighbor embedding (t-SNE) (Maaten & Hinton, 2008). Figure 10 shows t-SNE projections for all speakers in the test set. In comparison to the embeddings obtained from whispered speech, speaker clusters are more distinct and well-separated after converting the whispered speech with HiFi-GAN. Embeddings obtained from whispered speech exhibit more variability than the embeddings obtained after conversion with HiFi-GAN. The global structure after conversion moved away from the structure of whispered speech, towards the structure of the voiced target speech. We assume that this structural shift indicates that the language and accent properties become more pronounced after speech conversion.

Comparison of t-SNE projections obtained from language embeddings of all utterances in the test set. “SE” indicates the Singaporean-English accent group and “AE” indicates the North-American English accent group
5.5 Speaker embeddings
Figure 11 shows t-SNE projections of speaker embeddings for utterances from all ten speakers in the test set. The embeddings representing utterances by a specific speaker are accumulated in their own clusters apart from those of other speakers in all three diagrams. However, the whispered speech embeddings are more widely scattered, compared to those of HiFi-GAN and the voiced target speech. The figure indicates that the speaker identity after conversion with HiFi-GAN is generally well preserved, i.e., embeddings that belong to a specific speaker are clustered together and can be separated from groups that belong to other speakers. The overall structure is comparable to the structure of language embeddings in Fig. 10, i.e., whispered speech embeddings exhibit the most variability and the structure after converting whispered speech with HiFi-GAN becomes more similar to the structure of the voiced target speech.

Comparison of t-SNE projections obtained from speaker embeddings of all utterances in the test set
Additionally, we computed distances in high-dimensional embedding space. The mean pairwise Euclidean distance between embeddings from utterances converted by HiFi-GAN and the whispered versions of these utterances was 225, while the distance to the voiced versions was only 157. The mean pairwise embedding distance for whispered utterances and their corresponding voiced versions was 238. Therefore, converting speech with HiFi-GAN did not only lead to increased compactness and improved separability in two-dimensional space, but it also moved the utterances considerably closer to their voiced targets in high-dimensional embedding space.
5.6 Automatic speech recognition
Finally, we conducted an ASR and MOS prediction experiment for all utterances in the wTIMIT corpus, including those in the training set. Figure 12 depicts word error rates (WERs) and MOS predictions aggregated by speaker for the underlying whispered utterances and the speech converted with HiFi-GAN. The figure is sorted by WER from highest on the left to lowest on the right.

Average word error rates and MOS predictions for all utterances in the wTIMIT corpus converted with HiFi-GAN in comparison to whispered speech grouped by speakers. The speakers that belong to the test set are marked with “test”
Mean opinion scores on speaker-level were generally higher for HiFi-GAN. The average MOS prediction of converted speech was higher than the average MOS prediction of whispered speech for 43 out of the 48 speakers in the corpus.
The average WER of converted utterances was lower than the average WER of whispered utterances for 17 out of 48 speakers. The conversion with HiFi-GAN yielded WER improvements for 9 out of the 10 speakers with the highest WERs (leftmost 10 speakers in Fig. 12). For 13 out of the 15 speakers with the highest WERs, speech conversion HiFi-GAN yielded improvements over whispered speech.
The horizontal lines in Fig. 12 show the average mean opinion scores across all speakers for whispered speech (red line) and converted speech (green line). The average MOS of whispered speech was 2.79 and the average MOS of converted speech was 2.97. Hence, HiFi-GAN was able to improve the overall MOS relative to the original whispered utterances. Below average MOS results coincide with high WERs and can be found primarily on the left side of Fig. 12.
Therefore, we conclude that WER improvements over whispered speech can be primarily found under low speech quality conditions. Speakers with lower average speech quality (in terms of MOS) make it harder for the speech recognition system to predict the uttered words correctly. Applying HiFi-GAN before passing the utterance to the ASR system is likely to yield better recognition performance for utterances spoken by these speakers.
However, for above-average speech quality, conversion negatively affects ASR performance despite higher MOS scores. This aligns with speech enhancement studies, where distortions can worsen ASR performance regardless of improved quality metrics (Iwamoto et al., 2022). Generally, our system’s impact on ASR performance correlates with above or below average MOS predictions.
5.7 Discussion
The results of this study demonstrate the effectiveness of GAN-based models, particularly HiFi-GAN, in converting whispered speech into voiced speech, while preserving speaker identity and improving intelligibility. The subjective and objective evaluations suggest that the synthesis quality is architecture dependent. Therefore, the choice of GAN architecture can significantly impact results. While generally understandable, GAN-generated speech did not match the quality of voiced target speech in the objective evaluation. Remaining quality differences are likely due to artifacts (e.g., clipping, roughness) introduced by DTW alignment during, which could not be fully removed despite the carefully designed preprocessing steps described in Sect. 3.1. These artifacts persist in generated speech even with unaligned inputs.
The dataset used in our experiments is limited to the English language, containing only two main accent groups. Furthermore, the robustness of the GAN models under varying noise conditions and reverberation has not been evaluated.
Our approach has several practical implications. First, whispered speech is often difficult for ASR models to process, but by converting it to a voiced format, the system can enhance the accuracy of voice assistants, transcription tools, and other ASR applications in scenarios where whispered speech is common. Second, our approach holds promise for healthcare applications, particularly for individuals with speech impairments, such as those who have undergone a laryngectomy. By converting whispered or alaryngeal speech into more natural voiced speech, the system can facilitate clearer communication, improving the quality of life for these individuals.
A possible extension of this work could make further use of the data generation capabilities of GANs. Since our models can produce high-quality synthetic voiced speech, they could also be trained to generate artificial whispered speech. Synthetic whispered data could serve as a resource for training other models (e.g. ASR systems), to enhance their robustness.
6 Conclusions
In this work, we explored the use of GAN-based models for whispered to voiced speech conversion, comparing six architectures and evaluating their performance across various subjective and objective measures. Additionally, we presented a method for evaluating the preservation of speaker identity and local accent, using embeddings obtained from speaker- and language identification systems. The model based on HiFi-GAN performed best, consistently improving the intelligibility and quality of whispered speech, while preserving speaker identity and accent. Furthermore, HiFi-GAN improved ASR performance compared to low-quality whispered speech, making it suitable for integration into voice assistants, transcription tools, and communication platforms. Future work will analyze the model’s applicability to a wider range of languages and accents, as well as to varying noise conditions. Additionally, we plan to finetune the HiFi-GAN system for converting alaryngeal speech and explore the possibility of training models without the need for parallel data.
Notes
References
Baevski, A., Zhou, Y., Mohamed, A., & Auli, M. (2020). wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in Neural Information Processing Systems, 33, 12449–12460.
Binkowski, M., Donahue, J., Dieleman, S., Clark, A., Elsen, E., Casagrande, N., Cobo, L.C., & Simonyan, K. (2020). High fidelity speech synthesis with adversarial networks. In 8th International conference on learning representations, (ICLR 2020), Addis Ababa, Ethiopia, April 26–30, 2020.
Chen, F., & Loizou, P. C. (2011). Predicting the intelligibility of vocoded speech. Ear and Hearing, 32(3), 331–338. https://doi.org/10.1097/aud.0b013e3181ff3515
Desplanques, B., Thienpondt, J., & Demuynck, K. (2020). ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in TDNN based speaker verification. In Proceedings Interspeech 2020, (pp. 3830–3834). https://doi.org/10.21437/Interspeech.2020-2650
Erro, D., Sainz, I., Navas, E., & Hernaez, I. (2014). Harmonics plus noise model based vocoder for statistical parametric speech synthesis. IEEE Journal of Selected Topics in Signal Processing, 8, 184–194.
Gao, S., Cheng, M., Zhao, K., Zhang, X., Yang, M., & Torr, P. (2021). Res2net: A new multi-scale backbone architecture. IEEE Transactions on Pattern Analysis & Machine Intelligence, 43(02), 652–662. https://doi.org/10.1109/TPAMI.2019.2938758
Gao, T., Zhou, J., Wang, H., Tao, L., & Kwan, H.K. (2021). Attention-guided generative adversarial network for whisper to normal speech conversion. Preprint at ArXiv abs/2111.01342
Garofolo, J., Lamel, L., Fisher, W., Fiscus, J., Pallett, D., Dahlgren, N., & Zue, V. (1993). TIMIT acoustic-phonetic continuous speech corpus LDC93S1. Linguistic Data Consortium
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative adversarial nets. In Proceedings of the 27th international conference on neural information processing systems, (vol. 2, pp. 2672–2680).
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Identity mappings in deep residual networks. In B. Leibe, J. Matas, N. Sebe, & M. Welling (Eds.), Computer vision - ECCV 2016 (pp. 630–645). Springer.
Holube, I., & Kollmeier, B. (1996). Speech intelligibility prediction in hearing-impaired listeners based on a psychoacoustically motivated perception model. The Journal of the Acoustical Society of America, 100(3), 1703–1716. https://doi.org/10.1121/1.417354
Hsu, W.-N., Bolte, B., Tsai, Y.-H.H., Lakhotia, K., Salakhutdinov, R., & Mohamed, A. (2021). Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29, 3451–3460.
Hu, J., Shen, L., & Sun, G. (2018). Squeeze-and-excitation networks. In 2018 IEEE/CVF conference on computer vision and pattern recognition, (pp. 7132–7141). https://doi.org/10.1109/CVPR.2018.00745
Hu, Y., & Loizou, P. C. (2008). Evaluation of objective quality measures for speech enhancement. IEEE Transactions on Audio, Speech, and Language Processing, 16(1), 229–238. https://doi.org/10.1109/TASL.2007.911054
ITU-T: ITU-T recommendation P.808—subjective evaluation of speech quality with a crowdsourcing approach. Recommendation P.808, International Telecommunication Union, Geneva (2021)
Iwamoto, K., Ochiai, T., Delcroix, M., Ikeshita, R., Sato, H., Araki, S., & Katagiri, S.(2022). How bad are artifacts?: Analyzing the impact of speech enhancement errors on ASR. In Proceedings Interspeech 2022, (pp. 5418–5422). https://doi.org/10.21437/Interspeech.2022-318
Jang, W., Lim, D., Yoon, J., Kim, B., & Kim, J. (2021). UnivNet: A neural vocoder with multi-resolution spectrogram discriminators for high-fidelity waveform generation. In Proceedings Interspeech 2021, (pp. 2207–2211). https://doi.org/10.21437/Interspeech.2021-1016 . ISCA.
Kalchbrenner, N., Elsen, E., Simonyan, K., Noury, S., Casagrande, N., Lockhart, E., Stimberg, F., Oord, A., Dieleman, S., & Kavukcuoglu, K.(2018). Efficient neural audio synthesis. In Proceedings of the 35th international conference on machine learning (PMLR), (pp. 2410–2419). Proceedings of Machine Learning Research.
Kim, J.W., Salamon, J., Li, P., & Bello, J.P. (2018). Crepe: A convolutional representation for pitch estimation. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), (pp. 161–165). https://doi.org/10.1109/ICASSP.2018.8461329
Kim, T., Cha, M., Kim, H., Lee, J. K., & Kim, J. (2017) Learning to discover cross-domain relations with generative adversarial networks. In Proceedings of the 34th international conference on machine learning, (vol. 70, pp. 1857–1865).
Kingma, D.P., & Ba, J.(2015). Adam: A method for stochastic optimization. In Bengio, Y., LeCun, Y. (eds.) 3rd International conference on learning representations, (ICLR 2015), May 7–9, 2015, Conference Track Proceedings. Preprint at arXiv:1412.6980
Kong, J., Kim, J., Bae, J. (2020). Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. In Advances in neural information processing systems, (vol. 33, pp. 17022–17033).
Kong, Z., Ping, W., Huang, J., Zhao, K., & Catanzaro, B. (2021). Diffwave: A versatile diffusion model for audio synthesis. In International conference on learning representations.
Kumar, K., Kumar, R., Boissiere, T., Gestin, L., Teoh, W.Z., Sotelo, J., Brébisson, A., Bengio, Y., & Courville, A (2019) Melgan: Generative adversarial networks for conditional waveform synthesis. In Advances in neural information processing systems, vol. 32.
Leng, Y., Tan, X., Zhao, S., Soong, F., Li, X.-Y., & Qin, T. (2021). MBNET: Mos prediction for synthesized speech with mean-bias network. In 2021 IEEE international conference on acoustics, speech and signal processing (ICASSP 2021), (pp. 391–395). https://doi.org/10.1109/ICASSP39728.2021.9413877
Lian, H., Hu, Y., Yu, W., Zhou, J., & Zheng, W. (2019). Whisper to normal speech conversion using sequence-to-sequence mapping model with auditory attention. IEEE Access, 7, 130495–130504.
Lim, B.P.(2010). Computational differences between whispered and non-whispered speech. PhD thesis, University of Illinois.
Loizou, P. C. (2013). Speech enhancement: Theory and practice (2nd ed.). CRC Press Inc.
Lorenzo-Trueba, J., Yamagishi, J., Toda, T., Saito, D., Villavicencio, F., Kinnunen, T., & Ling, Z. (2018). The voice conversion challenge 2018: Promoting development of parallel and nonparallel methods.
Loshchilov, I., & Hutter, F. (2019). Decoupled weight decay regularization. In International conference on learning representations. Retrieved from https://openreview.net/forum?id=Bkg6RiCqY7
Ma, J., Hu, Y., & Loizou, P. C. (2009). Objective measures for predicting speech intelligibility in noisy conditions based on new band-importance functions. The Journal of the Acoustical Society of America, 125(5), 3387. https://doi.org/10.1121/1.3097493
Maaten, L., & Hinton, G. (2008). Visualizing data using T-SNE. Journal of Machine Learning Research, 9, 2579–2605.
Malaviya, H., Shah, J., Patel, M., Munshi, J., & Patil, H.A. (2020). Mspec-net: Multi-domain speech conversion network. In 2020 IEEE international conference on acoustics, speech and signal processing (ICASSP 2020), (pp. 7764–7768). https://doi.org/10.1109/ICASSP40776.2020.9052966
Mao, X., Li, Q., Xie, H., Lau, R.Y.K., Wang, Z., & Smolley, S.P.(2017). Least squares generative adversarial networks. In 2017 IEEE international conference on computer vision (ICCV), (pp. 2813–2821). https://doi.org/10.1109/ICCV.2017.304
Mashimo, M., Toda, T., Shikano, K., & Campbell, N. (2001). Evaluation of cross-language voice conversion based on GMM and straight. In Proceedings 7th European conference on speech communication and technology (Eurospeech 2001), (pp. 361–364). ISCA.
McAuliffe, M., Socolof, M., Mihuc, S., Wagner, M., & Sonderegger, M. (2017). Montreal forced aligner: Trainable text-speech alignment using Kaldi. In Proceedings Interspeech 2017, (pp. 498–502). https://doi.org/10.21437/Interspeech.2017-1386
McLoughlin, I.V., Li, J., & Song, Y. (2013). Reconstruction of continuous voiced speech from whispers. In Proceedings Interspeech 2013, (pp. 1022–1026). https://doi.org/10.21437/Interspeech.2013-111
Meenakshi, G.N., & Ghosh, P.K. (2018). Whispered speech to neutral speech conversion using bidirectional LSTMS. In Proceedings Interspeech 2018, (pp. 491–495). ISCA.
Morise, M., Yokomori, F., & Ozawa, K. (2016). World: A vocoder-based high-quality speech synthesis system for real-time applications. IEICE Transactions on Information and Systems. https://doi.org/10.1587/transinf.2015EDP7457
Morrison, M., Kumar, R., Kumar, K., Seetharaman, P., Courville, A., & Bengio, Y. (2022). Chunked autoregressive GAN for conditional waveform synthesis. In International conference on learning representations (ICLR).
Mouret, F., Crevier-Buchman, L., & Pillot-Loiseau, C. (2022). Intelligibility of pseudo-whispered speech after total laryngectomy. Clinical Linguistics & Phonetics. Advance online publication https://doi.org/10.1080/02699206.2022.2092425
Naderi, B., & Cutler, R. (2020). An open source implementation of ITU-T Recommendation P.808 with validation. In Proceedings Interspeech 2020, (pp. 2862–2866). https://doi.org/10.21437/Interspeech.2020-2665
Nagrani, A., Chung, J.S., & Zisserman, A. (2017). VoxCeleb: A large-scale speaker identification dataset. In Proceedings Interspeech 2017, (pp. 2616–2620). https://doi.org/10.21437/Interspeech.2017-950
Niranjan, A., Sharma, M., Gutha, S.B.C., & Shaik, M.A.B. (2021). End-to-end whisper to natural speech conversion using modified transformer network. Preprint at ArXiv abs/2004.09347
Oord, A., Vinyals, O., & Kavukcuoglu, K. (2017). Neural discrete representation learning. In Advances in neural information processing systems, (NeurIPS 2017), vol. 30.
Parmar, M., Doshi, S., Shah, N.J., Patel, M., & Patil, H.A. (2019). Effectiveness of cross-domain architectures for whisper-to-normal speech conversion. In 27th European signal processing conference (EUSIPCO), (pp. 1–5). EURASIP.
Pascual, S., Bonafonte, A., & Serrà , J. (2017). SEGAN: Speech enhancement generative adversarial network. In Proceedings Interspeech 2017, (pp. 3642–3646). ISCA.
Pascual, S., Bonafonte, A., Serrà , J., & Gonzá¡lez López, J.A.(2018). Whispered-to-voiced alaryngeal speech conversion with generative adversarial networks. In Proceedings IberSPEECH 2018, (pp. 117–121). ISCA.
Patel, M., Parmar, M., Doshi, S., Shah, N., & Patil, H. (2019). Novel inception-GAN for whispered-to-normal speech conversion. In Proceedings 10th ISCA workshop on speech synthesis (SSW 10), (pp. 87–92). https://doi.org/10.21437/SSW.2019-16
Patel, M., Purohit, M., Shah, J., & Patil, H.A. (2020). CinC-GAN for effective F0 prediction for whisper-to-normal speech conversion. In 2020 28th European signal processing conference (EUSIPCO), (pp. 411–415). Retrieved from https://doi.org/10.23919/Eusipco47968.2020.9287385 . https://www.eurasip.org/proceedings/eusipco/eusipco2020/pdfs/0000411.pdf
Prenger, R., Valle, R., & Catanzaro, B. (2019). Waveglow: A flow-based generative network for speech synthesis. In 2019 IEEE international conference on acoustics, speech and signal processing (ICASSP), (pp. 3617–3621). IEEE.
Rekimoto, J. (2023). WESPER: Zero-shot and realtime whisper to normal voice conversion for whisper-based speech interactions. In Proceedings of the 2023 CHI conference on human factors in computing systems (CHI ’23). https://doi.org/10.1145/3544548.3580706
Ren, Y., Hu, C., Tan, X., Qin, T., Zhao, S., Zhao, Z., & Liu, T.-Y. (2021). Fastspeech 2: Fast and high-quality end-to-end text to speech. In International conference on learning representations (ICLR). https://openreview.net/forum?id=piLPYqxtWuA
Rosenberg, A., & Ramabhadran, B. (2017). Bias and statistical significance in evaluating speech synthesis with mean opinion scores. In Proceedings Interspeech 2017, (pp. 3976–3980). https://doi.org/10.21437/Interspeech.2017-479
Safari, P., India, M., & Hernando, J. (2020). Self-attention encoding and pooling for speaker recognition. In Proceedings Interspeech 2020, (pp. 941–945). https://doi.org/10.21437/Interspeech.2020-1446
Salimans, T., & Kingma, D.P. (2016). Weight normalization: A simple reparameterization to accelerate training of deep neural networks. In Advances in neural information processing systems, vol. 29. Retrieved from https://proceedings.neurips.cc/paper/2016/file/ed265bc903a5a097f61d3ec064d96d2e-Paper.pdf
Shah, N., Parmar, M., Shah, N., & Patil, H.A.(2018). Novel MMSE DiscoGAN for crossdomain whisper-to-speech conversion. In Machine learning in speech and language processing workshop, (MLSLP), (pp. 1–3). Google.
Snyder, D., Garcia-Romero, D., McCree, A., Sell, G., Povey, D., & Khudanpur, S. (2018). Spoken Language Recognition using X-vectors. In Proceedings the speaker and language recognition workshop (Odyssey 2018), (pp. 105–111). https://doi.org/10.21437/Odyssey.2018-15
Taal, C. H., Hendriks, R. C., Heusdens, R., & Jensen, J. (2011). An algorithm for intelligibility prediction of time-frequency weighted noisy speech. IEEE Transactions on Audio, Speech, and Language Processing, 19(7), 2125–2136. https://doi.org/10.1109/TASL.2011.2114881
Toda, T., Black, A. W., & Tokuda, K. (2007). Voice conversion based on maximum-likelihood estimation of spectral parameter trajectory. IEEE Transactions on Audio, Speech, and Language Processing, 15(8), 2222–2235. https://doi.org/10.1109/TASL.2007.907344
Toda, T., Chen, L.-H., Saito, D., Villavicencio, F., Wester, M., Wu, Z., & Yamagishi, J. (2016). The voice conversion challenge 2016. In Proceedings Interspeech 2016, (pp. 1632–1636). https://doi.org/10.21437/Interspeech.2016-1066
Toda, T., & Shikano, K. (2005). Nam-to-speech conversion with gaussian mixture models. In INTERSPEECH 2005— Eurospeech, 9th European conference on speech communication and technology, (pp. 1957–1960). ISCA.
Tseng, W.-C., Huang, C.-y., Kao, W.-T., Lin, Y.Y., Lee, H.-y.(2021). Utilizing self-supervised representations for MOS prediction. In Proceedings Interspeech 2021, (pp. 2781–2785). https://doi.org/10.21437/Interspeech.2021-2013
Valk, J., & Alumäe, T. (2021). VoxLingua107: A dataset for spoken language recognition. In Proceedings IEEE SLT Workshop.
van den Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., Kalchbrenner, N., Senior, A., Kavukcuoglu, K.(2016). WaveNet: A generative model for raw audio. In Proceedings 9th ISCA workshop on speech synthesis workshop (SSW 9), (p. 125).
Wagner, D., Bayerl, S. P., Maruri, H. C., & Bocklet, T. (2022). Generative models for improved naturalness intelligibility and voicing of whispered speech. In 2022 IEEE spoken language technology workshop (SLT), (pp. 943–948).
Yamamoto, R., Song, E., & Kim, J.-M.(2019). Probability density distillation with generative adversarial networks for high-quality parallel waveform generation. In Proceedings Interspeech 2019, (pp. 699–703). https://doi.org/10.21437/Interspeech.2019-1965
Yamamoto, R., Song, E., & Kim, J. (2020). Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram. In 2020 IEEE international conference on acoustics, speech and signal processing (ICASSP 2020), (pp. 6199–6203). https://doi.org/10.1109/ICASSP40776.2020.9053795
Yang, G., Yang, S., Liu, K., Fang, P., Chen, W., & Xie, L. (2021). Multi-band melgan: Faster waveform generation for high-quality text-to-speech. In 2021 IEEE spoken language technology workshop (SLT), (pp. 492–498). IEEE.
Yu, C., Lu, H., Hu, N., Yu, M., Weng, C., Xu, K., Liu, P., Tuo, D., Kang, S., Lei, G., Su, D., & Yu, D. (2020). DurIAN: Duration informed attention network for speech synthesis. In Proceedings Interspeech 2020, (pp. 2027–2031). https://doi.org/10.21437/Interspeech.2020-2968 .
Zeng, Z., Wang, J., Cheng, N., & Xiao, J. (2021). Lvcnet: Efficient condition-dependent modeling network for waveform generation. In 2021 IEEE international conference on acoustics, speech and signal processing (ICASSP 2021), (pp. 6054–6058). https://doi.org/10.1109/ICASSP39728.2021.9414710
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wagner, D., Baumann, I. & Bocklet, T. Generative adversarial networks for whispered to voiced speech conversion: a comparative study. Int J Speech Technol 27, 1093–1110 (2024). https://doi.org/10.1007/s10772-024-10161-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-024-10161-1