
Abstract
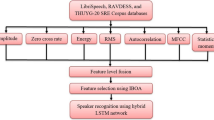
Text-independent speaker recognition is identifying speakers using their voice characteristics, irrespective of the content spoken. This research paper introduces a new method for this type of recognition by combining Mel-frequency cepstral coefficients (MFCCs), bidirectional long short-term memory (Bi-LSTM) networks, and feature optimization based on the Rat Swarm Optimizer (RSO). MFCCs are first extracted from speech signals as the primary feature set, capturing the vital acoustic features of the speaker's voice. To model temporal dependencies and improve speaker discrimination, a Bi-LSTM network is employed, which captures both forward and backward context in sequential data. The performance of the recognition system is further enhanced by optimizing the extracted features using the Rat Swarm Evolutionary Algorithm, a nature-inspired optimization technique that adapts the feature set to enhance accuracy. The outcomes of the research study on benchmark datasets demonstrate the usefulness of the proposed system, as it produces better results than traditional methods. The overall accuracy of speaker identification is 99.02% and the accuracies for gender recognition i.e, for male (96.72%) and female (96.91%) speakers, confirming the model's robustness across different speaker groups. The integration of Bi-LSTM with RSO feature optimization presents a robust and efficient solution for text-independent speaker recognition in real-world scenarios.










Similar content being viewed by others

Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.Data availability
No datasets were generated or analysed during the current study.
References
Ali, H., Tran, S. N., Benetos, E., & d’Avila Garcez, A. S. (2018). Speaker recognition with hybrid features from a deep belief network. Neural Computing and Applications, 29, 13–19.
Asha, T., & Murthy, H. A. (2014). The relevance of NIST speaker recognition evaluations. In 2014 International conference on signal processing and communications (SPCOM) (pp. 1–6). IEEE
Atiqul Islam, Md., Jassim, W. A., Cheok, N. S., & Zilany, M. S. A. (2016). A robust speaker identification system using the responses from a model of the auditory periphery. PloS One, 11(7), e0158520.
Campbell, J. P., Shen, W., Campbell, W. M., Schwartz, R., Bonastre, J.-F., & Matrouf, D. (2009). Forensic speaker recognition. IEEE Signal Processing Magazine, 26(2), 95–103.
Cristianini, N. (2000). An introduction to support vector machines and other kernel-based learning methods. Cambridge University Press.
Dhiman, G., Garg, M., Nagar, A., Kumar, V., & Dehghani, M. (2021). A novel algorithm for global optimization: Rat swarm optimizer. Journal of Ambient Intelligence and Humanized Computing, 12, 8457–8482.
Domingos, P. (2012). A few useful things to know about machine learning. Communications of the ACM, 55(10), 78–87.
Fong, S., Lan, K., & Wong, R. (2013). Classifying human voices by using hybrid SFX time-series preprocessing and ensemble feature selection. BioMed Research International, 2013(1), 720834.
Gomar, M. G. (2015). System and method for speaker recognition on mobile devices. U.S. Patent 9,042,867
Hmich, A., Badri, A., & Sahel, A. (2011). Automatic speaker identification by using the neural network. In 2011 International conference on multimedia computing and systems, (pp. 1–5). IEEE
Jahangir, R., Teh, Y. W., Memon, N. A., Mujtaba, G., Zareei, M., Ishtiaq, U., Akhtar, M. Z., & Ali, I. (2020). Text-independent speaker identification through feature fusion and deep neural network. IEEE Access, 8, 32187–32202.
Jahangir, R., Teh, Y. W., Nweke, H. F., Mujtaba, G., Al-Garadi, M. A., & Ali, I. (2021). Speaker identification through artificial intelligence techniques: A comprehensive review and research challenges. Expert Systems with Applications, 171, 114591.
Kabir, M. M., Mridha, M. F., Shin, J., Jahan, I., & Ohi, A. Q. (2021). A survey of speaker recognition: Fundamental theories, recognition methods and opportunities. IEEE Access, 9, 79236–79263.
Lim, J. S., & Oppenheim, A. V. (1979). Enhancement and bandwidth compression of noisy speech. Proceedings of the IEEE, 67(12), 1586–1604.
Ly-Van, B., Blouet, R., Renouard, S., Garcia-Salicetti, S., Dorizzi, B., & Chollet, G. (2003). Signature with text-dependent and text-independent speech for robust identity verification. In Workshop on multimodal user authentication.
Maurya, A., Kumar, D., & Agarwal, R. K. (2018). Speaker recognition for Hindi speech signal using MFCC-GMM approach. Procedia Computer Science, 125, 880–887.
Morrison, G. S., Sahito, F. H., Jardine, G., Djokic, D., Clavet, S., Berghs, S., & Dorny, C. G. (2016). INTERPOL survey of the use of speaker identification by law enforcement agencies. Forensic Science International, 263, 92–100.
Murty, K. S. R., & Yegnanarayana, B. (2005). Combining evidence from residual phase and MFCC features for speaker recognition. IEEE Signal Processing Letters, 13(1), 52–55.
Nweke, H. F., Teh, Y. W., Al-Garadi, M. A., & Alo, U. R. (2018). Deep learning algorithms for human activity recognition using mobile and wearable sensor networks: State of the art and research challenges. Expert Systems with Applications, 105, 233–261.
Panayotov, V., Chen, G., Povey, D., & Khudanpur, S. (2015). Librispeech: An asr corpus based on public domain audio books. In 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 5206–5210). IEEE
Prasad, S., Tan, Z.-H., & Prasad, R. (2017). Frame selection for robust speaker identification: A hybrid approach. Wireless Personal Communications, 97, 933–950.
Schmandt, C., & Arons, B. (1984). A conversational telephone messaging system. IEEE Transactions on Consumer Electronics CE–30(3), 21–24
Selva Nidhyananthan, S., Shantha Selva Kumari, R., & Senthur Selvi, T. (2016). Noise robust speaker identification using RASTA–MFCC feature with quadrilateral filter bank structure. Wireless Personal Communications, 91, 1321–1333.
Soleymanpour, M., & Marvi, H. (2017). Text-independent speaker identification based on selection of the most similar feature vectors. International Journal of Speech Technology, 20, 99–108.
Soong, F. K., Rosenberg, A. E., Juang, B.-H., & Rabiner, L. R. (1987). Report: A vector quantization approach to speaker recognition. AT&T Technical Journal, 66(2), 14–26.
Tiwari, M., & Verma, D. K. (2024). Enhanced text-independent speaker recognition using MFCC, Bi-LSTM, and CNN-based noise removal techniques. International Journal of Speech Technology, 27, 1013–1026. https://doi.org/10.1007/s10772-024-10150-4
Wang, W., Zhang, G., Luming Yang, V. S., Balaji, V. E., & Arunkumar, N. (2019). Revisiting signal processing with spectrogram analysis on EEG, ECG and speech signals. Future Generation Computer Systems, 98, 227–232.
Wu, Z., & Cao, Z. (2005). Improved MFCC-based feature for robust speaker identification. Tsinghua Science & Technology, 10(2), 158–161.
Funding
NA.
Author information
Authors and Affiliations
Contributions
Both authors equally contributed to the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Tiwari, M., Verma, D.K. Gender recognition in text-independent speaker identification using MFCC, spectrogram, Bi-LSTM, and rat swarm evolutionary algorithm optimization. Int J Speech Technol 28, 245–260 (2025). https://doi.org/10.1007/s10772-025-10176-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-025-10176-2