
Abstract
Stemming algorithms are crucial tools for enhancing the information retrieval process in natural language processing. This paper presents a novel Arabic light stemming algorithm called Tashaphyne0.4, the idea behind this algorithm is to extract the most precise ‘roots’, and ‘stems’ from words of an Arabic text. Thus, the proposed algorithm acts as rooter, stemmer, and segmentation tools at the same time. Our approach involves tri-fold phases (i.e., Preparation, Stems-Extractor, and Root-Extractor). Tashaphyne0.4 has shown better results than six other stemmers (i.e., Khoja, ISRI, Motaz/Light10, Tashaphyne0.3, FARASA, and Assem stemmers). The comparison is performed using four different Arabic comprehensive-benchmarks datasets. In conclusion, our proposed stemmer achieved remarkable results and outperformed other competitive stemmers in extracting ‘Roots’ and ‘Stems’.
Similar content being viewed by others



1 Introduction
Stemming algorithms or stemmers are crucial tools for enhancing information retrieval (IR) techniques. These stemmers work as preprocess to perform different tasks in natural language processing (NLP) (i.e., information retrieval, text summarization, topic modeling, sentiment analysis, morphology analysis, translation, categorization systems, etc...). Many Artificial Intelligence (AI) techniques have been produced to improve the information retrieval processes (Trotman, 2004; Alkhateeb et al., 2020; Al-Khatib et al., 2019).
Basically, the focal process of the stemming algorithm is to extract the roots and/or stems, by identifying and removing any affixes (prefixes and suffixes) from the input words. Several stemming algorithms exist for root/stem extraction in English (Porter, 1980; Lovins, 1968)), French (Savoy, 2006, 1993), and Arabic languages (Al-Sughaiyer & Al-Kharashi, 2004; Madani et al., 2018; Nahar et al., 2020c; Al-Khatib et al., 2021). In Respect to the Arabic language, Khoja-stemmer is considered the first well-known Arabic root-based stemmer (Khoja & Garside, 1999), which extracts the root from input Arabic words.
The process of Arabic stemmers can work in three different levels, namely, the stem-based algorithms to extract the stem, the root-based stemming algorithms to extract the root, and the lemmatization algorithms to extract the lemma. Figure 1 illustrates an example that describes the sequence of a stemming process for the input word “وبسواعدهما wbswā hmā [tr. and by their arms]”, which means “and with their two pair of forearms”. Firstly, the stem-based algorithm segments the word “وبسواعدهما wbswā
hmā [tr. and by their arms]”, which means “and with their two pair of forearms”. Firstly, the stem-based algorithm segments the word “وبسواعدهما wbswā hmā” (by removing the prefix “وبـ wb” and the suffix “هما hmā [tr. their in dual]”), to retrieve the stem word “سواعد swā
hmā” (by removing the prefix “وبـ wb” and the suffix “هما hmā [tr. their in dual]”), to retrieve the stem word “سواعد swā [tr. arms]”, which means “forearms”. Secondly, the root-based stemming algorithm extracts the root. As shown in Fig. 1, the three consonants root “سعد s
[tr. arms]”, which means “forearms”. Secondly, the root-based stemming algorithm extracts the root. As shown in Fig. 1, the three consonants root “سعد s [tr. root of arm equivalent]” with the pattern (“FEH”, “AIN”, “LAM” \(\rightarrow\) “ف f”, “ع
[tr. root of arm equivalent]” with the pattern (“FEH”, “AIN”, “LAM” \(\rightarrow\) “ف f”, “ع  ”, “ل l”) is extracted from the input stem “سواعد swā
”, “ل l”) is extracted from the input stem “سواعد swā [tr. arms]”.
[tr. arms]”.
Thirdly, in contrast to the stemming process which gives sometimes a nonsense word, the lemmatization process gives a sense word based on a dictionary. Certain lemmatization algorithms have been recently proposed to extract the “lemma” word (Bounhas et al., 2020; Soudani et al., 2019; Pasha et al., 2014). As shown in Fig. 1, the example is (“ساعد sā [tr. arm]”).
[tr. arm]”).
As shown in Fig. 1, the stem “سواعد swā [tr. arms]” from the given input word “وبسواعدهما wbswā
[tr. arms]” from the given input word “وبسواعدهما wbswā hmā [tr. and by their arms]”, is extracted after identifying and removing the prefix “وبـ wb” and the suffix “هما hmā [tr. their in dual]” through conducting the affixes segmentation process. Note that the stemming algorithms use lists of predefined prefixes/suffixes. Afterward, the stemming algorithm continues to extract the root “سعد s
hmā [tr. and by their arms]”, is extracted after identifying and removing the prefix “وبـ wb” and the suffix “هما hmā [tr. their in dual]” through conducting the affixes segmentation process. Note that the stemming algorithms use lists of predefined prefixes/suffixes. Afterward, the stemming algorithm continues to extract the root “سعد s [tr. root of arm equivalent]” in a root-extraction process, by selecting the pattern “فواعل fwā
[tr. root of arm equivalent]” in a root-extraction process, by selecting the pattern “فواعل fwā [tr. an Arabic pattern]” on the given stem “سواعد swā
[tr. an Arabic pattern]” on the given stem “سواعد swā [tr. arms]” from the previous segmentation stage.
[tr. arms]” from the previous segmentation stage.

An example extracting of (root, stem and lemma) from an Arabic word
In the remainder of this paper, Sect. 2 presents a detailed overview of related work for state-of-the-art light stemming algorithms and discusses the main drawbacks. The proposed stemmer with newly developed techniques is discussed in Sect. 3. The experimental evaluations and result discussions are analyzed in Sect. 4. Finally, the conclusion and possible future works are introduced in Sect. 5.
2 Related work
The stemming is a crucial basic task that is used in many natural language processing, especially on Information retrieval (IR) among usual issues such as spelling normalization and mapping, transliteration, tokenization, and stop words removal (Elayeb & Bounhas, 2016). In subsequent sections, we will illustrate and analyze the existing previous stemming algorithms in the literature Otair (2013), Migdady et al. (2022). Then, we will discuss the main drawbacks and limitations that are analyzed from the previous stemming algorithms in the literature.
2.1 Literature analysis
In Almazrua et al. (2020), the authors studied the impact of stemmers on microblog information retrieval. Then, in Bounhas et al. (2020) the authors examined the impact of Arabic morphology on the search process by experimenting with different indexing approaches. Thus, they showed that the IR system behavior and performance depend outstandingly on this parameter both for indexing and query expansion.
In Zeroual and Lakhouaja (2017), the researchers explained that stemming and lemmatization have been deployed to be beneficial in the areas of Arabic IR applications to save allocated space for Arabic content on the Internet, as well as allowing more efficient usage, indexing, searching, transmission speed, and retrieving information.
In fact, there is no general agreement about the representation level of Arabic words in IR systems. Historically, a root was the entry to traditional Arabic lexicons, where the majority of Arabic words are generated from roots. Further, the use of Arabic roots as indexing terms aims at reducing the size of data in order to accelerate the transmission process and reduce the storage size (Zeroual & Lakhouaja, 2017).
This method precision degrades the precision when the root is used as an indexing term. On the other hand, the stem-form suffers from under-semantic classification. So, the stem is grammatically the appropriate form regarding the context; while it may exclude many similar words sharing the same semantic properties (Zeroual & Lakhouaja, 2017; Nahar et al., 2020a; Rashaideh et al., 2020).
Consequently, the stemming algorithms can be categorized and divided into light and aggressive stemmers. First, the light stemmers prefer precision over recall and are likely to under-stem the words. In uncertain cases, the word is rather left intact instead of creating too short stem (for example, reducing the words مدرسون mdrswn [tr. teachers] and مدرسة mdrsh [tr. school] to مدرس mdrs [tr. teacher]). In the second, the aggressive stemmers work the other way round. Indisputable examples, their stemming is performed even at the risk of creating too short stem (over-stemming) (Brychcín & Konopík, 2015).
In this section, we are interested in stemming and rooting algorithms that are used in literature for IR tasks. For example, Khoja and Garside (1999) developed a root-based stemmer that extracts the root from input word, by removing prefixes/suffixes after applying the normalization process. Then, it matches the resulting word (i.e., stem) to the appropriate pattern, in order to extract the final root. Khoja-stemmerFootnote 1 initially defines a set of linguistic rules to resolve the ambiguity drawback in the stem-extraction step. Then, it uses the prefixes or suffixes length as the main features in the stemming process (Moral et al., 2014; Ra’ed et al., 2023). Afterward, the final decision of Khoja-stemmer is implicitly taken, based on the Arabic dictionary, while the final root will be the first correct root. Khoja-stemmer is considered the most popular Arabic stemmer (Khoja & Garside, 1999).
In Taghva et al. (2005), the authors presented another Arabic stemmer called Information Science Research Institute’s (ISRI),Footnote 2 which takes some advantages of Khoja-stemmer. However, ISRI-stemmer does not use dictionary steps. The main amendments over Khoja-stemmer were done by adding 60 more stop words, besides, the addition of the pattern “تفاعيل tfā l [tr. an Arabic pattern for irregular plurals]” to the set of patterns. Moreover, ISRI-stemmer returns the word after the normalizing process, if the ISRI algorithm could not find the final root. The popularity is obtained because ISRI-stemmer has been incorporated in Natural Language Toolkit (NLTK) (Algasaier, 2018; Taghva et al., 2005), which makes ISRI-stemmer is widely used in Arabic IR systems.
l [tr. an Arabic pattern for irregular plurals]” to the set of patterns. Moreover, ISRI-stemmer returns the word after the normalizing process, if the ISRI algorithm could not find the final root. The popularity is obtained because ISRI-stemmer has been incorporated in Natural Language Toolkit (NLTK) (Algasaier, 2018; Taghva et al., 2005), which makes ISRI-stemmer is widely used in Arabic IR systems.
In Larkey et al. (2007), the researchers introduced a heuristic light stemming algorithm called Light10-stemmer, which is the last version of series light stemmers (i.e., Light1, Light2, Light3, and Light8 are the previous versions). Light10 removes the prefixes/suffixes from input Arabic words without matching the set of patterns. Therefore, Light10 is particularly a very fast stemmer, as it removes the stop words, definite articles like (“الـ āl [tr. The]”), and the letter (“و w [tr. and]”), from the beginning of input words. From the end of the Arabic words, Light10-stemmer is only removing a small number of suffixes (Larkey et al., 2007). Standard TREC data is used to evaluate the effectiveness of Light10-stemmer. Light10-stemmer is widely utilized in the IR field, as it is integrated with the Lemur toolkit (Ogilvie & Callan, 2001). While Light10-stemmer is a fast stemmer and widely used in the field of IR, segmentation and text indexing, Light10-stemmer suffers from many limitations, however, it removes the affixes without applying linguistic rules and it cannot handle irregular plural for Arabic words. Light10-stemmer has been recently implemented using Apache Lucene software,Footnote 3 which is a recent update from light10-stemmer called (Motaz/Light10 stemmer). The main task of this modified Motaz/Light10-stemmer is to normalize the final output word after the process of removing prefixes/suffixes.
In Ghwanmeh et al. (2009), the authors introduced an enhanced root-based algorithm that handles the problems of affixes, including prefixes, suffixes, and infixes depending on the morphological pattern of the word. The stemming concept has been used to eliminate all kinds of affixes, including infixes. The results obtained showed that the algorithm extracts the correct roots with a high accuracy rate.
Zerrouki (2010) presented Tashaphyne, which was developed to be a light stemmer and segmentor at the same time in different updated versions (Tashaphyne and Tashaphyne0.3). Tashaphyne0.3 retrieves all possible segments from the input Arabic word. Therefore, Tashaphyne-stemmerFootnote 4 produces stems and roots together, while the other light stemmers (i.e., Khoja, ISRI, Assem, FARASA, and Light10), cannot introduce both stems and roots simultaneously. Tashaphyne is very flexible by allowing the end-users to customize and change the lists of prefixes/suffixes, without any changes in the original code. The latest version is called Tashaphyne 0.3.2 stemmer (Zerrouki, 2015), which is faster and the source code of Tashaphyne is freely available (Zerrouki, 2018). The recently released version of Tashaphyne-stemmer is officially published in the Python library to be directly installed by developers from Python Package Index (PyPI).Footnote 5
In Abdelali et al. (2016), the authors presented a linguistic-based stemming algorithm called FARASA-stemmer, which has a complete toolkit for Arabic text processing with advanced modules like; (segmentation, tokenization, lemmatization, POS tagger, diacritizer, and check-speller). FARASA-stemmer uses lexicons with a variety of features based on \(SVM_{rank}\) to rank the input text. Then, it produces the prefixes, stems, and suffixes segments as final outputs from the process of FARASA segmentation. FARASA-stemmerFootnote 6 is introduced as an online demo and open-source code (FARASA, 2018).
In Chelli (2018a), the researcher presented Assem Arabic light stemmer, in order to improve the search process in IR systems. Assem-stemmer can be integrated into many programming languages, because it is based on the snowball stemming algorithm (Chelli, 2018c). Assem-stemmer can extract the ‘stems’ as stemmer, and the ‘roots’ as rooter from the input text, but in two separate packages. Provided that the snowball-based framework does not provide the Assem-stemmer and Assem-rooter together at the same time. The source code of Assem-stemmer is freely availableFootnote 7 and there is an online demo on it.Footnote 8
QCRI Advanced Tools for ARAbic (QATARA)Footnote 9 is a statistical tokenizer, with part of speech. It also gives the named entities, and extracts the gender, and the number tagger. It was trained based on Conditional Random Fields (CRF++). This CRF model was developed for segmenting/labeling data in order to be used in some other NLP processes (Darwish, 2015).
There are many other works on stemming and root extraction, which present other metrics and advantages, listed on the Dahab et al. (2015) and Almazrua et al. (2020) review. Therefore, we select the most popular and recent stemming algorithms to evaluate our proposed Tashaphyne0.4 light stemming algorithm.
The stemming for the Arabic language is still a challenging task, as a result, many methods have been proposed to introduce the more powerful stemming algorithms that can be used on various tasks. In this section, we presented the main state-of-the-art Arabic stemming algorithms. Table 1 shows the summary as the main criticize for the previous stemmers.
2.2 Literature discussion
Arabic language as one of the Semitic languages, is written and read from right to left. Arabic is an agglutinative language, where the stem is concatenated with prefixes/suffixes to form up one word called newly derived word (Habash, 2010; Orăsan et al., 2017). However, at the morphology level, Arabic is a non-agglutinative language, because the process of deriving a new word from the root follows pattern-rules with adding some infixes in the middle, too. Therefore, the new derived word is not only a concatenation of prefixes/suffixes to the stem, but also there are some infixes added inside the word structure. These infixes make the root extraction process much more difficult. Consequently, the Arabic stemming algorithms still suffer from many issues and drawbacks, which affect the extraction of the most precise stems and/or roots. Such drawbacks are considered main limitations, which are investigated by the authors with a deep analysis process of studying state-of-the-art Arabic light stemming algorithms in the previous subsection (i.e., 2.1 Literature Analysis). These main drawbacks can be explained as follows:
-
Ambiguity stem-extraction: Semantically speaking, some derived Arabic words may refer to many different meanings in the same morphological structure. This issue leads to extracting many stems and roots. For example, the word “والدين wāldyn” can lead to three different meanings according to the following clauses. i) In the sentence “انهم والدين فقيرين ānhm wāldyn fqyryn”, the word “والدين wāldyn” means (‘parents, both father and mother’). So, the correct stemming should be “والد+ين+ +wāld+yn\(\phi\)”. This will lead to producing the stem “والد wāld” (means ‘father’), and then to extract the root “ولد wld” (means ‘son’). ii) In the sentence “الدفع نقداً والدين ممنوع āldf
 nqdāan wāldyn mmnw
nqdāan wāldyn mmnw ”, the word “والدين wāldyn” here means (‘and the debt’). Thus, the correct stemming should be “\(\phi\)+وال+دين wāl+dyn+”, which implies to extract the “دين dyn” as stem, and the root is “دين dyn” (means ‘debt’). iii) In the sentence “الهدى والدين المستقيم ālhdā wāldyn ālmstqym”, the word “والدين wāldyn” means (‘and the religion’). Therefore, the correct stem is “\(\phi\) +وال+دين wāl+dyn+ ”, which leads to extract the stem “دين dyn” (means ‘religion’), and the “دين dyn” as root, too.
”, the word “والدين wāldyn” here means (‘and the debt’). Thus, the correct stemming should be “\(\phi\)+وال+دين wāl+dyn+”, which implies to extract the “دين dyn” as stem, and the root is “دين dyn” (means ‘debt’). iii) In the sentence “الهدى والدين المستقيم ālhdā wāldyn ālmstqym”, the word “والدين wāldyn” means (‘and the religion’). Therefore, the correct stem is “\(\phi\) +وال+دين wāl+dyn+ ”, which leads to extract the stem “دين dyn” (means ‘religion’), and the “دين dyn” as root, too. -
Incorrect affixes removal: In some cases, the extracted stems are not segmented correctly, due to ill-removing the prefixes or suffixes. Firstly, some Arabic words are starting with substring listed in the predefined group of prefixes. So, the stemmers will ill-form and remove incorrectly the extracted stem. For example, the word “والده wāldh” (means ‘his father’), will be segmented to “وال+د+ه wāl+d+h” by removing the “وال wāl” as a prefix. But, the prefix “وال wāl” is part of the correct stem “والد wāld” (means ‘father’). Secondly, some Arabic words end with substring listed in the predefined group of suffixes. So, the stemmers will incorrectly remove this suffix, while it is part of the correct stem. For example, the word “الدين āldyn” with the meaning “the debt”, will be segmented to “ال+د+ين āl+d+yn” by removing the “ين yn” as a suffix. However, this removed suffix “ين yn”, should be part of the original stem “دين dyn” that means “debt”.
-
Removing letters from the original stem: After removing the prefix/suffix from the input Arabic word, the stem is extracted incorrectly, due to removing some letters from the original stem during morphology flexion (like; “ويستعملهم, يندرجون، ينتقي، يقترب، يغتر wyst
 lhm, yndrǧwn, yntqy, yqtrb, yġtr [tr. uses them, they fall, pick, approach, deceive]”). For example, the morphological structure of the Arabic word “ويستعملهم wyst
lhm, yndrǧwn, yntqy, yqtrb, yġtr [tr. uses them, they fall, pick, approach, deceive]”). For example, the morphological structure of the Arabic word “ويستعملهم wyst lhm [tr. and he uses them]” is originally derived from the stem “استعمل āst
lhm [tr. and he uses them]” is originally derived from the stem “استعمل āst l [tr. to use]” and the root “عمل
l [tr. to use]” and the root “عمل  l [tr. the root of use]”. However, this word “ويستعملهم wyst
l [tr. the root of use]”. However, this word “ويستعملهم wyst lhm [tr. and he uses them]” is segmented to be “ويـ+ستعمل+ـهم wy+st
lhm [tr. and he uses them]” is segmented to be “ويـ+ستعمل+ـهم wy+st l+hm”, and then the extracted stem will be “ستعمل st
l+hm”, and then the extracted stem will be “ستعمل st l”. Thus, the extracted stem “ستعمل st
l”. Thus, the extracted stem “ستعمل st l” is incorrect, due to removing the letter “ا ā” from the original stem “استعمل āst
l” is incorrect, due to removing the letter “ا ā” from the original stem “استعمل āst l [tr. to use]” during the process of building the morphological structure of the input word “ويستعملهم wyst
l [tr. to use]” during the process of building the morphological structure of the input word “ويستعملهم wyst lhm”. Therefore, the original stem should be “استعمل āst
lhm”. Therefore, the original stem should be “استعمل āst l” instead of the ill-formed one “ستعمل st
l” instead of the ill-formed one “ستعمل st l”.
l”.
 nqdāan wāldyn mmnw
nqdāan wāldyn mmnw ”, the word “والدين wāldyn” here means (‘and the debt’). Thus, the correct stemming should be “
”, the word “والدين wāldyn” here means (‘and the debt’). Thus, the correct stemming should be “ lhm, yndrǧwn, yntqy, yqtrb, yġtr [tr. uses them, they fall, pick, approach, deceive]”). For example, the morphological structure of the Arabic word “ويستعملهم wyst
lhm, yndrǧwn, yntqy, yqtrb, yġtr [tr. uses them, they fall, pick, approach, deceive]”). For example, the morphological structure of the Arabic word “ويستعملهم wyst lhm [tr. and he uses them]” is originally derived from the stem “استعمل āst
lhm [tr. and he uses them]” is originally derived from the stem “استعمل āst l [tr. to use]” and the root “عمل
l [tr. to use]” and the root “عمل  l [tr. the root of use]”. However, this word “ويستعملهم wyst
l [tr. the root of use]”. However, this word “ويستعملهم wyst lhm [tr. and he uses them]” is segmented to be “ويـ+ستعمل+ـهم wy+st
lhm [tr. and he uses them]” is segmented to be “ويـ+ستعمل+ـهم wy+st l+hm”, and then the extracted stem will be “ستعمل st
l+hm”, and then the extracted stem will be “ستعمل st l”. Thus, the extracted stem “ستعمل st
l”. Thus, the extracted stem “ستعمل st l” is incorrect, due to removing the letter “ا ā” from the original stem “استعمل āst
l” is incorrect, due to removing the letter “ا ā” from the original stem “استعمل āst l [tr. to use]” during the process of building the morphological structure of the input word “ويستعملهم wyst
l [tr. to use]” during the process of building the morphological structure of the input word “ويستعملهم wyst lhm”. Therefore, the original stem should be “استعمل āst
lhm”. Therefore, the original stem should be “استعمل āst l” instead of the ill-formed one “ستعمل st
l” instead of the ill-formed one “ستعمل st l”.
l”.As a result, many challenges require more powerful light stemming algorithms that can handle all these drawbacks together. For example, Khoja-stemmer (Khoja & Garside, 1999) gives roots only, when it fails to stem words like: “ استنتجنه, استنتجوه, استنتجوها, تطلبوهم, اطلبوهم, يطلبوهم, كمطلبهن āstntǧnh, āstntǧwh, āstntǧwhā, tṭlbwhm, āṭlbwhm, yṭlbwhm, kmṭlbhn”, it returns the sames words. FARASA-stemmer (Abdelali et al., 2016) returns stems, but it fails on removing some affixes like near future affixes “زوائد المضارع القريب zwā d ālm ḍ ā
d ālm ḍ ā ālqryb”. FARASA-stemmer segments following words “سأطلب, سيطلب, سنطلب s
ālqryb”. FARASA-stemmer segments following words “سأطلب, سيطلب, سنطلب s ṭlb, sy ṭlb, sn ṭlb” into “س+أطلب, س+يطلب, س+نطلب s+
ṭlb, sy ṭlb, sn ṭlb” into “س+أطلب, س+يطلب, س+نطلب s+ ṭlb, s+y ṭlb, s+n ṭlb”. Therefore, FARASA-stemmer returns the same words without removing any affixes form words like: “باختصاراتك, باختصاراتكم, باختصاراتكما, باختصاراتكن bā
ṭlb, s+y ṭlb, s+n ṭlb”. Therefore, FARASA-stemmer returns the same words without removing any affixes form words like: “باختصاراتك, باختصاراتكم, باختصاراتكما, باختصاراتكن bā t ṣārātk, bā
t ṣārātk, bā t ṣārātkm, bā
t ṣārātkm, bā t ṣārātkmā, bā
t ṣārātkmā, bā t ṣārātkn”. FARASA-stemmer fails also on the ‘Feh’ affix in some cases like: “فالطالبتين fāl ṭālbtyn”, which gives “ف+ال+طالبتين f+āl+ ṭālbtyn”. Motaz/Light10-stemmer (Saad & Ashour, 2010) returns stems, but it fails in some cases, like:
t ṣārātkn”. FARASA-stemmer fails also on the ‘Feh’ affix in some cases like: “فالطالبتين fāl ṭālbtyn”, which gives “ف+ال+طالبتين f+āl+ ṭālbtyn”. Motaz/Light10-stemmer (Saad & Ashour, 2010) returns stems, but it fails in some cases, like:
“استنتاجاتك, استنتاجاتكم, استنتاجاتكما, استنتاجاتكن, استنتاجاتنا, استنتاجاتهم, استنتاجاتهما, استنتاجاتهن, استنتاجاتي āstntāǧātk, āstntāǧātkm, āstntāǧātkmā, āstntāǧātkn, āstntāǧātknā, āstntāǧāthm, āstntāǧāthmā, āstntāǧāthn, āstntāǧāty”.
So, Motaz/Light10-stemmer returns the same words as stems, and it fails on removing some affixes like near future affixes “زوائد المضارع القريب zwā d ālm ḍār
d ālm ḍār ālqryb”. Also, it does not remove affixes from following words “سأطلب, سيطلب, سنطلب s
ālqryb”. Also, it does not remove affixes from following words “سأطلب, سيطلب, سنطلب s ṭlb, sy ṭlb, sn ṭlb”. ISRI-stemmer (Taghva et al., 2005) returns the same words for some cases like:
ṭlb, sy ṭlb, sn ṭlb”. ISRI-stemmer (Taghva et al., 2005) returns the same words for some cases like:
“باختصاراتكن, باختصاراتنا, باختصاراته, باختصاراتها, باختصاراتهم, باختصاراتهما, باختصاراتهن, باختصاراتي, باختصارك, كمطلبهن, فالمطلوب, bā tṣārātkn, bā
tṣārātkn, bā tṣārātnā, bā
tṣārātnā, bā tṣārāth, bā
tṣārāth, bā tṣārāthā, bā
tṣārāthā, bā tṣvrāthm, bā
tṣvrāthm, bā tṣārāthmā, bā
tṣārāthmā, bā tṣārāthn, bā
tṣārāthn, bā tṣārāty, bā
tṣārāty, bā tṣārk, km ṭlbhn, fālmṭlwb,”.
tṣārk, km ṭlbhn, fālmṭlwb,”.
ARLStem stemmer (Abainia et al., 2017) fails on some cases like “استنتاجاتكن, استنتاجاتهن, استنتاجاتي āstntāǧātkn, āstntāǧāthn, āstntāǧāty” by returning “ستنتاجاتك, ستنتاجاته, ستنتاجات stntāǧātk, stntāǧāth, stntāǧāt” as stems. Also, ARLStem stemmer does not remove near future affixes “زوائد المضارع القريب zwā d ālmḍār
d ālmḍār ālqryb” in words like “سأطلبن, سنطلبن s
ālqryb” in words like “سأطلبن, سنطلبن s ṭlbn, snṭlbn”. And it fails on removing ‘Feh’ affix in some cases like “فالطالب, فالطالبين, فالطالبون, فالطلاب fālṭālb, fālṭālbyn, fālṭālbwn, fāltṭāb”. Assem-stemmer (Chelli, 2018a) surpasses previous stemmers cited in given test cases, but it presents some failures on cases in Future tense. So, Assem-stemmer segments words likes “سيطلب, سنطلب, تطلبه, اطلبه, نطلبه syṭlb, snṭlb, tṭlbh, āṭlbh, nṭlbh” into “س+يطلب, س+نطلب, تطلب+ه, اطلب+ه, نطلب+ه s+y ṭlb, s+n ṭlb, tṭlb+h, ā ṭlb+h, n ṭlb+h”. Therefore, it fails in extracting “Hamza+Alef” prefix from some cases like “أفبالباطل, أفحسبتم, أفحسب, أفحكم
ṭlbn, snṭlbn”. And it fails on removing ‘Feh’ affix in some cases like “فالطالب, فالطالبين, فالطالبون, فالطلاب fālṭālb, fālṭālbyn, fālṭālbwn, fāltṭāb”. Assem-stemmer (Chelli, 2018a) surpasses previous stemmers cited in given test cases, but it presents some failures on cases in Future tense. So, Assem-stemmer segments words likes “سيطلب, سنطلب, تطلبه, اطلبه, نطلبه syṭlb, snṭlb, tṭlbh, āṭlbh, nṭlbh” into “س+يطلب, س+نطلب, تطلب+ه, اطلب+ه, نطلب+ه s+y ṭlb, s+n ṭlb, tṭlb+h, ā ṭlb+h, n ṭlb+h”. Therefore, it fails in extracting “Hamza+Alef” prefix from some cases like “أفبالباطل, أفحسبتم, أفحسب, أفحكم  fbālbā ṭl,
fbālbā ṭl, f ḥsbtm,
f ḥsbtm, f ḥsb,
f ḥsb, f ḥkm”.
f ḥkm”.
Therefore in this research study, a new light stemming algorithm called Tashaphyne0.4, is proposed to handle such kinds of drawbacks. Our proposed algorithm can be considered as a novel efficient light stemmer, due to its robustness in extracting the roots and stems from input Arabic words (Al-Khatib et al., 2023). Provided that, Tashaphyne0.4 stemmer can be easily used to support the IR systems, text indexing, and classifiers in data mining, throughout the processing of three main phases. The first phase is a “Preparation Phase”, which divides the Arabic text into words using a tokenization process. The second phase is the “Stem-Extractor Phase”, which uses a modified Finite State Automaton (FSA) technique as a segmentor, to extract the initial stem by removing affixes (prefixes and suffixes) from the input Arabic word. Finally, in the “Root-Extractor Phase”; a new operator called “Rhyzome” has been developed, to filter and extract the most precise root for the input.
In order to validate our proposed stemmer accuracy, four different datasets are used as dedicated Arabic corpora. For comparison purposes, the obtained results from our proposed Tashaphyne0.4 stemmer are compared with outputs given by other popular Arabic light stemmers (i.e., Khoja, ISRI, Light10, Tashaphyne0.3, FARASA, and Assem), using the same four datasets. As a consequence, our proposed light stemmer outperforms other comparative Arabic stemmers in almost all corpora used.
3 Proposed method
In this section, the proposed Tashaphyne Arabic light stemmer (Tashaphyne0.4), is discussed in detail. The primary goal of proposing this light stemming algorithm, is to extract the final correct root and stem using an efficient light stemming algorithm in minimal execution time. As shown in Fig. 2, Tashaphyne0.4 involves three main phases (Preparation, Stems-Extractor, and Root-Extractor phases), which will be thoroughly discussed in the following subsections.

General workflow for proposed Tashaphyne0.4 Arabic light stemming algorithm
3.1 Phase 1: preparation
The main goal of the preparation phase is to handle the initial input, to get it ready for the next stemming operations. The preparation phase involves two main steps: i) Tokenization operator with diacritics-remover. ii) Customizing suffixes and prefixes lists.
In the first step, a process of preparation is implemented to split the input into a series of tokens, by running a tokenization operator. Therefore, for the stemming issue, each input can be represented as an initial input text \({T= }(w_1, w_2, \ldots ,w_c)\) of c words. Then, this particular text is tokenized using a special function called \(F_{tokenizer}({T})\), which is formulated in Eq. (1) as follows:
where each word is indexed by \(w_i\), which refers to the labeled words of value range \(\Rightarrow\) \(w_i \in (1,2,\ldots ,c)\). Given that the input total number of words equals c words. A diacritics-removal function is then invoked to remove diacritics from input Arabic words. Consequently, this series of words will be ready for further process.
On the other side, suffixes and prefixes list are also considered in the second step of this preparation phase. However, this particular step is customized without any changes in the original code. We can claim that, such customization of the lists of suffixes and prefixes is considered a distinguishing feature in our approach (Zerrouki, 2010). Actually, the lists of affixes (i.e., prefixes/suffixes) are organized and categorized into six different groups of lists. Table 2, shows some examples of these lists that are categorized as follows:
-
1)
Verb prefixes list: These prefixes are only added to the beginning of verbs.
-
2)
Noun prefixes list: These prefixes are only added to the beginning of nouns, but not added to the beginning of verbs.
-
3)
Stemming prefixes list: These prefixes can be added to the beginning of nouns and/or to the beginning of verbs.
-
4)
Verb suffixes list: These suffixes are only added to the end of verbs.
-
5)
Noun suffixes list: These suffixes are only added to the end of nouns, but not at the end of verbs.
-
6)
Stemming suffixes list: These suffixes can be added to the end of nouns and/or to the end of verbs.
As a consequence, the main reason behind this lists is to make the entire process of our proposed approach more efficient. The algorithm of our proposed stemmer will be provided for the researchers freely online. For flexibility issues, the developers have the right to customize, update, and delete any of these affixes, without having to change the source code of the proposed algorithm.
3.2 Phase 2: stems-extractor
In this phase, the stemmer extracts numerous stems from the input word by removing any affixes added. Meanwhile, these input words are automatically manipulated and loaded from the previous phase (i.e, Preparation-phase). As an initial step, we developed a new technique called Modified Finite-State Automaton (Modified-FSA), in order to search for the stream of characters that represents the correct added affixes in the word. We developed this Modified-FSA technique based on finite automata algorithms that have been presented initially by Watson (1993). However, many researchers have adopted and developed the Finite-State Automata (FSA) technique, to be used in many applications and various aspects of NLP systems (Kawaguchi et al., 1991; Aubry & Brinzei, 2015; Daciuk, 2016).
3.2.1 Modified-FSA
Our proposed stemmer identifies and removes the affixes based on Modified-FSA. Fundamentally, the Modified-FSA technique has been developed to retrieve all possible affixes from the input word. To illustrate this issue, let us consider the input word “وبالـمدرسة wbālmdrsh [tr. and by the school]” or “والـمدرسة wālmdrsh [tr. and the school]”, however, a part of the predefined prefixes list is as follows: { “و w”, “وال \(w{\bar{a}}l\)”, “والم \(w{\bar{a}}lm\)”, “وب wb”, “وبال \(wb{\bar{a}}l\)”, and “وبالم \(wb{\bar{a}}lm\)” }. The tree of this prefixes list can be represented in Fig. 3a, which is built based on a directed acyclic graph.
The traditional behavior of the FSA technique is to stop when finding the ending position, where the new modified FSA marks the end position and extracts the current affix, then continues to lookup for other affixes extension. For example, if the word is بالولد \(b{\bar{a}}lwld\) [tr. by the boy], it marks ب b [tr. a]s a prefix, then continues to find the longest prefix بال \(b{\bar{a}}l\) [tr..]
Practically, Fig. 3b refers to the sequence of prefix extraction, based on Modified-FSA technique, either for the input word “‘والـمدرسة \(w{\bar{a}}lmdrsh\) [tr. and the school]” [on left hand-side of Fig. 3b], or for the word “وبالـمدرسة \(wb{\bar{a}}lmdrsh\) [tr. and by the school]” [on right hand-side of Fig. 3b]. Eventually, proposed algorithm extracts the longest prefix as the default one. The examples in Fig. 3 illustrates this, therefore, the “والم \(w{\bar{a}}lm\)” will be removed, since it is the longest extracted prefix from “والـمدرسة \(w{\bar{a}}lmdrsh\)”, and “وبالم \(wb{\bar{a}}lm\)” is also the longest extracted prefix from “وبالـمدرسة \(wb{\bar{a}}lmdrsh\)”, so, it will also be removed.

Performing of Modified-FSA technique on the prefixes extraction process
In parallel, another Modified-FSA procedure runs in reverse, to extract all possible suffixes. For example, the predefined suffixes list for the word “يستعملونها yst \(lwnh{\bar{a}}\) [tr. they use it]” or “يستعملوها yst
\(lwnh{\bar{a}}\) [tr. they use it]” or “يستعملوها yst \(lwh{\bar{a}}\) [tr. they use it (in the subjunctive present)]”, is as follows: { “ا \({\bar{a}}\)”, and “يها \(yh{\bar{a}}\)”, “ها \(h{\bar{a}}\)”, “ونها \(wnh{\bar{a}}\)”, “وها \(wh{\bar{a}}\)”, }. as illustrated in Fig. 4b. Therefore, the longest extracted suffix, (i.e, “ونها \(wnh{\bar{a}}\)” for the word “يستعملونها yst
\(lwh{\bar{a}}\) [tr. they use it (in the subjunctive present)]”, is as follows: { “ا \({\bar{a}}\)”, and “يها \(yh{\bar{a}}\)”, “ها \(h{\bar{a}}\)”, “ونها \(wnh{\bar{a}}\)”, “وها \(wh{\bar{a}}\)”, }. as illustrated in Fig. 4b. Therefore, the longest extracted suffix, (i.e, “ونها \(wnh{\bar{a}}\)” for the word “يستعملونها yst \(lwnh{\bar{a}}\)”, and “وها \(wh{\bar{a}}\)” for the other word “يستعملوها yst
\(lwnh{\bar{a}}\)”, and “وها \(wh{\bar{a}}\)” for the other word “يستعملوها yst \(lwh{\bar{a}}\)”), will be removed to extract the targeted ‘stem’ from these two words.
\(lwh{\bar{a}}\)”), will be removed to extract the targeted ‘stem’ from these two words.

Performing of Modified-FSA technique in an inverse way for suffixes extraction process
3.2.2 Selection schema for final-stem
In this step, Modified-FSA techniques will be invoked to segment the input words into all possible stems, please refer to Table 3 that shows all possible segments for the word “فسيستعملونهما fsyst \(lwnhm{\bar{a}}\) [tr. and they will use them]”. However, to get a stem from all possible segments, the longest prefix/suffix is removed. Therefore, the first default stem is the shortest one that is extracted based on the Modified-FSA techniques.
\(lwnhm{\bar{a}}\) [tr. and they will use them]”. However, to get a stem from all possible segments, the longest prefix/suffix is removed. Therefore, the first default stem is the shortest one that is extracted based on the Modified-FSA techniques.
 \(lwnhm{\bar{a}}\) [tr. and they will use them]” using and applying the two developed Modified-FSA techniques
\(lwnhm{\bar{a}}\) [tr. and they will use them]” using and applying the two developed Modified-FSA techniquesMoreover, the verification process is conducted for the removed prefixes/suffixes according to the affixes lists that are explained in Sect. 3.1, and categorized in Table 2. To illustrate this process, please consider the words “‘الـمعلمات \(\bar{a}lm\) \(m{\bar{a}}t\) [tr. the feminine teachers]”, “العاملات \({\bar{a}}l\)
\(m{\bar{a}}t\) [tr. the feminine teachers]”, “العاملات \({\bar{a}}l\) \(ml{\bar{a}}t\) [tr. the feminine workers]”, or “الـمستعملات \({\bar{a}}lmst\)
\(ml{\bar{a}}t\) [tr. the feminine workers]”, or “الـمستعملات \({\bar{a}}lmst\) \(l{\bar{a}}t\) [tr. the feminine users]”, therefore, the prefix “ال \({\bar{a}}l\)” matches the suffix “ات \({\bar{a}}t\)”. But, the prefix “ال āl” does not match the suffix “هم hm” for such noun-words. Afterward, all mismatch affixes are removed to extract several candidate-stems. These candidate-stems will be used later to extract the final root (i.e., Root-Extractor phase). Further procedures are implemented (i.e., normalizing and filtering) to extract the final ‘stem’ as follows.
\(l{\bar{a}}t\) [tr. the feminine users]”, therefore, the prefix “ال \({\bar{a}}l\)” matches the suffix “ات \({\bar{a}}t\)”. But, the prefix “ال āl” does not match the suffix “هم hm” for such noun-words. Afterward, all mismatch affixes are removed to extract several candidate-stems. These candidate-stems will be used later to extract the final root (i.e., Root-Extractor phase). Further procedures are implemented (i.e., normalizing and filtering) to extract the final ‘stem’ as follows.
3.2.3 Normalisation and filtering procedure
After deep normalization analysis to some Arabic stemmers like Assem and FARASA, we can claim that FARASA performed letter normalization, where authors conflated: In FARASA stemmer (Abdelali et al., 2016), variants of “alef”, “ta marbouta” and “ha”, “alef maqsoura” and “ya”, and the different forms of “hamza”. While Assem-stemmer (Chelli, 2018a), converts any ‘Hamza’ letter to the nearer pronounced letter, like ‘Hamza’ ‘ئـ  ’ letter in the word ‘بئر b
’ letter in the word ‘بئر b r [tr. a well]’, will be converted to ‘بير byr’, and so on. The main issue facing the normalizing process is that; there are some words, will be improperly converted and normalized. Therefore, it is a demanding issue to propose a new robust normalizing process that tackles all of these issues. Consequently, we proposed a new normalizing process with the following distinguished features:
r [tr. a well]’, will be converted to ‘بير byr’, and so on. The main issue facing the normalizing process is that; there are some words, will be improperly converted and normalized. Therefore, it is a demanding issue to propose a new robust normalizing process that tackles all of these issues. Consequently, we proposed a new normalizing process with the following distinguished features:
-
1)
Normalisation of ‘Hamza’s’ letters: This function aims to normalise the following three ‘Hamza’s’ [“ؤ
 ”, “ىء
”, “ىء  ”, and “ء
”, and “ء  ”], to be in “ء
”], to be in “ء  ” form.
” form. -
2)
Normalisation of the ‘Alef with hamza’: It normalizes the original letter ‘Alef with hamza’ from “أ
 ” form, to be also in “ء
” form, to be also in “ء  ” form. For example, the original letter ‘Alef with hamza’ at the beginning of input stem like in “أكل
” form. For example, the original letter ‘Alef with hamza’ at the beginning of input stem like in “أكل  kl [tr. to eat]”, will be normalized to “ءكل
kl [tr. to eat]”, will be normalized to “ءكل  l” form. Moreover, the original letter ‘Alef with hamza’ at the middle like in “سأل s
l” form. Moreover, the original letter ‘Alef with hamza’ at the middle like in “سأل s l [tr. to ask]”, will be normalized to “سءلs
l [tr. to ask]”, will be normalized to “سءلs ” form.
” form. -
3)
Normalizing extra the ‘Alef with hamza’: Finally, it normalizes the extra letter ‘Alef with hamza’ from “أ
 ” form, to be ‘Alef without hamza’ in “ا \({\bar{a}}\)” form. For example, the extra letter ‘Alef with hamza’ at the beginning of input stem like in “أفعال
” form, to be ‘Alef without hamza’ in “ا \({\bar{a}}\)” form. For example, the extra letter ‘Alef with hamza’ at the beginning of input stem like in “أفعال  f
f l [tr. verbs]”, will be normalized to “افعال \({\bar{a}}f\)
l [tr. verbs]”, will be normalized to “افعال \({\bar{a}}f\) l” form. Also, the extra letter ‘Alef with hamza’ at the beginning of input stem “أسـماء
l” form. Also, the extra letter ‘Alef with hamza’ at the beginning of input stem “أسـماء  \(sm{\bar{a}}\)
\(sm{\bar{a}}\) [tr. nouns]”, will be normalized to “اسـماء \({\bar{a}}sm{\bar{a}}\)
[tr. nouns]”, will be normalized to “اسـماء \({\bar{a}}sm{\bar{a}}\) ” form.
” form.
 ”, “ىء
”, “ىء  ”, and “ء
”, and “ء  ”], to be in “ء
”], to be in “ء  ” form.
” form. ” form, to be also in “ء
” form, to be also in “ء  ” form. For example, the original letter ‘Alef with hamza’ at the beginning of input stem like in “أكل
” form. For example, the original letter ‘Alef with hamza’ at the beginning of input stem like in “أكل  kl [tr. to eat]”, will be normalized to “ءكل
kl [tr. to eat]”, will be normalized to “ءكل  l” form. Moreover, the original letter ‘Alef with hamza’ at the middle like in “سأل s
l” form. Moreover, the original letter ‘Alef with hamza’ at the middle like in “سأل s l [tr. to ask]”, will be normalized to “سءلs
l [tr. to ask]”, will be normalized to “سءلs ” form.
” form. ” form, to be ‘Alef without hamza’ in “ا
” form, to be ‘Alef without hamza’ in “ا  f
f l [tr. verbs]”, will be normalized to “افعال
l [tr. verbs]”, will be normalized to “افعال  l” form. Also, the extra letter ‘Alef with hamza’ at the beginning of input stem “أسـماء
l” form. Also, the extra letter ‘Alef with hamza’ at the beginning of input stem “أسـماء 
 [tr. nouns]”, will be normalized to “اسـماء
[tr. nouns]”, will be normalized to “اسـماء  ” form.
” form.In the meantime, the crucial step is to decide whether ‘Alef with hamza’ is original or extra, given that, they are both written in the same form. As a result, we consider the ‘Alef with hamza’ at the beginning of the stem as an extra letter; whereas, the ‘Alef with hamza’ at the middle or end of the stem, as an original letter.
For selecting the best stem, a filtering process is performed to extract the shortest stem from all candidate-stems. Furthermore, these extracted candidate-stems from this phase will the inputs for the next phase of our proposed stemmer to extract the final root. Therefore, all extracted and normalized candidate-stems will be the main inputs to the next phase, in order to extract the final and the best final root.
3.3 Phase 3: root-extractor
In this phase, our proposed algorithm extracts the final correct ‘root’ using the input ‘stems’ that are normalised and extracted in the previous phase (i.e., Stems-Extractor). The main focus of this Root-Extractor phase is on the way of extracting the final root, which is based on proposing and developing a new operator called Rhyzome operator, see the lower part of Fig. 2 for mapping the general workflow of this phase.
Consequently, we developed the new Rhyzome operator, in order to treat any errors found in the input ‘stems’. The Rhyzome operator starts by giving an output called ‘Candidate-Roots’. Then, the ‘Best-Selector’ function is invoked to extract the final correct root called (\({Root }_{final}\)). The process of how this operator work, is illustrated in Algorithm 1. Algorithm 1 shows how this operator contributes to extracting a set of Candidate-Roots, and then to extract the most precise final ‘root’ from these input stems. Thereafter, the entire process of the proposed operator is thoroughly discussed in the following subsections.

Pseudo-code of the Root-Extractor phase()
3.3.1 Rhyzome operator
Rhyzome Operator in the meanwhile, receives the stems from the previous phase, in order to form up a set of Candidate-roots. After removing all prefixes/suffixes; the stems become sometimes short patterns (Al-Kabi et al., 2015), because of improper deleting of one letter from the original root, during the previous phase. Thus, some stems may be segmented without covering whole pattern letters (i.e. ‘FEH’, ‘AIN’, ‘LAM’ \(\rightarrow\) “ف f”, “ع  ”, “ل l”). It is worth stressing some examples of improperly segmented stems.:
”, “ل l”). It is worth stressing some examples of improperly segmented stems.:
-
i)
The extracted stem for the word “خذهم
 \(\underline{d}hm\) [tr. take them]”, is “خذ
\(\underline{d}hm\) [tr. take them]”, is “خذ  \(\underline{d}\) [tr. take]” which means ‘take’, where it should be “ءخذ
\(\underline{d}\) [tr. take]” which means ‘take’, where it should be “ءخذ  \(\underline{d}\)”: So “خذ
\(\underline{d}\)”: So “خذ  \(\underline{d}\)” comes with short pattern “؟ـعل ?
\(\underline{d}\)” comes with short pattern “؟ـعل ? ” after removing ‘FEH’, “ف f” from the beginning of the full pattern.
” after removing ‘FEH’, “ف f” from the beginning of the full pattern. -
ii)
The extracted stem for the word “يستطعن yst ṭ
 [tr. they can (in feminine form)]”, is “طع
[tr. they can (in feminine form)]”, is “طع  ” which means ‘obey’, where it should be “طوع ṭw
” which means ‘obey’, where it should be “طوع ṭw ”: So “طع ṭ
”: So “طع ṭ ” comes with short pattern “ف؟ل f?l” after removing ‘AIN’, “ع
” comes with short pattern “ف؟ل f?l” after removing ‘AIN’, “ع  ” from the middle of the full pattern.
” from the middle of the full pattern. -
iii)
The extracted stem for the word “يرمهما \(yrmhm{\bar{a}}\) [tr. he doesn’t throw them]”, is “رم rm” which means ‘throw’, where it should be “رمي rmy [tr. to throw]”: So “رم rm” comes with short pattern “فعـ؟
 ?” after removing ‘LAM’, “ل l” from the end of the full pattern.
?” after removing ‘LAM’, “ل l” from the end of the full pattern.




 ” after removing ‘FEH’, “ف f” from the beginning of the full pattern.
” after removing ‘FEH’, “ف f” from the beginning of the full pattern. [tr. they can (in feminine form)]”, is “طع
[tr. they can (in feminine form)]”, is “طع  ” which means ‘obey’, where it should be “طوع ṭw
” which means ‘obey’, where it should be “طوع ṭw ”: So “طع ṭ
”: So “طع ṭ ” comes with short pattern “ف؟ل f?l” after removing ‘AIN’, “ع
” comes with short pattern “ف؟ل f?l” after removing ‘AIN’, “ع  ” from the middle of the full pattern.
” from the middle of the full pattern. ?” after removing ‘LAM’, “ل l” from the end of the full pattern.
?” after removing ‘LAM’, “ل l” from the end of the full pattern.As a result of improper removal of some original letters from the segmented stems, we develop a Rhyzome operator for extracting the final root. The word ‘Rhyzome’ or ‘Rhizome’ is adopted from the ontology, which considers ‘Rhizome’ as the main part of speech in language processing (Haase, 1996). In fact, the ‘Rhizome’ was addressed by Deleuze and Guattari (1988) and Charniak (1996), which refers to the shortcut stems before extracting the final root. Hence, we adopted the word ‘Rhyzome’ from Charniak (1996), to be the name of this particular operator (i.e., Rhyzome operator).
In total there are 67 predefined short patterns (Rhyzomes), generated from the full patterns, to be used by this Rhyzome operator, to extract a set of Candidate-roots. Although there are several thousands of Arabic full patterns (Sawalha & Atwell, 2009) and Attia et al. (2011), we have only investigated and scrutinized these 67 short patterns as the main Rhyzomes. Then, we clustered these 67 Rhyzomes into two categories (Non-weak and Weak Rhyzomes). Table 4, has some examples of these clustered short patterns (Rhyzomes). The main goal behind clustering and dividing these Rhyzomes, can be explained as follows:
-
(1)
Non-weak Rhyzomes: refers to any tri-literal short pattern (“ف f”, “ع
 ”, “ل l”). For example, the short pattern “فواعل \(fw{\bar{a}}\)
”, “ل l”). For example, the short pattern “فواعل \(fw{\bar{a}}\) ”, is a non-weak Rhyzome and it will match the extracted stems: (“دوافع \(dw{\bar{a}}\)
”, is a non-weak Rhyzome and it will match the extracted stems: (“دوافع \(dw{\bar{a}}\) [tr. Motivations]), (“حوافز ḥ\(w{\bar{a}}fz\) [tr. Incentive]), and (“بواعث \(bw{\bar{a}}\)
[tr. Motivations]), (“حوافز ḥ\(w{\bar{a}}fz\) [tr. Incentive]), and (“بواعث \(bw{\bar{a}}\) [tr. Emitters]). Also, the short pattern “فعال f
[tr. Emitters]). Also, the short pattern “فعال f l”, will match the extracted stems: (“كتاب \(kt{\bar{a}}b\) [tr. Book]), (“رجال \(r\check{g}{\bar{a}}l\) [tr. Men]), and (“رياح \(ry{\bar{a}}\) ḥ [tr. Winds]).
l”, will match the extracted stems: (“كتاب \(kt{\bar{a}}b\) [tr. Book]), (“رجال \(r\check{g}{\bar{a}}l\) [tr. Men]), and (“رياح \(ry{\bar{a}}\) ḥ [tr. Winds]). -
(2)
Weak Rhyzomes: refers to any short pattern, that one or more of its original root letter has been removed. For example, i) The short pattern “عل
 ” is a weak Rhyzome, after removing the original letter “ف f” from the beginning. So, “عل
” is a weak Rhyzome, after removing the original letter “ف f” from the beginning. So, “عل  ” as a weak Rhyzome, will match the extracted stem (“صل ṣl [tr. Reach]”). Also, “عال
” as a weak Rhyzome, will match the extracted stem (“صل ṣl [tr. Reach]”). Also, “عال  l” as a weak Rhyzome will match the extracted stem (“صال ṣ\({\bar{a}}l\)”), from the segmented word “اوصال aw ṣ\({\bar{a}}l\) [tr. limbs]”\(\leftarrow\) “او+صال \({\bar{a}}w+\) ṣ\({\bar{a}}l\)”, which means ‘Many connects’. ii) The short pattern “فال \(f{\bar{a}}l\)” is a weak Rhyzome after removing the original “ع
l” as a weak Rhyzome will match the extracted stem (“صال ṣ\({\bar{a}}l\)”), from the segmented word “اوصال aw ṣ\({\bar{a}}l\) [tr. limbs]”\(\leftarrow\) “او+صال \({\bar{a}}w+\) ṣ\({\bar{a}}l\)”, which means ‘Many connects’. ii) The short pattern “فال \(f{\bar{a}}l\)” is a weak Rhyzome after removing the original “ع  ” from the middle. So, “فال \(f{\bar{a}}l\)” as a weak Rhyzome will match the extracted stem (“قال \(q{\bar{a}}l\) [tr. Said]”). iii) The short pattern “فواع \(fw{\bar{a}}\)
” from the middle. So, “فال \(f{\bar{a}}l\)” as a weak Rhyzome will match the extracted stem (“قال \(q{\bar{a}}l\) [tr. Said]”). iii) The short pattern “فواع \(fw{\bar{a}}\) ” is a weak Rhyzome after removing the original “ل l” from the end. So, “فواع \(fw{\bar{a}}\)
” is a weak Rhyzome after removing the original “ل l” from the end. So, “فواع \(fw{\bar{a}}\) ” as a weak Rhyzome will match the following extracted stems (“حواسّ ḥ\(w{\bar{a}}s\) [tr. Senses]”), (“بواك \(bw{\bar{a}}k\) [tr. Cryings persons]”), and (“بواق \(bw{\bar{a}}q\) [tr. Remainings]”).
” as a weak Rhyzome will match the following extracted stems (“حواسّ ḥ\(w{\bar{a}}s\) [tr. Senses]”), (“بواك \(bw{\bar{a}}k\) [tr. Cryings persons]”), and (“بواق \(bw{\bar{a}}q\) [tr. Remainings]”).
 ”, “ل l”). For example, the short pattern “فواعل
”, “ل l”). For example, the short pattern “فواعل  ”, is a non-weak Rhyzome and it will match the extracted stems: (“دوافع
”, is a non-weak Rhyzome and it will match the extracted stems: (“دوافع  [tr. Motivations]), (“حوافز ḥ
[tr. Motivations]), (“حوافز ḥ [tr. Emitters]). Also, the short pattern “فعال f
[tr. Emitters]). Also, the short pattern “فعال f l”, will match the extracted stems: (“كتاب
l”, will match the extracted stems: (“كتاب  ” is a weak Rhyzome, after removing the original letter “ف f” from the beginning. So, “عل
” is a weak Rhyzome, after removing the original letter “ف f” from the beginning. So, “عل  ” as a weak Rhyzome, will match the extracted stem (“صل ṣl [tr. Reach]”). Also, “عال
” as a weak Rhyzome, will match the extracted stem (“صل ṣl [tr. Reach]”). Also, “عال  l” as a weak Rhyzome will match the extracted stem (“صال ṣ
l” as a weak Rhyzome will match the extracted stem (“صال ṣ ” from the middle. So, “فال
” from the middle. So, “فال  ” is a weak Rhyzome after removing the original “ل l” from the end. So, “فواع
” is a weak Rhyzome after removing the original “ل l” from the end. So, “فواع  ” as a weak Rhyzome will match the following extracted stems (“حواسّ ḥ
” as a weak Rhyzome will match the following extracted stems (“حواسّ ḥ3.3.2 Implementing rhyzome operator
Just After the normalization process, the Rhyzome operator determines the length of each stem and identifies the shortcut patterns that match the same lengths. Figure 5 presents an example of the word “اعتادوا \({\bar{a}}\) \({\bar{a}}dw{\bar{a}}\) [tr. they accustomed to ]”, which is segmented to extract the stem “عتاد
\({\bar{a}}dw{\bar{a}}\) [tr. they accustomed to ]”, which is segmented to extract the stem “عتاد  \({\bar{a}}d\)”. After that, the Rhyzome-operator identifies the two shortcut patterns: (“فعال f
\({\bar{a}}d\)”. After that, the Rhyzome-operator identifies the two shortcut patterns: (“فعال f l” and “فتعل ft
l” and “فتعل ft ”) as the non-weak Rhyzomes, while, it identifies the shortcut pattern (“فتال \(ft{\bar{a}}l\)”) as a weak Rhyzome.
”) as the non-weak Rhyzomes, while, it identifies the shortcut pattern (“فتال \(ft{\bar{a}}l\)”) as a weak Rhyzome.

Process of Rhyzome-operator step to extract the final correct ‘Root’ from the set of Candidate-roots
Now, there is a truncate function responsible for generating the main primary root. This truncate function firstly performs a matching process for each short-pattern with the corresponding stem (“عتاد  \({\bar{a}}d\)”), as follows:
\({\bar{a}}d\)”), as follows:
-
(1)
By using the non-weak Rhyzome “فعال f
 l”, the truncate function removes the letter “ا \({\bar{a}}\)” from the extracted stem “عتاد
l”, the truncate function removes the letter “ا \({\bar{a}}\)” from the extracted stem “عتاد  \({\bar{a}}d\)”. Then, the remaining letters (“عـ+تـ+ـد
\({\bar{a}}d\)”. Then, the remaining letters (“عـ+تـ+ـد  \(t+d\)”), will match the full pattern (i.e., “ف+ع+ل \(f+\)
\(t+d\)”), will match the full pattern (i.e., “ف+ع+ل \(f+\) l”) of the non-weak Rhyzome “فعال f
l”) of the non-weak Rhyzome “فعال f l”, after eliminating the “ا \({\bar{a}}\)” letter. Therefore, the (“عتـ?ـد
l”, after eliminating the “ا \({\bar{a}}\)” letter. Therefore, the (“عتـ?ـد  ?d”) will be used to extract the first primary root (“عتد
?d”) will be used to extract the first primary root (“عتد  d”), see point numbered (1) in Fig. 5.
d”), see point numbered (1) in Fig. 5. -
(2)
By using the non-weak Rhyzome “فتعل ft
 ”, the truncate function removes the excess letter “ت t” from the extracted stem “عتاد
”, the truncate function removes the excess letter “ت t” from the extracted stem “عتاد  \({\bar{a}}d\)”. Then, the remaining letters (“ع+ا+د
\({\bar{a}}d\)”. Then, the remaining letters (“ع+ا+د  \({\bar{a}}+d\)”), will be matching the full pattern (i.e., “ف+ع+ل \(f+\)
\({\bar{a}}+d\)”), will be matching the full pattern (i.e., “ف+ع+ل \(f+\) l”) of the non-weak Rhyzome “فتعل ft
l”) of the non-weak Rhyzome “فتعل ft ”, after eliminating “ت t” as the excess letter. Therefore, the (“عتـ?ـد
”, after eliminating “ت t” as the excess letter. Therefore, the (“عتـ?ـد  \(?{\bar{a}}d\)”) will be used to extract the first primary root (“عاد
\(?{\bar{a}}d\)”) will be used to extract the first primary root (“عاد  d”), see point numbered (2) in Fig. 5.
d”), see point numbered (2) in Fig. 5. -
(3)
By using the weak Rhyzome “فتال \(ft{\bar{a}}l\)”, the truncate function removes the two excess letters “ت t” and “ا \({\bar{a}}\)”, from the extracted stem “عتاد
 \({\bar{a}}d\)”. Then, the other two letters (“عـ+ـد
\({\bar{a}}d\)”. Then, the other two letters (“عـ+ـد  d”), will be matching the pattern (i.e., “فـ+ـل \(f+l\)”) in the weak Rhyzome “فتال \(ft{\bar{a}}l\)”, while the original letter “ع
d”), will be matching the pattern (i.e., “فـ+ـل \(f+l\)”) in the weak Rhyzome “فتال \(ft{\bar{a}}l\)”, while the original letter “ع  ” is already removed from the middle of the weak Rhyzome “فتال \(ft{\bar{a}}l\)”. So, after eliminating “ت t” and “ا \({\bar{a}}\)” as the excess two letters from the extracted stem “عتاد
” is already removed from the middle of the weak Rhyzome “فتال \(ft{\bar{a}}l\)”. So, after eliminating “ت t” and “ا \({\bar{a}}\)” as the excess two letters from the extracted stem “عتاد  \({\bar{a}}d\)”, it will be (“
\({\bar{a}}d\)”, it will be (“ ”). Therefore, (“عد
”). Therefore, (“عد  ”), is extracted as the first primary root, from the stem (“عتاد
”), is extracted as the first primary root, from the stem (“عتاد  \({\bar{a}}d\)” \(\rightarrow\) “عد
\({\bar{a}}d\)” \(\rightarrow\) “عد  ”), see point numbered (3) in Fig. 5.
”), see point numbered (3) in Fig. 5.
 l”, the truncate function removes the letter “ا
l”, the truncate function removes the letter “ا 

 l”) of the non-weak Rhyzome “فعال f
l”) of the non-weak Rhyzome “فعال f l”, after eliminating the “ا
l”, after eliminating the “ا  ?d”) will be used to extract the first primary root (“عتد
?d”) will be used to extract the first primary root (“عتد  d”), see point numbered (1) in Fig.
d”), see point numbered (1) in Fig.  ”, the truncate function removes the excess letter “ت t” from the extracted stem “عتاد
”, the truncate function removes the excess letter “ت t” from the extracted stem “عتاد 

 l”) of the non-weak Rhyzome “فتعل ft
l”) of the non-weak Rhyzome “فتعل ft ”, after eliminating “ت t” as the excess letter. Therefore, the (“عتـ?ـد
”, after eliminating “ت t” as the excess letter. Therefore, the (“عتـ?ـد 
 d”), see point numbered (2) in Fig.
d”), see point numbered (2) in Fig. 
 d”), will be matching the pattern (i.e., “فـ+ـل
d”), will be matching the pattern (i.e., “فـ+ـل  ” is already removed from the middle of the weak Rhyzome “فتال
” is already removed from the middle of the weak Rhyzome “فتال 
 ”). Therefore, (“عد
”). Therefore, (“عد  ”), is extracted as the first primary root, from the stem (“عتاد
”), is extracted as the first primary root, from the stem (“عتاد 
 ”), see point numbered (3) in Fig.
”), see point numbered (3) in Fig. 3.3.3 Candidate-root extraction step
The primary roots that are generated from previous matching and the truncate function, will be then manipulated to extract a set of ‘Candidate-Roots’. For example, the “عتد  d”, “عاد
d”, “عاد  d”, and “عـد
d”, and “عـد  ” are the primary roots that are previously generated using the truncate function, see points (1, 2, and 3) in Fig. 5, respectively. In the meantime, a manipulation function will be invoked to extract the ‘Candidate-Roots’ from these primary roots, as follows:
” are the primary roots that are previously generated using the truncate function, see points (1, 2, and 3) in Fig. 5, respectively. In the meantime, a manipulation function will be invoked to extract the ‘Candidate-Roots’ from these primary roots, as follows:
-
(1)
The primary root “عتد
 d” will be considered as the first acceptable ‘Candidate-Root’. Since the letters of this particular root “عتد
d” will be considered as the first acceptable ‘Candidate-Root’. Since the letters of this particular root “عتد  d” are standard (i.e., non-vowels), and they are generated from the non-weak Rhyzome “فعال f
d” are standard (i.e., non-vowels), and they are generated from the non-weak Rhyzome “فعال f l” after removing the “ا \({\bar{a}}\)” letter, using the previous truncate function.
l” after removing the “ا \({\bar{a}}\)” letter, using the previous truncate function. -
(2)
The second primary root “عاد
 d” has a vowel letter (“ا \({\bar{a}}\)”), in the middle. Therefore, the manipulation function converts this vowel letter “ا \({\bar{a}}\)”, into two forms i.e., (“و w”, and “ي y”). Consequently, the (“عود
d” has a vowel letter (“ا \({\bar{a}}\)”), in the middle. Therefore, the manipulation function converts this vowel letter “ا \({\bar{a}}\)”, into two forms i.e., (“و w”, and “ي y”). Consequently, the (“عود  d” and “عيد
d” and “عيد 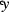 d”), are two acceptable ‘Candidate-Roots’, that is extracted from the second primary root “عاد
d”), are two acceptable ‘Candidate-Roots’, that is extracted from the second primary root “عاد  d”, as illustrated in point number (2) at Fig. 5.
d”, as illustrated in point number (2) at Fig. 5. -
(3)
The third primary root “عد
 ” is a short word with a length of fewer than three letters, which needs special treatment in the manipulation function. The primary root “عد
” is a short word with a length of fewer than three letters, which needs special treatment in the manipulation function. The primary root “عد  ” is generated by removing the two excess letters “ت t” and “ا \({\bar{a}}\)”, from the extracted stem “عتاد
” is generated by removing the two excess letters “ت t” and “ا \({\bar{a}}\)”, from the extracted stem “عتاد  \({\bar{a}}d\)”, when matching with weak Rhyzome “فتال \(ft{\bar{a}}l\)”. So, the original letter “ع
\({\bar{a}}d\)”, when matching with weak Rhyzome “فتال \(ft{\bar{a}}l\)”. So, the original letter “ع  ” is removed from the middle of the weak Rhyzome “فتال \(ft{\bar{a}}l\)”. Therefore, the manipulation function will extend only the middle part of this primary root “عد
” is removed from the middle of the weak Rhyzome “فتال \(ft{\bar{a}}l\)”. Therefore, the manipulation function will extend only the middle part of this primary root “عد  ”, by adding “و w” to extract “عود
”, by adding “و w” to extract “عود  d” as an acceptable ‘Candidate-Root’ from “عد
d” as an acceptable ‘Candidate-Root’ from “عد  ”. And thereafter, the manipulation function will add “ي y” to the middle of the primary root “عد
”. And thereafter, the manipulation function will add “ي y” to the middle of the primary root “عد  ”, in order to extract “عيد
”, in order to extract “عيد  d” as another acceptable ‘Candidate-Root’ from “عد
d” as another acceptable ‘Candidate-Root’ from “عد  ”, see point number (3) in Fig. 5.
”, see point number (3) in Fig. 5.
 d” will be considered as the first acceptable ‘Candidate-Root’. Since the letters of this particular root “عتد
d” will be considered as the first acceptable ‘Candidate-Root’. Since the letters of this particular root “عتد  d” are standard (i.e., non-vowels), and they are generated from the non-weak Rhyzome “فعال f
d” are standard (i.e., non-vowels), and they are generated from the non-weak Rhyzome “فعال f l” after removing the “ا
l” after removing the “ا  d” has a vowel letter (“ا
d” has a vowel letter (“ا  d” and “عيد
d” and “عيد 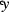 d”), are two acceptable ‘Candidate-Roots’, that is extracted from the second primary root “عاد
d”), are two acceptable ‘Candidate-Roots’, that is extracted from the second primary root “عاد  d”, as illustrated in point number (2) at Fig.
d”, as illustrated in point number (2) at Fig.  ” is a short word with a length of fewer than three letters, which needs special treatment in the manipulation function. The primary root “عد
” is a short word with a length of fewer than three letters, which needs special treatment in the manipulation function. The primary root “عد  ” is generated by removing the two excess letters “ت t” and “ا
” is generated by removing the two excess letters “ت t” and “ا 
 ” is removed from the middle of the weak Rhyzome “فتال
” is removed from the middle of the weak Rhyzome “فتال  ”, by adding “و w” to extract “عود
”, by adding “و w” to extract “عود  d” as an acceptable ‘Candidate-Root’ from “عد
d” as an acceptable ‘Candidate-Root’ from “عد  ”. And thereafter, the manipulation function will add “ي y” to the middle of the primary root “عد
”. And thereafter, the manipulation function will add “ي y” to the middle of the primary root “عد  ”, in order to extract “عيد
”, in order to extract “عيد  d” as another acceptable ‘Candidate-Root’ from “عد
d” as another acceptable ‘Candidate-Root’ from “عد  ”, see point number (3) in Fig.
”, see point number (3) in Fig. So far, our proposed Tashaphyne0.4 stemming algorithm based on Rhyzome operator, extracts a set of acceptable ‘Candidate-Roots’, which will be ready for further process (i.e., Selection Schemes for final-Root). The most important issue to be addressed in this coming stage, is how to decide and select the best final root from all these acceptable ‘Candidate-Roots’. As a result, the final-root should be the most precise one.
3.3.4 Selection schema for final-root
The manipulation function extracted a set of ‘Candidate-Roots’ from the ‘Primary-Roots’, in the previous step (i.e., Candidate-Root Extraction Step). Figure 5 illustrates the entire process, however, the manipulation function extracts the following: The candidate-root “عتد  d” one time at point number (1) in Fig. 5; The candidate-root “عيد
d” one time at point number (1) in Fig. 5; The candidate-root “عيد  d” two times at points (2 and 3) in Fig. 5; The candidate-root “عود
d” two times at points (2 and 3) in Fig. 5; The candidate-root “عود  d” two times at points (2 and 3) in Fig. 5. A selection schema is incorporated to detect the final root throughout two procedures: The first procedure is to validate the accuracy of each extracted ‘Candidate-Root’, while the other one aims at distinguishing all ‘Candidate-Roots’ and detecting the ‘Best-Root’.
d” two times at points (2 and 3) in Fig. 5. A selection schema is incorporated to detect the final root throughout two procedures: The first procedure is to validate the accuracy of each extracted ‘Candidate-Root’, while the other one aims at distinguishing all ‘Candidate-Roots’ and detecting the ‘Best-Root’.
The mechanism of the selection schema can be summarized as follows: Firstly, the accuracy procedure receives all ‘Candidate-Roots’ and individually compares them with the root-dictionary. If the corresponding ‘Candidate-Root’ matches a certain root in the root-dictionary, it will be considered as an acceptable one, otherwise, it will be removed from the last set of acceptable roots. In the example of Fig. 5, the accuracy procedure takes: {“عتد  d”, “عيد
d”, “عيد  d”, and “عود
d”, and “عود  d”}, and validate each with the root-dictionary. Finally, it removes the “عيد
d”}, and validate each with the root-dictionary. Finally, it removes the “عيد  d” from the final set of ‘Candidate-Roots’, since the “عيد
d” from the final set of ‘Candidate-Roots’, since the “عيد  d” does not match anyone in the root-dictionary. Then, the accuracy procedure adds the {“عتد
d” does not match anyone in the root-dictionary. Then, the accuracy procedure adds the {“عتد  d”, and “عود
d”, and “عود  d”}, to the set of final acceptable roots.
d”}, to the set of final acceptable roots.
Secondly, the selection procedure takes these acceptable roots and extracts the final ‘Best-Root’ according to the maximum number of iterations for each acceptable root. In the example of Fig. 5, the final acceptable root “عتد  d” is iterated once, while the acceptable root “عود
d” is iterated once, while the acceptable root “عود  d” is iterated twice. Consequently, this particular procedure selects the acceptable root “عود
d” is iterated twice. Consequently, this particular procedure selects the acceptable root “عود  d”, to be the last ‘Best-Root’ as it has the maximum number of iterations. Nevertheless, if the accuracy procedure could not find any matching root in all of the corresponding ‘Candidate-Roots’, it will consider the maximum-iterations ‘Candidate-Root’ as the final output and the last acceptable root.
d”, to be the last ‘Best-Root’ as it has the maximum number of iterations. Nevertheless, if the accuracy procedure could not find any matching root in all of the corresponding ‘Candidate-Roots’, it will consider the maximum-iterations ‘Candidate-Root’ as the final output and the last acceptable root.
4 Experimental results analysis
Our proposed Tashaphyne0.4 light stemming algorithm has been implemented and developed using Python programming language. The system accepts input of Arabic words from a text file, to extract their stems and roots. Furthermore, we have developed an online platform to process direct experiments, in order to extract “roots” and “stems” from any input. The next subsection presents the used datasets in experiments and results. The following subsections introduce the result analysis and a comparison process against other existing Arabic stemmers. However, the results prove the robustness of our proposed approach against Khoja-stemmer (Khoja & Garside, 1999), ISRI-stemmer (Taghva et al., 2005), Motaz/Light10-stemmer (Saad & Ashour, 2010), FARASA-stemmer (Abdelali et al., 2016), the previous version of Tashaphyne-stemmer (Zerrouki, 2012), and Assem snowball stemmer (Chelli, 2018a)). From deep investigation among all the existent systems, Assem-stemmer is chosen and considered the baseline to be the main reference (Chelli, 2018a). Therefore, we used it for computing the percentage of improvement of our results compared with Assem-stemmer as the main baseline.
4.1 Datasets and evaluation metrics
Four different datasets and corpora have been collected, in order to test and evaluate our proposed Tashaphyne0.4 light stemming algorithm. These four datasets are carefully chosen and updated from the following several resources of Arabic corpora:
-
(1)
The first dataset is the Quran Kalemat corpus that includes 15,038 words. These words are initially collected from Holy Quran by Dukes and Habash (2010); Nahar et al. (2020b). Then, they were updated by Jaafar et al. (2017), and published online as a part of stemming evaluation corpora in ALELM website.Footnote 10 We recently processed this source of Quran words, and revised them in a new corpus called Quran Kalemat. They will be freely available for all Arabic NLP researchers.
-
(2)
The second dataset is called NAFIS, which was prepared by Namly et al. (2016). NAFIS includes 173 unique words to test the SAFAR application (Jaafar et al., 2017). NAFIS dataset is also considered as a standard corpus for testing and evaluating other Arabic stemming algorithms in ALELM website\(^{11}\).
-
(3)
The third dataset is called Golden Arabic corpus that includes 1,165 words. It was developed to test Assem-stemmer (Chelli, 2018a, b), which was revised in Ibn Malik Arabic NLP tools.Footnote 11
-
(4)
The fourth dataset contains 6,195 unique Arabic words, adapted and used in Al-Kabi et al. (2015). It has been constructed from different resources to cover various aspects of our life. This dataset has only the roots without stems, unlike the previous three datasets that include the roots and stems for each derived Arabic word.
Due to the lack of finding good standard benchmark datasets in literature, these collections of four datasets will be available online. Table 5 summarizes these four various datasets as the general guidance corpora, in order to be the main references for the researchers in the Arabic stemming domain. We collect these four datasets from various resources in terms of diversity to test and evaluate our proposed Tashaphyne0.4 light stemming algorithm. Furthermore, these four datasets have been used to prove the outperformance of our proposed algorithm, after comparing the results obtained from other state-of-the-art Arabic stemming algorithms, using the same four datasets as standard benchmark-corpora.
The Accuracy (Accur), Precision (Pr), Recall (Re), \(F_{1}\)-measure (\(F_{1}\)), are the main evaluation metrics that is usually used to measure the performance of stemming algorithms. Mathematically, the main objective of these four evaluation measures, can be calculated based on the following formulas that are adapted from Baeza-Yates et al. (2011), Jaafar et al. (2016).
where the four parameters (i.e., TP, FP, FN, and TN), are explained in Table 6. From the Precision (Pr) and Recall (Re) that are respectively calculated in Eqs. (3) and (4), we can formulate the \(F_1\)-measure (\(F_1\)) as follows:
4.2 Effect the developed rhyzome operator on the performance of the proposed algorithm
In this section, the effectiveness of deploying the Rhyzome operator on the performance of our proposed algorithm, is thoroughly studied. However, 67 short-patterns/Rhyzomes are derived from thousands of full Arabic patterns, which are presented in the studies of Sawalha and Atwell (2009) and Attia et al. (2011). Therefore, the effectiveness of the Rhyzome-operator is tested with a full experimental evaluation process using the four different datasets in Table 5.
In order to test the performance of our proposed Tashaphyne0.4 light stemming algorithm, the best root-results obtained are compared with results from the other six well-regarded stemming algorithms. These well-known stemming algorithms are summarised and abbreviated in Table 7. The final results of ‘Roots’, are summarized in Table 8, with respect to the main four measure-metrics (i.e., Accur, Pr, Re, and \(F_1\)).
The key comparative results are reported in Table 8, which are calculated based on metrics in Eqs. (2, 3, 4 and 5). The results obtained by our proposed Tashaphyne0.4 algorithm, are compared with outputs obtained from the other six stemmers, those are summarised in Table 7 (Khoja-stemmer Khoja and Garside (1999), ISRI-stemmer Taghva et al. (2005), Light10-stemmer Larkey et al. (2007), an old version of Tashaphyne-stemmer Zerrouki (2015), FARASA-stemmer Abdelali et al. (2016), and Assem-stemmer Chelli (2018b)).
From the ‘Root’ outputs calculated and reported in Table 8, all the most precise results are obtained by our proposed stemmer, which is based on the developed Rhyzome model. Numbers in ‘bold’ font style show the best accuracy and F1-measure results of running all seven stemmers for all four different datasets. The corpus name in the left column, has the total number of input words.
4.2.1 Roots comparative evaluation and discussion
Firstly, the ‘Accuracy’ metric is considered a concrete evaluating analysis for stemming algorithms in NLP domain (Baeza-Yates et al., 2011; Al-Kabi et al., 2011). However, the ‘Accuracy’ metric returns the perfect morphological analyzer to measure the performance of the stemming algorithm.

The comparative process of Accuracy percentages for obtaining results from our proposed stemming algorithm against other stemmers
Accuracy uses all pentameters (i.e., TN, FN, FP, and TN) that are explained in Table 6, to be used all together to calculate the ‘Accuracy’ benchmark, as shown in Eq. 2. Furthermore, the ‘Accuracy’ expresses and illustrates clearly the incorrect proportion in evaluating of NLP stemmers. Therefore, Fig. 6 shows the comparative evaluation of our proposed algorithm compared with other six well-regarded Arabic stemmers, respect to the Accuracy-metric of root-results.
This column-chart of evaluating analyses process in Fig. 6, proves the prominent performance of our proposed algorithm, which returns the most precise results compared to other well-regarded stemmers in three out of four used datasets. Our proposed algorithm also scored the second-best result related to the NAFIS dataset, while the NAFIS dataset is relatively very small (i.e., only has 173 words). Consequently, the comparative accuracy results prove the stability of our proposed algorithm in all four datasets, when compared with the other six stemmers from the literature.
4.2.2 Stems comparative evaluation and discussion
Some comparative stemmers like FARASA-stemmer Chelli (2018b), extract only the stems from the input Arabic words. Assem-stemmer also introduced a separate package to extract the ‘Stems’ from the input words, based on snowball stemming algorithm (Abdelali et al., 2016).
Consequently, our proposed algorithm extracts both ‘Stems’ and ‘Roots’ from the input of Arabic words in the same manner. However, we conduct a new comparative analyses process related to the ‘Stems’, as seen in Table 9. It proves the powerful performance and accuracy of our proposed Tashaphyne0.4 stemmer against the other six comparative stemmers. In order to analyse the results reported in Table 9, We can note that the accuracy and the recall are the same for Quran Kalemat and for Gold corpus; this is because those corpora does not have stem for their words. These “no stem” cases lead to have True Negative (TN) and False Positive (FP) as Zeros. This will lead to calculate the \(Precision = TP /(TP +FP) = TP /(TP +0) =\)100%, in case of Gold corpus and Quran Kalimat (99.99%). The measure of \(Accuracy = (TP + TN)/(TP+FN+FP+TN) = (TP + 0)/(TP+FN+0+0) = TP/(TP+FN) =Recall\), therefore the value of Accuracy will becomes equal the value of Recall. For Nafis Corpus, it has some cases of missing stems, which give some differences between Recall and Accuracy, which gives the Precision different from 100%.
As reported in Table 9, the best ‘Stems’ results are in ‘bold’ font size. It shows both the accuracy and F1-measure results. Given that‘Accuracy’ is considered as a concrete evaluating metric for stemming algorithms. Also, the ‘F1-measure’ is the most important evaluating metric that can be used to test the performance of stemming algorithms. However, our proposed algorithm scored the second-best stem-result related to the GOLD dataset, while the GOLD dataset is relatively small, which only covers 1,165 words. Consequently, the comparative accuracy results illustrate the stability of our proposed algorithm in all other datasets, when compared with other stemmers from literature.

The comparative process of Stem percentages for obtained results from our proposed stemming algorithm against other stemmers
Figure 7 shows the comparative evaluations of our proposed algorithm compared with other the six stemmers, with respect to the stem-results of the ‘Accuracy’ metric. This is due to the ‘Accuracy’ metric illustrates clearly the false proportion in evaluating the NLP stemmers, and is considered the best evaluation metric.
5 Conclusion
In this study, a new light stemming algorithm based on the Rhyzome model is proposed to extract ‘Roots’ and ‘Stems’ from input text. The proposed stemmer is called modernized Tashaphyne (Tashaphyne0.4), which uses three main phases (i.e., Preparation, Stem-Extractor, and Root-Extractor). The proposed algorithm not only aims at extracting the ‘Roots’ but also to retrieve the ‘Stems’. Each phase has its process to manipulate the text in a different manner, and thus to extract the most precise stems and roots at a different level. Splitting the text into words using a tokenization process, is done in the preparation phase. The Stem-Extractor phase utilizes the modified Finite State Automaton (modified-FSA) technique, in order to extract the best ‘Stems’. The previous two phases integrate with the third one (i.e., the Root-Extractor phase). Therefore, our proposed approach introduces a novel contribution to the Arabic NLP community by extracting ‘Roots’, ‘Stems’ and segmentation. Consequently, the proposed algorithm acts as a rooter, stemmer, and segmentation tool simultaneously.
For evaluation purposes, four different Arabic corpora -as main benchmark datasets- are conducted, (i.e., Quran Kalemat corpus, NAFIS corpus, GOLD corpus, and Al-Kabi Arabic corpus). These four different datasets are carefully selected from several resources of Arabic corpora. Rhyzome model is investigated as well to empower the proposed algorithm. In a nutshell, the development of 67 short-patterns (Rhyzomes) out of thousands of patterns, constructing the most precise Rhyzome-operator and achieved the best final-roots with a reasonable time-complexity. Furthermore, the final results of our proposed algorithm are compared with those obtained from other six well-regarded Arabic stemmers, using the same four datasets. Interestingly, our proposed Tashaphyne0.4 algorithm scores outstanding results that outperform other stemmers in almost all four different datasets.
Building a robust stemming algorithm gives direct impact to enhance the information retrieval by extracting ‘Roots’ and ‘Stems’. Like Rhyzome-model, newly invited AI models can be utilized with further studies to improve new stemming algorithms in future works.
Notes
Source code available on https://github.com/motazsaad/khoja-stemmer-command-line.
Source code available on https://www.nltk.org/_modules/nltk/stem/isri.html.
Source code available on https://github.com/motazsaad/arabic-light-stemmer.
Source code available on https://github.com/linuxscout/tashaphyne.
Source code available on https://pypi.org/project/Tashaphyne/#history.
Source code available on https://github.com/qcri/.
Source code available on https://github.com/assem-ch/arabicstemmer.
Live demo on https://arabicstemmer.com/.
Source code available on https://github.com/kdarwish/qatara/.
Source code available on http://arabic.emi.ac.ma/alelm/?q=Resources.
Source code available on https://github.com/ibnmalik/golden-corpus-arabic.
References
Abainia, K., Ouamour, S., & Sayoud, H. (2017). A novel robust Arabic light stemmer. Journal of Experimental & Theoretical Artificial Intelligence, 29(3), 557–573.
Abdelali, A., Darwish, K., Durrani, N., & Mubarak, H. (2016). Farasa: A fast and furious segmenter for Arabic. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations. (pp. 11–16). California, San Diego.
Al-Kabi, M. N., Al-Radaideh, Q. A., & Akkawi, K. W. (2011). Benchmarking and assessing the performance of Arabic stemmers. Journal of Information Science, 37(2), 111–119.
Al-Kabi, M. N., Kazakzeh, S. A., Ata, B. M. A., Al-Rababah, S. A., & Alsmadi, I. M. (2015). A novel root based Arabic stemmer. Journal of King Saud University-Computer and Information Sciences, 27(2), 94–103.
Al-Khatib, R. M., Al-Betar, M. A., Awadallah, M. A., Nahar, K. M., Shquier, M. M. A., Manasrah, A. M., & Doumi, A. B. (2019). MGA-TSP: Modernised genetic algorithm for the travelling salesman problem. International Journal of Reasoning-Based Intelligent Systems, 11(3), 215–226.
Al-Khatib, R. M., El-Omari, N. K. T., & Al-Betar, M. A. (2023). Innovative cloud computing object-oriented model to unify heterogeneous data. International Journal of Operational Research, 46(3), 289–322.
Al-Khatib, R. M., Zerrouki, T., Abu Shquier, M. M., Balla, A., & Al-Khateeb, A. (2021). A new enhanced Arabic light stemmer for IR in medical documents. Computers, Materials & Continua, 68(1), 1255–1269.
Al-Sughaiyer, I. A., & Al-Kharashi, I. A. (2004). Arabic morphological analysis techniques: A comprehensive survey. Journal of the American Society for Information Science and Technology, 55(3), 189–213.
Algasaier, H. (2018). The ISRI Arabic stemmer. https://www.nltk.org/_modules/nltk/stem/isri.html.
Alkhateeb, F., Al-Khatib, R. M., & Doush, I. A. (2020). A survey for recent applications and variants of nature-inspired immune search algorithm. International Journal of Computer Applications in Technology, 63(4), 354–370.
Almazrua, A., Almazrua, M., & Alkhalifa, H. (2020). Comparative analysis of nine arabic stemmers on microblog information retrieval. In 2020 International Conference on Asian Language Processing (IALP) (pp. 60–65). Kuala Lumpur, Malaysia.
Attia, M., Pecina, P., Tounsi, L., Toral, A., & Van Genabith, J. (2011). Lexical profiling for Arabic. In Proceedings of eLex Conference, (pp. 23–33).
Aubry, J.-F., & Brinzei, N. (2015). Systems dependability assessment: Modeling with graphs and finite state automata. Wiley.
Baeza-Yates, R., Ribeiro, B., et al. (2011). Modern information retrieval. New York: ACM Press.
Bounhas, I., Soudani, N., & Slimani, Y. (2020). Building a morpho-semantic knowledge graph for Arabic information retrieval. Information Processing & Management, 57(6), 102124.
Brychcín, T., & Konopík, M. (2015). Hps: High precision stemmer. Information Processing & Management, 51(1), 68–91. https://www.sciencedirect.com/science/article/pii/S0306457314000843.
Charniak, E. (1996). Statistical language learning. MIT press.
Chelli, A., (2018a). Assem Arabic light stemming algorithm. https://arabicstemmer.com/.
Chelli, A., (2018b). Assem Arabic root-based stemmer. https://github.com/assem-ch/arabicstemmer.
Chelli, A., (2018c). Assem’s Arabic stemmer. https://figshare.com/articles/Assem_s_Arabic_Stemmer/7295690.
Daciuk, J. (2016). Incremental construction of finite-state automata. Handbook of finite state based models and applications (pp. 173–192). Chapman and Hall/CRC.
Dahab, M. Y., Ibrahim, A., & Al-Mutawa, R. (2015). A comparative study on Arabic stemmers. International Journal of Computer Applications, 125(8), 975–8887.
Darwish, K. (2015). QCRI advanced tools for Arabic (Qatara). https://github.com/kdarwish/Qatara.
Deleuze, G., & Guattari, F. (1988). A thousand plateaus: Capitalism and schizophrenia. Bloomsbury Publishing.
Dukes, K., & Habash, N. (2010). Morphological annotation of quranic arabic. In: Proceedings of the Seventh conference on International Language Resources and Evaluation (LREC’10). European Languages Resources Association (ELRA), (pp. 1–7). Valletta, Malta. http://www.lrec-conf.org/proceedings/lrec2010/pdf/276_Paper.pdf.
Elayeb, B., & Bounhas, I. (2016). Arabic cross-language information retrieval: A review. ACM Transactions on Asian and Low-Resource Language Information Processing (TALLIP), 15(3), 1–44.
FARASA, Q. (2018). FARASA Arabic light stemming algorithm. Qatar Computing Research Institute (QCRI)–QCRI Arabic language technologies. http://qatsdemo.cloudapp.net/farasa/demo.html.
Ghwanmeh, S., Kanaan, G., Al-Shalabi, R., & Rabab’ah, S. (2009). Enhanced algorithm for extracting the root of Arabic words. In 2009 Sixth International Conference on Computer Graphics, Imaging and Visualization. (pp. 388–391).
Haase, K. B. (1996). Matching texts to extract information.
Habash, N. Y. (2010). Introduction to Arabic natural language processing. Synthesis Lectures on Human Language Technologies, 3(1), 1–187.
Jaafar, Y., Bouzoubaa, K., Yousfi, A., Tajmout, R., & Khamar, H. (2016). Improving Arabic morphological analyzers benchmark. International Journal of Speech Technology, 19(2), 259–267.
Jaafar, Y., Namly, D., Bouzoubaa, K., & Yousfi, A. (2017). Enhancing Arabic stemming process using resources and benchmarking tools. Journal of King Saud University-Computer and Information Sciences, 29(2), 164–170.
Kawaguchi, H., Kato, K., Fujisawa, H., Fujinawa, M., & Hatakeyama, A. (1991). System for character stream search using finite state automaton technique. US Patent 5,051,886.
Khoja, S., & Garside, R. (1999). Stemming Arabic text. Lancaster, UK, Computing Department, Lancaster University.
Larkey, L. S., Ballesteros, L., & Connell, M. E., (2007). Light stemming for Arabic information retrieval. In Arabic Computational Morphology. (pp. 221–243), Springer.
Lovins, J. B. (1968). Development of a stemming algorithm. Mechanical Translation and Computational Linguistics, 11(1–2), 22–31.
Madani, Y., Erritali, M., & Bengourram, J. (2018). Arabic stemmer based big data. Journal of Electronic Commerce in Organizations (JECO), 16(1), 17–28.
Migdady, A., Al-Aiad, A., & Al-Khatib, R. M., (2022). EfficientNet Deep Learning Model for Pneumothorax Disease Detection in chest X-rays Images. International Journal of Business Information Systems, Forthcoming.
Moral, C., de Antonio, A., Imbert, R., & Ramírez, J. (2014). A survey of stemming algorithms in information retrieval. Information Research: An International Electronic Journal, 19(1), n1.
Nahar, K. M., Al-Khatib, R. M., Al-Shannaq, M., Daradkeh, M., & Malkawi, R. (2020). Direct text classifier for thematic Arabic discourse documents. International Arab Journal of Information Technology (IAJIT), 17(3), 394–403.
Nahar, K. M., Al-Khatib, R. M., Al-Shannaq, M. A., & Barhoush, M. M. (2020). An efficient holy Quran recitation recognizer based on SVM learning model. Jordanian Journal of Computers and Information Technology (JJCIT), 6(04), 394–414.
Nahar, K. M., Al-shannaq, M., Alshorman, R., Al-Khatib, R. M., & Ot.tom, M. A. (2020). Handicapped wheelchair movements using discrete Arabic command recognition. Scientific Journal of King Faisal University (Basic and Applied Sciences), 21(1), 171–184.
Namly, D., Tajmout, R., Bouzoubaa, K., & Abouenour, L., (2016). Nafis: A gold standard corpus for arabic stemmers evaluation. In IBIMA Proceedings. 28th IBIMA Conference, (pp. 1–7). Seville, Spain. https://ibima.org/accepted-paper/nafis-a-gold-standard-corpus-for-arabic-stemmers-evaluation/.
Ogilvie, P., & Callan, J. P. (2001). Experiments using the lemur toolkit. In TREC’2001: Text Retrieval Conference (Vol. 10, pp. 103–108). Maryland, USA.
Orăsan, C., Evans, R., & Mitkov, R. (2017). Intelligent Natural Language Processing: Trends and Applications. Springer. http://hdl.handle.net/2436/621130.
Otair, M. A. (2013). Comparative analysis of Arabic stemming algorithms. International Journal of Managing Information Technology, 5(2), 1–13.
Pasha, A., Al-Badrashiny, M., Diab, M. T., El Kholy, A., Eskander, R., Habash, N., Pooleery, M., Rambow, O., & Roth, R. (2014). Madamira: A fast, comprehensive tool for morphological analysis and disambiguation of Arabic. In LREC: International Conference on Language Resources and Evaluation (Vol. 14, pp. 1094–1101). Reykjavik, Iceland.
Porter, M. F. (1980). An algorithm for suffix stripping. Program, 14(3), 130–137.
Rashaideh, H., Sawaie, A., Al-Betar, M. A., Abualigah, L. M., Al-Laham, M. M., Al-Khatib, R. M., & Braik, M. (2020). A grey wolf optimizer for text document clustering. Journal of Intelligent Systems, 29(1), 814–830.
Ra’ed, M., Al-qudah, N. E. A., Jawarneh, M. S., & Al-Khateeb, A. (2023). A novel improved lemurs optimization algorithm for feature selection problems. Journal of King Saud University-Computer and Information Sciences, 35(8), 101704.
Saad, M. K., & Ashour, W. M. (2010). Arabic morphological tools for text mining. In Corpora, 6th ArchEng International Symposiums, EEECS’10 the 6th International Symposium on Electrical and Electronics Engineering and Computer Science (Vol. 18, pp. 112–117). Lefke, North Cyprus.
Savoy, J. (1993). Stemming of French words based on grammatical categories. Journal of the American Society for Information Science, 44(1), 1–9.
Savoy, J. (2006). Light stemming approaches for the French, Portuguese, German and Hungarian languages. In: Proceedings of the 2006 ACM symposium on Applied computing. (pp. 1031–1035).
Sawalha, M., & Atwell, E. (2009). Linguistically informed and corpus informed morphological analysis of Arabic. In Proceedings of the 5th Corpus Linguistics Conference. Lancaster University Centre for Computer Corpus Research on Language, (pp. 1–22). Lancaster, UK.
Soudani, N., Bounhas, I., & Slimani, Y. (2019). Mossa: A morpho-semantic knowledge extraction system for Arabic information retrieval. International Journal of Knowledge and Web Intelligence, 6(2), 106–141.
Taghva, K., Elkhoury, R., & Coombs, J. (2005). Arabic stemming without a root dictionary. In Information Technology: Coding and Computing, ITCC 2005. International Conference on. Vol. 1. IEEE, (pp. 152–157). Las Vegas, NV, USA.
Trotman, A. (2004). An artificial intelligence approach to information retrieval. SIGIR, 4, 603–608.
Watson, B. (1993). A taxonomy of finite automata construction algorithms. Technical Report in Computing Science.
Zeroual, I., & Lakhouaja, A. (2017). Arabic information retrieval: Stemming or lemmatization? In 2017 Intelligent Systems and Computer Vision (ISCV). (pp. 1–6), Fez, Morocco.
Zerrouki, T. (2010). Tashaphyne, Arabic light stemmer/segment. http://github.com/linuxscout/tashaphyne.
Zerrouki, T. (2012). Tashaphyne, Arabic light stemmer. https://github.com/linuxscout/tashaphyne.
Zerrouki, T. (2015). Tashaphyne 0.2. https://github.com/linuxscout/tashaphyne.
Zerrouki, T. (2018). Tashaphyne 0.3.2, Arabic light stemmer. https://pypi.org/project/Tashaphyne/.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
R. M. Al-Khatib: Yarmouk University Since 1976.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Al-Khatib, R.M., Zerrouki, T., Abu Shquier, M.M. et al. Tashaphyne0.4: a new arabic light stemmer based on rhyzome modeling approach. Inf Retrieval J 26, 14 (2023). https://doi.org/10.1007/s10791-023-09429-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10791-023-09429-y