
Abstract
The discovery of frequent patterns is a famous problem in data mining. While plenty of algorithms have been proposed during the last decade, only a few contributions have tried to understand the influence of datasets on the algorithms behavior. Being able to explain why certain algorithms are likely to perform very well or very poorly on some datasets is still an open question. In this setting, we describe a thorough experimental study of datasets with respect to frequent itemsets. We study the distribution of frequent itemsets with respect to itemsets size together with the distribution of three concise representations: frequent closed, frequent free and frequent essential itemsets. For each of them, we also study the distribution of their positive and negative borders whenever possible. The main outcome of these experiments is a new classification of datasets invariant w.r.t. minsup variations and robust to explain efficiency of several implementations.










Similar content being viewed by others
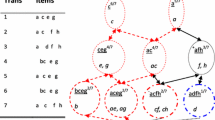


Notes
The set of closed itemsets is not closed downwards, and thus the notion of borders does not apply.
References
Agrawal, R., Imielinski, T., & Swami, A. N. (1993). Mining association rules between sets of items in large databases. In P. Buneman & S. Jajodia (Ed.), SIGMOD Conference (pp. 207–216). New York: ACM.
Agrawal, R., & Srikant, R. (1994). Fast algorithms for mining association rules in large databases. In J. B. Bocca, M. Jarke, & C. Zaniolo (Ed.), VLDB (pp. 487–499). San Francisco: Morgan Kaufmann.
Bastide, Y., Taouil, R., Pasquier, N., Stumme, G., & Lakhal, L. (2000). Mining frequent patterns with counting inference. SIGKDD Explorations, 2(2), 66–75.
Bayardo Jr., R. J., Goethals, B., & Zaki, M. J. (Eds.) (2004). FIMI ’04, proceedings of the IEEE ICDM workshop on frequent itemset mining implementations, November 1, 2004, CEUR workshop proceedings (Vol. 126). Brighton, UK: CEUR-WS.org.
Bayardo Jr., R. J., & Zaki, M. J. (Eds.) (2003). FIMI ’03, proceedings of the IEEE ICDM workshop on frequent itemset mining implementations, November 19, 2003, CEUR workshop proceedings (Vol. 90). Melbourne, Florida, USA: CEUR-WS.org.
Beeri, C., & Vardi, M. Y. (1984). A proof procedure for data dependencies. Journal of the Association for Computing Machinery, 31(4), 718–741.
Borgelt, C. (2003). Efficient implementations of Apriori and Eclat. In R. J. Bayardo Jr., & M. J. Zaki (Eds.), 1st workshop of frequent item set mining implementations. Melbourne, FL, USA: FIMI 2003.
Boulicaut, J.-F., Bykowski, A., & Rigotti, C. (2003). Free-sets: A condensed representation of boolean data for the approximation of frequency queries. Data Mining and Knowledge Discovery, 7(1), 5–22.
Burdick, D., Calimlim, M., Flannick, J., Gehrke, J., & Yiu, T. (2003). Mafia: A performance study of mining maximal frequent itemsets. In R. J. Bayardo Jr. & M. J. Zaki (Eds.), Journal of Intelligent Information Systems.
Burdick, D., Calimlim, M., & Gehrke, J. (2001). Mafia: A maximal frequent itemset algorithm for transactional databases. In ICDE (pp. 443–452). Los Alamitos: IEEE Computer Society.
Bykowski, A., & Rigottim, C. (2001). A condensed representation to find frequent patterns. In PODS. New York: ACM.
Calders, T., & Goethals, B. (2003). Minimal k-free representations of frequent sets. In N. Lavrac, D. Gamberger, H. Blockeel, & L. Todorovski (Eds.), PKDD. Lecture Notes in Computer Science (Vol. 2838, pp. 71–82). New York: Springer.
Casali, A., Cicchetti, R., & Lakhal, L. (2005). Essential patterns: A perfect cover of frequent patterns. In A. Min Tjoa & J. Trujillo (Eds.), DaWaK. Lecture notes in computer science (Vol. 3589, pp. 428–437). New York: Springer.
Casanova, M. A., Fagin, R., & Papadimitriou, C. H. (1984). Inclusion dependencies and their interaction with functional dependencies. Journal of Computer and System Sciences, 28(1), 29–59.
De Marchi, F., & Petit, J.-M. (2003). Zigzag: a new algorithm for mining large inclusion dependencies in database. In ICDM (pp. 27–34). Los Alamitos, IEEE Computer Society.
Flouvat, F. (2008). Study of frequent itemsets datasets. http://pages.univ-nc.nc/~flouvat/.
Flouvat, F., De Marchi, F., & Petit, J.-M. (2004). ABS: Adaptive Borders Search of frequent itemsets. In R. J. Bayardo Jr., B. Goethals, & M. J. Zaki (Eds.), Journal of Intelligent Information Systems.
Goethals, B. (2003). Frequent itemset mining implementations repository. http://fimi.cs.helsinki.fi/.
Gouda, K., & Zaki, M. J. (2001). Efficiently mining maximal frequent itemsets. In N. Cercone, T. Y. Lin, & X. Wu (Eds.), ICDM (pp. 163–170). Los Alamitos: IEEE Computer Society.
Grahne, G., & Zhu, J. (2003). Efficiently using prefix-trees in mining frequent itemsets. In R. J. Bayardo Jr., B. Goethals, & M. J. Zaki (Eds.), Journal of Intelligent Information Systems.
Han, J., Pei, J., & Yin, Y. (2000). Mining frequent patterns without candidate generation. In W. Chen, J. F. Naughton, & P. A. Bernstein (Eds.), SIGMOD conference (pp. 1–12). New York: ACM.
Kantola, M., Mannila, H., Räihä, K.-J., & Siirtola, H. (1992). Discovering functional and inclusion dependencies in relational databases. International Journal of Intelligent Systems, 7, 591–607.
Koeller, A., & Rundensteiner, E. A. (2003). Discovery of high-dimensional. In U. Dayal, K. Ramamritham, & T. M. Vijayaraman (Eds.), ICDE (pp. 683–685). Los Alamitos: IEEE Computer Society.
Kryszkiewicz, M., & Gajek, M. (2002). Concise representation of frequent patterns based on generalized disjunction-free generators. In M.-S. Cheng, P. S. Yu, & B. Liu (Eds.), PAKDD. Lecture notes in computer science (Vol. 2336, pp. 159–171). New York: Springer.
Liu, G., Lu, H., Yu, J. X., Wei, W., & Xiao, X. (2003). Afopt: An efficient implementation of pattern growth approach. In R. J. Bayardo Jr., B. Goethals, & M. J. Zaki (Eds.), Journal of Intelligent Information Systems.
Mannila, H., & Räihä, K-J. (1994). The design of relational databases (2nd ed.). Reading: Addison-Wesley.
Mannila, H., & Toivonen, H. (1996). Multiple uses of frequent sets and condensed representations (extended abstract). In KDD (pp. 189–194).
Mannila, H., & Toivonen, H. (1997). Levelwise search and borders of theories in knowledge discovery. Data Mining and Knowledge Discovery, 1(3), 241–258.
Orlando, S., Lucchese, C., Palmerini, P., Perego, R., & Silvestri, F. (2003). kdci: a multi-strategy algorithm for mining frequent sets. In R. J. Bayardo Jr., B. Goethals, & M. J. Zaki (Eds.), Journal of Intelligent Information Systems.
Palmerini, P., Orlando, S., & Perego, R. (2004). Statistical properties of transactional databases. In H. Haddad, A. Omicini, R. L. Wainwright, & L. M. Liebrock (Eds.), SAC (pp. 515–519). New York: ACM.
Pasquier, N., Bastide, Y., Taouil, R., & Lakhal, L. (1999). Discovering frequent closed itemsets for association rules. In C. Beeri & P. Buneman (Eds.), ICDT. Lecture notes in computer science (Vol. 1540, pp. 398–416). New York: Springer.
Ramesh, G., Maniatty, W., & Zaki, M.-J. (2003). Feasible itemset distributions in data mining: theory and application. In PODS (pp. 284–295). New York: ACM.
Ramesh, G., Zaki, M.-J., & Maniatty, W. (2005). Distribution-based synthetic database generation techniques for itemset mining. In IDEAS (pp. 307–316). Los Alamitos: IEEE Computer Society.
Uno, T., Asai, T., Uchida, Y., & Arimura, H. (2004). An efficient algorithm for enumerating closed patterns in transaction databases. In E. Suzuki, S. Arikawa (Eds.), Discovery Science. Lecture notes in computer science (Vol. 3245, pp. 16–31). New York: Springer.
Zaki, M.-J., Parthasarathy, S., Ogihara, M., & Li, W. (1997). New algorithms for fast discovery of association rules. In KDD (pp. 283–286), Journal of Intelligent Information Systems.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Flouvat, F., De Marchi, F. & Petit, JM. A new classification of datasets for frequent itemsets. J Intell Inf Syst 34, 1–19 (2010). https://doi.org/10.1007/s10844-008-0077-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10844-008-0077-0