
Abstract
Stochastic variance reduced gradient (SVRG) methods are important approaches to minimize the average of a large number of cost functions frequently arising in machine learning and many other applications. In this paper, based on SVRG, we propose a SVRG-TR method which employs a trust-region-like scheme for selecting stepsizes. It is proved that the SVRG-TR method is linearly convergent in expectation for smooth strongly convex functions and enjoys a faster convergence rate than SVRG methods. In order to overcome the difficulty of tuning stepsizes by hand, we propose to combine the Barzilai–Borwein (BB) method to automatically compute stepsizes for the SVRG-TR method, named as the SVRG-TR-BB method. By incorporating mini-batching scheme with SVRG-TR and SVRG-TR-BB, respectively, we further propose two extended methods mSVRG-TR and mSVRG-TR-BB. Linear convergence and complexity of mSVRG-TR are given. Numerical experiments on some standard datasets show that SVRG-TR and SVRG-TR-BB are generally better than or comparable to SVRG with best-tuned stepsizes and some modern stochastic gradient methods, while mSVRG-TR and mSVRG-TR-BB are very competitive with mini-batch variants of recent successful stochastic gradient methods.










Similar content being viewed by others

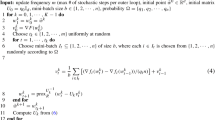
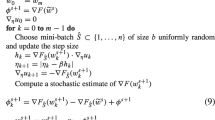
References
Allen-Zhu, Z.: Katyusha: The first direct acceleration of stochastic gradient methods. In: Proc. 49th Annu. SIGACT STOC, pp. 1200–1205 (2017)
Allen-Zhu, Z., Hazan, E.: Optimal black-box reductions between optimization objectives. In: Proc. 29th Int. Conf. Adv. Neural Inf. Process. Syst., pp. 1614–1622 (2016)
Allen-Zhu, Z., Yuan, Y.: Improved SVRG for non-strongly-convex or sum-of-non-convex objectives. In: Int. Conf. Mach. Learn., pp. 1080–1089 (2016)
Barzilai, J., Borwein, J.M.: Two-point step size gradient methods. IMA J. Numer. Anal. 8(1), 141–148 (1988)
Bonnabel, S.: Stochastic gradient descent on Riemannian manifolds. IEEE Trans. Autom. Control 58(9), 2217–2229 (2013)
Bottou, L.: Large-scale machine learning with stochastic gradient descent. In: Proc. COMPSTAT’2010, pp. 177–186. Springer (2010)
Bottou, L., Curtis, F.E., Nocedal, J.: Optimization methods for large-scale machine learning. SIAM Rev. 60(2), 223–311 (2018)
Cardoso, J.F., Laheld, B.H.: Equivariant adaptive source separation. IEEE Trans. Signal Process. 44(12), 3017–3030 (1996)
Chang, D., Lin, M., Zhang, C.: On the generalization ability of online gradient descent algorithm under the quadratic growth condition. IEEE Trans. Neural Netw. Learn. Syst. (2018)
Chen, Z., Xu, Y., Chen, E., Yang, T.: Sadagrad: strongly adaptive stochastic gradient methods. In: Int. Conf. Mach. Learn., pp. 912–920 (2018)
Cohen, K., Nedić, A., Srikant, R.: On projected stochastic gradient descent algorithm with weighted averaging for least squares regression. IEEE Trans. Autom. Control 62(11), 5974–5981 (2017)
Curtis, F.E., Scheinberg, K., Shi, R.: A stochastic trust region algorithm. arXiv preprint arXiv:1712.10277 (2017)
Dai, Y.H., Al-Baali, M., Yang, X.: A positive Barzilai–Borwein-like stepsize and an extension for symmetric linear systems. In: Numer. Funct. Anal. Optim., pp. 59–75. Springer (2015)
Dai, Y.H., Fletcher, R.: Projected Barzilai–Borwein methods for large-scale box-constrained quadratic programming. Numer. Math. 100(1), 21–47 (2005)
Defazio, A., Bach, F., Lacoste-Julien, S.: Saga: a fast incremental gradient method with support for non-strongly convex composite objectives. In: Proc. 27th Int. Conf. Adv. Neural Inf. Process. Syst., pp. 1646–1654 (2014)
Frostig, R., Ge, R., Kakade, S., Sidford, A.: Un-regularizing: approximate proximal point and faster stochastic algorithms for empirical risk minimization. In: Int. Conf. Mach. Learn., pp. 2540–2548 (2015)
Godard, D.: Self-recovering equalization and carrier tracking in two-dimensional data communication systems. IEEE Trans. Commun. 28(11), 1867–1875 (1980)
Harikandeh, R., Ahmed, M.O., Virani, A., Schmidt, M., Konečnỳ, J., Sallinen, S.: Stopwasting my gradients: practical SVRG. In: Proc. 28th Int. Conf. Adv. Neural Inf. Process. Syst., pp. 2251–2259 (2015)
Huang, Y., Liu, H.: Smoothing projected Barzilai–Borwein method for constrained non-Lipschitz optimization. Comput. Optim. Appl. 65(3), 671–698 (2016)
Huang, Y., Liu, H., Zhou, S.: A Barzilai–Borwein type method for stochastic linear complementarity problems. Numer. Algorithm 67(3), 477–489 (2014)
Huang, Y., Liu, H., Zhou, S.: Quadratic regularization projected Barzilai–Borwein method for nonnegative matrix factorization. Data Min. Knowl. Disc. 29(6), 1665–1684 (2015)
Jiang, B., Ma, S., So, A.M.C., Zhang, S.: Vector transport-free SVRG with general retraction for riemannian optimization: complexity analysis and practical implementation. arXiv preprint arXiv:1705.09059 (2017)
Johnson, R., Zhang, T.: Accelerating stochastic gradient descent using predictive variance reduction. In: Proc. 26th Int. Conf. Adv. Neural Inf. Process. Syst., pp. 315–323 (2013)
Konečnỳ, J., Liu, J., Richtárik, P., Takáč, M.: Mini-batch semi-stochastic gradient descent in the proximal setting. IEEE J. Sel. Top. Signal Process. 10(2), 242–255 (2016)
Konečnỳ, J., Richtárik, P.: Semi-stochastic gradient descent methods. Front. Appl. Math. Stat. 3, 9 (2017)
Kronvall, T., Adalbjörnsson, S.I., Nadig, S., Jakobsson, A.: Group-sparse regression using the covariance fitting criterion. Signal Process. 139, 116–130 (2017)
Li, X.L.: Preconditioned stochastic gradient descent. IEEE Trans. Neural Netw. Learn. Syst. 29(5), 1454–1466 (2018)
Mairal, J.: Incremental majorization-minimization optimization with application to large-scale machine learning. SIAM J. Optim. 25(2), 829–855 (2015)
Mairal, J., Bach, F., Ponce, J., Sapiro, G.: Online dictionary learning for sparse coding. In: Proc. 26th Int. Conf. Mach. Learn., pp. 689–696 (2009)
Mu, Y., Liu, W., Liu, X., Fan, W.: Stochastic gradient made stable: a manifold propagation approach for large-scale optimization. IEEE Trans. Knowl. Data Eng. 29(2), 458–471 (2017)
Nesterov, Y.: Introductory Lectures on Convex Programming, vol. 1. Springer Science, New York (2004)
Nguyen, L.M., Liu, J., Scheinberg, K., Takáč, M.: Sarah: a novel method for machine learning problems using stochastic recursive gradient. In: Int. Conf. Mach. Learn., pp. 2613–2621 (2017)
Rakhlin, A., Shamir, O., Sridharan, K., et al.: Making gradient descent optimal for strongly convex stochastic optimization. In: Int. Conf. Mach. Learn., pp. 1571–1578 (2012)
Robbins, H., Monro, S.: A stochastic approximation method. Ann. Math. Stat. pp. 400–407 (1951)
Roux, N.L., Schmidt, M., Bach, F.R.: A stochastic gradient method with an exponential convergence rate for finite training sets. In: Proc. 25th Int. Conf. Adv. Neural Inf. Process. Syst., pp. 2663–2671 (2012)
Shalev-Shwartz, S., Ben-David, S.: Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press, Cambridge (2014)
Sutskever, I., Martens, J., Dahl, G., Hinton, G.: On the importance of initialization and momentum in deep learning. In: Int. Conf. Mach. Learn., pp. 1139–1147 (2013)
Tan, C., Ma, S., Dai, Y.H., Qian, Y.: Barzilai–Borwein step size for stochastic gradient descent. In: Proc. 29th Int. Conf. Adv. Neural Inf. Process. Syst., pp. 685–693 (2016)
Wang, X., Ma, S., Goldfarb, D., Liu, W.: Stochastic quasi-Newton methods for nonconvex stochastic optimization. SIAM J. Optim. 27(2), 927–956 (2017)
Wen, Z., Yin, W., Goldfarb, D., Zhang, Y.: A fast algorithm for sparse reconstruction based on shrinkage, subspace optimization, and continuation. SIAM J. Sci. Comput. 32(4), 1832–1857 (2010)
Xiao, L., Zhang, T.: A proximal stochastic gradient method with progressive variance reduction. SIAM J. Optim. 24(4), 2057–2075 (2014)
Yang, Z., Wang, C., Zang, Y., Li, J.: Mini-batch algorithms with Barzilai–Borwein update step. Neurocomputing 314, 177–185 (2018)
Yang, Z., Wang, C., Zhang, Z., Li, J.: Accelerated stochastic gradient descent with step size selection rules. Signal Process. 159, 171–186 (2019)
Yuan, Y.-X.: Recent advances in trust region algorithms. Math. Program. 151(1), 249–281 (2015)
Zhang, L., Mahdavi, M., Jin, R.: Linear convergence with condition number independent access of full gradients. In: Proc. 26th Int. Conf. Adv. Neural Inf. Process. Syst., pp. 980–988 (2013)
Zhang, T.: Solving large scale linear prediction problems using stochastic gradient descent algorithms. In: Int. Conf. Mach. Learn. (2004)
Zhao, P., Zhang, T.: Stochastic optimization with importance sampling for regularized loss minimization. In: Int. Conf. Mach. Learn., pp. 1–9 (2015)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The research is in part by the Chinese NSF under Grants 11671116, 11701137, 12071108, 11631013, 11991020, and 12021001; in part by the Major Research Plan of the NSFC under Grants 91630202, and in part by the Beijing Academy of Artificial Intelligence (BAAI).
Rights and permissions
About this article

Cite this article
Yu, T., Liu, XW., Dai, YH. et al. Stochastic Variance Reduced Gradient Methods Using a Trust-Region-Like Scheme. J Sci Comput 87, 5 (2021). https://doi.org/10.1007/s10915-020-01402-x
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10915-020-01402-x
Keywords
- Stochastic variance reduced gradient
- Trust region
- Barzilai–Borwein stepsizes
- Mini-batches
- Empirical risk minimization