
Abstract
We consider a distributionally robust formulation of stochastic optimization problems arising in statistical learning, where robustness is with respect to ambiguity in the underlying data distribution. Our formulation builds on risk-averse optimization techniques and the theory of coherent risk measures. It uses mean–semideviation risk for quantifying uncertainty, allowing us to compute solutions that are robust against perturbations in the population data distribution. We consider a broad class of generalized differentiable loss functions that can be non-convex and non-smooth, involving upward and downward cusps, and we develop an efficient stochastic subgradient method for distributionally robust problems with such functions. We prove that it converges to a point satisfying the optimality conditions. To our knowledge, this is the first method with rigorous convergence guarantees in the context of generalized differentiable non-convex and non-smooth distributionally robust stochastic optimization. Our method allows for the control of the desired level of robustness with little extra computational cost compared to population risk minimization with stochastic gradient methods. We also illustrate the performance of our algorithm on real datasets arising in convex and non-convex supervised learning problems.



Similar content being viewed by others

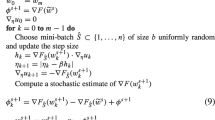
Notes
From the update rule of \(y^k\), it follows that the variable \(y^k\) is the projection of \(x^k-z^k/c\) onto the constraint set X, where 1/c can be interpreted as the stepsize. This projection step ensures that the iterates \(y^k\) lie in the constraint set X.
This statement follows from the following argument: If \(x^*\in X^*\), then by definition (17), there exists \(z^*\in \hat{\partial } F(x^*)\) such that \(-z^*\in N_X(x^*)\), which is equivalent to \(\langle z^*, y-x^*\rangle \ge 0\) for every \(y \in X\). This, together with the definition (18) of the gap function, implies that \(\eta (x^*,z^*)\ge 0\), which yields \(\eta (x^*,z^*) = 0\), due to (20). The other direction can be proved in a similar way. If \(z^*\in \hat{\partial } F(x^*)\) exists such that \(\eta (x^*,z^*)=0\), then by definition (18), \(\langle z^*, y-x^*\rangle \ge 0\) for every \(y \in X\); otherwise, one gets a contradiction. The latter statement is equivalent to \(-z^* \in N_X(x^*)\), and consequently, we obtain \(x^*\in X\).
Notice that in the definition of \(\ell _{2c}\), we have necessarily \(p_2 - \varkappa p_1 - g_{au}>0\) as \(p_2>0\) and \(-\varkappa p_1 - g_{au} \ge 0\) by (25). Similarly, \(p_2 - \varkappa p_1 - g_{bu}>0\). Therefore, the denominator \(p_2 - \varkappa p_1 - sg_{au} - (1-s)g_{bu}>0\).
References
Allen-Zhu, Z., Elad, H.: Variance reduction for faster non-convex optimization. In: Maria Florina, B., Weinberger, K.Q. (eds.) Proceedings of The 33rd International Conference on Machine Learning, vol. 48 of Proceedings of Machine Learning Research, pp. 699–707. New York, New York, USA, 20–22 Jun 2016. PMLR
Artzner, P., Delbaen, F., Eber, J.-M., Heath, D.: Coherent measures of risk. Math. Finance 9, 203–228 (1999)
Baker, J.W., Schubert, M., Faber, M.H.: On the assessment of robustness. Struct. Safety 30(3), 253–267 (2008)
Bonnans, J.F., Alexander, S.: Perturbation Analysis of Optimization Problems. Springer (2013)
Brézis, H.: Monotonicity methods in Hilbert spaces and some applications to nonlinear partial differential equations. In: Contributions to Nonlinear Functional Analysis, pp. 101–156. Elsevier (1971)
Bubeck, S.: Convex optimization: Algorithms and complexity. Found. Trends \({\mathring{R}}\) Mach. Learn. 8(3–4), 231–357 (2015)
Clarke, F.H.: Generalized gradients and applications. Trans. Am. Math. Soc. 205, 247–262 (1975)
Daszykowski, M., Kaczmarek, K., Vander Heyden, Y., Walczak, B.: Robust statistics in data analysis—a review: basic concepts. Chemometr. Intell. Lab. Syst. 85(2), 203–219 (2007)
Davis, D., Drusvyatskiy, D.: Stochastic model-based minimization of weakly convex functions. SIAM J. Optim. 29(1), 207–239 (2019)
Dentcheva, D., Penev, S., Ruszczyński, A.: Statistical estimation of composite risk functionals and risk optimization problems. Ann. Inst. Stat. Math. 69(4), 737–760 (2017)
Drusvyatskiy, D., Ioffe, A.D., Lewis, A.S.: Curves of descent. SIAM J. Control Optim. 53(1), 114–138 (2015)
Dheeru, D., Casey, G.: UCI Machine Learning Repository (2017) https://archive.ics.uci.edu/ml/index.php
Duchi, J.C., Ruan, F.: Stochastic methods for composite and weakly convex optimization problems. SIAM J. Optim. 28(4), 3229–3259 (2018)
Duchi, J.C., Namkoong, H.: Learning models with uniform performance via distributionally robust optimization. Ann. Stat. 49(3), 1378–1406 (2021)
Ermoliev, Y.M.: Methods of Stochastic Programming. Nauka, Moscow (1976)
Ermoliev, Y.M., Norkin, V.I.: Sample average approximation method for compound stochastic optimization problems. SIAM J. Optim. 23(4), 2231–2263 (2013)
Esfahani, P.M., Kuhn, D.: Data-driven distributionally robust optimization using the Wasserstein metric: performance guarantees and tractable reformulations. Math. Program. 171(1–2), 115–166 (2018)
Föllmer, H., Schied, A.: Stochastic Finance: An Introduction in Discrete Time. Walter de Gruyter (2011)
Foster, D.J., Sekhari, A., Sridharan, K.: Uniform convergence of gradients for non-convex learning and optimization. In: Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R. (eds.) Advances in Neural Information Processing Systems, vol. 31, pp. 8745–8756. Curran Associates, Inc. (2018)
Gao, R., Chen, X., Kleywegt, A.J.: Wasserstein distributional robustness and regularization in statistical learning (2017). arXiv preprint arXiv:1712.06050
Gao, R., Kleywegt, A.J.: Distributionally robust stochastic optimization with Wasserstein distance (2016). arXiv preprint arXiv:1604.02199. https://arxiv.org/pdf/1712.06050.pdf
Ghadimi, S., Lan, G.: Optimal stochastic approximation algorithms for strongly convex stochastic composite optimization, ii: shrinking procedures and optimal algorithms. SIAM J. Optim. 23(4), 2061–2089 (2013)
Ghadimi, S., Ruszczynski, A., Wang, M.: A single timescale stochastic approximation method for nested stochastic optimization. SIAM J. Optim. 30(1), 960–979 (2020)
Goodfellow, I., Yoshua, B., Aaron, C.: Deep Learning. MIT Press (2016)
Goodfellow, I.J, Shlens, J., Szegedy, C.: Explaining and harnessing adversarial examples (2014). arXiv preprint arXiv:1412.6572
Hastie, T., Tibshirani, R., Wainwright, M.: The Lasso and Generalizations. CRC Press, Statistical learning with sparsity (2015)
Jain, P., Kakade, S.M., Kidambi, R., Netrapalli, P., Sidford, A.: Accelerating stochastic gradient descent for least squares regression. In: Sébastien, B., Vianney, P., Philippe, R. (eds.) Proceedings of the 31st Conference On Learning Theory, vol. 75 of Proceedings of Machine Learning Research, pp. 545–604 (2018) (PMLR, 06–09 Jul 2018)
Kalogerias, D.S., Powell, W.B.: Recursive optimization of convex risk measures: mean-semideviation models (2018). arXiv preprint arXiv:1804.00636
Krizhevsky, A.: Learning multiple layers of features from tiny images. Technical report, University of Toronto (2009)
Kuhn, D., Peyman Mohajerin, E., Viet Anh, N., Soroosh, S.-A.: Wasserstein distributionally robust optimization: theory and applications in machine learning. In: Operations Research & Management Science in the Age of Analytics, pp. 130–166. INFORMS (2019)
Kurakin, A., Ian, G., Samy, B.: Adversarial machine learning at scale (2016). arXiv preprint arXiv:1611.01236
Kushner, H., Yin, G.G.: Stochastic Approximation Algorithms and Applications. Springer, New York (2003)
LeCun, Y.L., Corinna, C., Burges, C.J.: MNIST handwritten digit database. ATT Labs 2 (2010). http://yann.lecun.com/exdb/mnist
Li, X., Zhihui, Z., Anthony, M.-C.S., Lee, J.D.: Incremental Methods for Weakly Convex Optimization (2019). arXiv e-prints arXiv:1907.11687
Madry, A., Aleksandar, M., Ludwig, S., Dimitris, T., Adrian, V.: Towards deep learning models resistant to adversarial attacks (2017). arXiv preprint arXiv:1706.06083
Majewski, S., Miasojedow, B., Moulines, E.: Analysis of nonsmooth stochastic approximation: the differential inclusion approach (20118). arXiv preprint arXiv:1805.01916
Mehrotra, S., Zhang, H.: Models and algorithms for distributionally robust least squares problems. Math. Program. 146(1), 123–141 (2014)
Mei, S., Yu, B., Andrea, M.: The landscape of empirical risk for nonconvex losses. Ann. Stat. 46(6A), 2747–2774 (2018)
Mifflin, R.: Semismooth and semiconvex functions in constrained optimization. SIAM J. Control Optim. 15(6), 959–972 (1977)
Mikhalevich, V.S., Gupal, A.M., Norkin, V.I.: Nonconvex Optimization Methods. Nauka, Moscow (1987)
Namkoong, H., Duchi, J.C: Stochastic gradient methods for distributionally robust optimization with f-divergences. In: Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R. (eds.) Advances in Neural Information Processing Systems, vol. 29. Curran Associates, Inc. (2016)
Norkin, V.I.: Generalized-differentiable functions. Cybern. Syst. Anal. 16(1), 10–12 (1980)
Ogryczak, W., Ruszczyński, A.: From stochastic dominance to mean-risk models: semideviations as risk measures. Eur. J. Oper. Res. 116, 33–50 (1999)
Ogryczak, W., Ruszczyński, A.: On consistency of stochastic dominance and mean-semideviation models. Math. Program. 89, 217–232 (2001)
Postek, K., den Hertog, D., Melenberg, B.: Computationally tractable counterparts of distributionally robust constraints on risk measures. SIAM Rev. 58(4), 603–650 (2016)
Robbins, H., Monro, S.: A stochastic approximation method. Ann. Math. Stat. 400–407 (1951)
Ruszczyński, A.: A linearization method for nonsmooth stochastic programming problems. Math. Oper. Res. 12(1), 32–49 (1987)
Ruszczyński, A., Shapiro, A.: Optimization of convex risk functions. Math. Oper. Res. 31, 433–452 (2006)
Ruszczyński, A.: Convergence of a stochastic subgradient method with averaging for nonsmooth nonconvex constrained optimization. Optim. Lett. 14, 1615–1625 (2020)
Ruszczynski, A.: A stochastic subgradient method for nonsmooth nonconvex multilevel composition optimization. SIAM J. Control Optim. 59(3), 2301–2320 (2021)
Seidman, J.H., Fazlyab, M., Preciado, V.M., Pappas, G.J.: Robust deep learning as optimal control: Insights and convergence guarantees. In: Bayen, A.M., Jadbabaie, A., Pappas, G., Parrilo, P.A., Benjamin, R., Claire, T., Melanie, Z. (eds.) Proceedings of the 2nd Conference on Learning for Dynamics and Control, vol. 120 of Proceedings of Machine Learning Research, pp. 884–893. PMLR, 10–11 (2020)
Soroosh, S.-A., Peyman, M., Esfahani, D.K.: Distributionally robust logistic regression. In: Proceedings of the 28th International Conference on Neural Information Processing Systems—vol. 1. NIPS’15, pp. 1576–1584. Cambridge, MA, USA, 2015. MIT Press (2015)
Shai, S.-S., Shai, B.-D.: Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press (2014)
Shapiro, A., Dentcheva, D., Ruszczyński, A.: Lectures on Stochastic Programming: Modeling and Theory. SIAM, Philadelphia (2009)
Sinha, A., Hongseok, N., John, D.: Certifying some distributional robustness with principled adversarial training. In: International Conference on Learning Representations (2018). https://openreview.net/forum?id=Hk6kPgZA-
Soma, T., Yuichi, Y.: Statistical learning with conditional value at risk (2020). arXiv preprint arXiv:2002.05826
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.: Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15(56), 1929–1958 (2014)
Takeda, A., Kanamori, T.: A robust approach based on conditional value-at-risk measure to statistical learning problems. Eur. J. Oper. Res. 198(1), 287–296 (2009)
Teo, C.H., Vishwanthan, S.V.N., Smola, Alex J., Le, Quoc V.: Bundle methods for regularized risk minimization. J. Mach. Learn. Res. 11(10), 311–365 (2010)
Vladimir, V.: The Nature of Statistical Learning Theory. Springer Science & Business Media (2013)
Wang, M., Fang, E.X., Liu, B.: Stochastic compositional gradient descent: algorithms for minimizing compositions of expected-value functions. Math. Program. 161(1–2), 419–449 (2017)
Wang, M., Liu, J., Fang, E.X.: Accelerating stochastic composition optimization. J. Mach. Learn. Res. 18, 1–23 (2017)
Yang, S., Wang, M., Fang, E.X.: Multilevel stochastic gradient methods for nested composition optimization. SIAM J. Optim. 29(1), 616–659 (2019)
Zhang, D., Tianyuan, Z., Yiping, L., Zhanxing, Z., Bin, D.: You only propagate once: Accelerating adversarial training via maximal principle. In: Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché Buc, F., Fox, E., Garnett, R. (eds.) Advances in Neural Information Processing Systems, vol. 32. Curran Associates, Inc. (2019)
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Zaid Harchaoui.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was partially supported by the National Science Foundation Awards DMS-1907522, CCF-1814888, and DMS-2053485, and by the Office of Naval Research Awards N00014-21-1-2161 and N00014-21-1-2244.
Appendices
Appendix A: Generalized Differentiability of Functions
Norkin [42] introduced the following class of functions.
Definition A.1
A function \(f:\mathbbm {R}^n\rightarrow \mathbbm {R}\) is differentiable in a generalized sense at a point \(x\in \mathbbm {R}^n\), if an open set \(U\subset \mathbbm {R}^n\) containing x, and a non-empty, convex, compact valued, and upper semicontinuous multifunction \(\hat{\partial } f: U \rightrightarrows \mathbbm {R}^n\) exist, such that for all \(y\in U\) and all \(g \in \hat{\partial } f(y)\) the following equation is true:
with
The set \(\hat{\partial } f(y)\) is the generalized subdifferential of f at y. If a function is differentiable in a generalized sense at every \(x \in \mathbbm {R}^n\) with the same generalized subdifferential mapping \(\hat{\partial } f:\mathbbm {R}^n\rightrightarrows \mathbbm {R}^n\), we call it differentiable in a generalized sense.
A function \(f:\mathbbm {R}^n\rightarrow \mathbbm {R}^m\) is differentiable in a generalized sense, if each of its component functions, \(f_i:\mathbbm {R}^n\rightarrow \mathbbm {R}\), \(i=1,\dots ,m\), has this property.
The class of such functions is contained in the set of locally Lipschitz functions and contains all subdifferentially regular functions [7], Whitney stratifiable Lipschitz functions [11], semismooth functions [39], and their compositions. The Clarke subdifferential \(\partial \! f(x)\) is an inclusion-minimal generalized subdifferential, but the generalized sub-differential mapping \(\hat{\partial } f(\cdot )\) is not uniquely defined in Definition A.1. However, if \(f:\mathbbm {R}^n\rightarrow \mathbbm {R}\) is differentiable in a generalized sense, then for almost all \(x\in \mathbbm {R}^n\) we have \(\hat{\partial } f(x)=\{\nabla f(x)\}\).
Compositions of generalized differentiable functions are crucial in our analysis.
Theorem A.1
[40, Thm. 1.6] If \(h:\mathbbm {R}^m \rightarrow \mathbbm {R}\) and \(f_i:\mathbbm {R}^n\rightarrow \mathbbm {R}\), \(i=1,\dots ,m\), are differentiable in a generalized sense, then the composition \(\psi (x) = h\big ( f_1(x),\dots ,f_m(x)\big )\) is differentiable in a generalized sense, and at any point \(x\in \mathbbm {R}^n\) we can define the generalized subdifferential of \(\psi \) as follows:
Even if we take \(\hat{\partial }{h}(\cdot )=\partial h(\cdot )\) and \(\hat{\partial }{f_j}(\cdot )=\partial \! f_j(\cdot )\), \(j=1,\dots ,m\), we may obtain \(\hat{\partial }\psi (\cdot ) \ne \partial \psi (\cdot )\), but \(\hat{\partial }\psi \) defined above satisfies Definition A.1.
For stochastic optimization, essential is the closure of the class functions differentiable in a generalized sense with respect to expectation.
Theorem A.2
[40, Thm. 23.1] Suppose \((\varOmega ,\mathcal {F},P)\) is a probability space and a function \(f:\mathbbm {R}^n\times \varOmega \rightarrow \mathbbm {R}\) is differentiable in a generalized sense with respect to x for all \(\omega \in \varOmega \) and integrable with respect to \(\omega \) for all \(x\in \mathbbm {R}^n\). Let \(\hat{\partial } f: \mathbbm {R}^n \times \varOmega \rightrightarrows \mathbbm {R}^n\) be a multifunction, which is measurable with respect to \(\omega \) for all \(x\in \mathbbm {R}^n\), and which is a generalized subdifferential mapping of \(f(\cdot ,\omega )\) for all \(\omega \in \varOmega \). If for every compact set \(K\subset \mathbbm {R}^n\) an integrable function \(L_K:\varOmega \rightarrow \mathbbm {R}\) exists, such that \(\sup _{x\in K}\sup _{g\in \hat{\partial } f(x,\omega )}\Vert g\Vert \le L_K(\omega )\), \(\omega \in \varOmega \), then the function
is differentiable in a generalized sense, and the multifunction
is its generalized subdifferential mapping.
A key step in the analysis of stochastic recursive algorithms by the differential inclusion method is the chain rule on a path (see [9] and the references therein). For an absolutely continuous function \(p:[0,\infty )\rightarrow \mathbbm {R}^n\), we denote by \(\overset{{{\;\,}_\bullet }}{p}(\cdot )\) its weak derivative: a measurable function such that
Theorem A.3
[49, Thm. 1] If a function \(f:\mathbbm {R}^n \rightarrow \mathbbm {R}^m\) and a path \(p:[0,\infty )\rightarrow \mathbbm {R}^n\) are differentiable in a generalized sense, then
for all selections \(g(\cdot ) \in \hat{\partial } f(\cdot )\), and all \(T>0\).
Appendix B: Proof of Lemma 3.3
Proof
Formula (13) and assumptions (A4)(ii) and (iii) yield:
with the errors
Due to assumption (A4), for some constant \(C_u^{\theta }\),
and
To verify the boundedness of \(\{u^k\}\), we define the quantities
Owing to (A3) and (44), by virtue of the martingale convergence theorem, the series in the formula above is convergent a.s., and thus, \(\tilde{u}^k - u^k \rightarrow 0\) a.s., when \(k\rightarrow \infty \). We can now use (43) to establish the following recursive relation:
By (A1), the sequences \(\{J^k\}\) and \(\{h(x^k)\}\) are bounded. Since \(\tilde{u}^k - u^k \rightarrow 0\) and \(\epsilon _u^{k}\rightarrow 0\) a.s., the elements in the brackets in the formula above constitute an almost surely bounded sequence. Consequently, the sequence \(\{\tilde{u}^k\}\) of their convex combinations is almost surely bounded as well. The same is true for the sequence \(\{{u}^k\}\), because \(\tilde{u}^k - u^k \rightarrow 0\) a.s.
The boundedness of \(\{z^k\}\) can be established in a similar way. We rewrite (12) as
with the errors
Due to assumption (A4) (note the statistical independence of \({E}^{\,k+1}\) and \( e_{gu}^{k+1}\)), for some constant \(C_z^{\theta }\),
and
The remaining proof is the same as that for \(\{u^k\}\), with relation (45) replacing (43). \(\square \)
Rights and permissions
About this article

Cite this article
Gürbüzbalaban, M., Ruszczyński, A. & Zhu, L. A Stochastic Subgradient Method for Distributionally Robust Non-convex and Non-smooth Learning. J Optim Theory Appl 194, 1014–1041 (2022). https://doi.org/10.1007/s10957-022-02063-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10957-022-02063-6
Keywords
- Robust learning
- Risk measures
- Stochastic subgradient method
- Non-smooth optimization
- Composition optimization