
Abstract
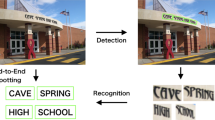
Video text often contains highly useful semantic information that can contribute significantly to video retrieval and understanding. Video text can be classified into scene text and superimposed text. Most of the previous methods detect superimposed or scene text separately due to different text alignments. Moreover, because different language characters have different edge and texture features, it is very difficult to detect the multilingual text. In this paper, we first perform a detailed analysis of motion patterns of video text, and show that the superimposed and scene text exhibit different motion patterns on consecutive frames, which is insensitive to multiple language characters and multiple text alignments. Based on our analysis, we define Motion Perception Field (MPF) to represent the text motion patterns. Finally, we propose a text detection algorithms using MPF for both superimposed and scene text with multiple languages and multiple alignments. Experimental results on diverse videos demonstrate that our algorithms are robust, and outperform previous methods for detecting both superimposed and scene texts with multiple languages and multiple alignments.















Similar content being viewed by others


Notes
China Central Television, or CCTV, is a national television station of the People’s Republic of China. It was on its trial broadcast on May 1st, 1958, and formally launched on September 2nd of the year. As the most important medium in China, CCTV not only provides information to general public throughout China, but also works as an open window between China and the rest of the world.
References
Barron JL, Fleet DJ, Beauchemin S (1994) Performance of optical flow techniques. Int J Comp Vision 12:43–77
Boreczky JS, Wilcox LD (1998) A hidden markov model framework for video segmentation using audio and image features. Proc ICASSP’98. Seattle, WA, May. pp 3741–3744
CCTV channel website: “http://cctv.cntv.cn/”
Chen X, Yang J, Zhang J, Waibel A (2004) Automatic detection and recognition of signs from natural scenes. IEEE Trans IP 13(1):87–99
Di Zenzo S (1986) A note on the gradient of a multi-image. Comp Vision Graph Image Process 33(1):116–125
Gao J, Yang J (2001) An adaptive algorithm for text detection from Natural scenes. Proc CVPR 1:84–89
Goto H (2008) Redefining the DCT-based feature for scene text detection: analysis and comparison of spatial frequency-based features. Int J Doc Anal Recognit 11(1):1–8
Harris C, Stephens M (1988) A combined corner and edge detector. Fourth Alvey Vision Conf 147–151
Horn BKP (1986) Robot vision, Chapter 12. MIT Press
Hua X-S, Chert X-R, Wenyin L, Zhang H-J (2001) Automatic location of text in video frames. Proceedings of the 2001 ACM workshops on Multimedia. Sept: 24–27
Hua X, Yin P, Zhang HJ (2002) Efficient video text recognition using multiple frame integration. IEEE Int Conf Image Process (ICIP) 2:397–400
Huang X, Ma H, Yuan H (2008) A novel video text detection and localization approach. IEEE Pac Rim Conf Multimed (PCM) 525–534
Kim KI, Jung K, Kim JH (2003) Texture-based approach for text detection in images using support vector machines and continuously adaptive mean shift algorithm. IEEE Trans PAMI 25(12):1631–1639
Kim KC, Byun HR, Song YJ, Choi YW, Chi SY, Kim KK, Chung YK (2004) Scene text extraction in natural scene images using hierarchical feature combining and verification. ICPR 2:679–682
Li H, Doermann D (2000) A video text detection system based on automated training. ICPR 2:223–226
Li H, Doermann D, Kia O (2000) Automatic text detection and tracking in digital video. IEEE Trans IP 9(1):147–156
Lyu MR, Song J, Cai M (2005) A comprehensive method for multilingual video text detection, localization, and extraction. IEEE Trans CSVT 15(2):243–255
Mariano VY, Kasturi R (2000) Locating uniform-colored text in video frames. ICPR 4:539–542
Miao G, Huang Q, Jiang S, Gao W (2008) Coarse-to-fine video text detection. ICME 569–572
Sato T, Kanade T, Hughes E, Smith M, Satoh S (1998) Video OCR: Indexing Digital News Libraries by Recognition of Superimposed Caption. ACM Multimedia Systems Special Issue on Video Libraries. February
Shivakumara P, Phan TQ, Tan CL (2009) A gradient difference based technique for video text detection. Proc IEEE ICDAR 156–160
Sin B-K, Kim S-K, Cho B-J (2002) Locating characters in scene images using frequency features. Proc Int Conf Pattern Recog 3:489–492
Singh A (1992) Optic flow computation: a unified perspective. IEEE Comput Soc Press
Soffer A (1997) Image categorization using texture features. ICDAR 1:233–237
Wang Y-K, Chen J-M (2006) Detecting video texts using spatial-temporal wavelet transform. ICPR 4:754–757
Wang R, Jin W, Wu L (2004) A novel video caption detection approach using multi-frame integration. ICPR 1:449–452
Winger LL, Robinson JA, Jernigan ME (2000) Low-complexity character extraction in low-contrast scene images. Int J Pattern Recognit Artif Intell 14(2):113–135
Ye Q, Huang Q (2004) A New text detection algorithm in images/video frames. PCM, LNCS 3332:858–865
Yi J, Peng Y, Xiao J (2007) Color-based clustering for text detection and extraction in image. ACM MM 847–850
Acknowledgment
The authors would like to thank the reviewers for their thorough comments and suggestions that helped to improve this paper. This work is supported by the National Natural Science Foundation for Distinguished Young Scholars under Grant No. 60925010; the National Natural Science Foundation of China under Grant No. 60833009; the Cosponsored Project of Beijing Committee of Education, the Funds for Creative Research Groups of China under Grant No.61121001, and the Program for Changjiang Scholars and Innovative Research Team in University under Grant No.IRT1049.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Huang, X., Ma, H., Ling, C.X. et al. Detecting both superimposed and scene text with multiple languages and multiple alignments in video. Multimed Tools Appl 70, 1703–1727 (2014). https://doi.org/10.1007/s11042-012-1201-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-012-1201-2