
Abstract
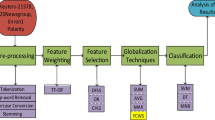
This paper proposes an effective method to extract printed and handwritten characters from multilingual document images to build corpus. To extract the characters from the document images, a connected component analysis method is used to remove the graphics. After that, multiple types of features and AdaBoost algorithm are introduced to classify printed and handwritten characters in a more versatile and robust way. Firstly, the content of the image is divided into several text patches which are then used to distinguish different languages. Secondly, we use the multiple types of features and AdaBoost algorithm to train the classifiers based on the segmented patches. Finally, we can separate printed and handwritten parts of new image set by the trained classifiers. The proposed method improves the precision of the extraction of written materials in text images of different languages. Experimental results demonstrate that the proposed method is more accurate in terms of precision and recall rate compared with the state-of the-art methods.











Similar content being viewed by others

References
Agam, G., Argamon, S., Frieder, O., Grossman, D., Lewis, D.: The complex document image processing (CDIP) test collection. Illinois Inst Technol (2006)
Anthony L (2013) A critical look at software tools in corpus linguistics. Linguist Res 30(2):141–161
Busch A, Boles WW, Sridharan S (2005) Texture for script identification. IEEE Trans Pattern Anal Mach Intel 27(11):1720–1732
Chellappa R, Chatterjee S (1985) Classification of textures using Gaussian Markov random fields. IEEE Trans Acoust, Speech Signal Process 33(4):959–963
Drivas, D., Amin, A.: Page segmentation and classification utilising a bottom-up approach. In: Proceedings of the Third International Conference on Document Analysis and Recognition, pp. 610–614. (1995)
Fan K, Wang L, Tu Y (1998) Classification of machine-printed and handwritten texts using character block layout variance. Pattern Recogn 31(9):1275–1284
Franke, J., Oberlander, M.: Writing style detection by statistical combination of classifiers in form reader applications. In: Proceedings of the Second International Conference on Document Analysis and Recognition, pp. 581–584. (1993)
Gao Y, Wang M, Tao D, Ji R, Dai Q (2012) 3D object retrieval and recognition with hypergraph analysis. IEEE Trans Image Process 21(9):4290–4303
Gao Y, Wang M, Zha Z, Shen J, Li X, Wu X (2013) Visual-textual joint relevance learning for tag-based social image search. IEEE Trans Image Process 22(1):363–376
Gatos B, Stamatopoulos N, Louloudis G (2011) ICDAR2009 handwriting segmentation contest. IJDAR 14(1):25–33
Guo, J.K., Ma, M.Y.: Separating handwritten material from machine printed text using hidden Markov models. In: Proceedings of Sixth International Conference on Document Analysis and Recognition, pp. 439–443. (2001)
Hochberg, J., Kerns, L., Kelly, P., Thomas, T.: Automatic script identification from images using cluster-based templates. In: Proceedings of the Third International Conference on Document Analysis and Recognition, pp. 378–381. (1995)
Jain AK, Zhong Y (1996) Page segmentation using texture analysis. Pattern Recogn 29(5):743–770
Johansson S (2002) Towards a multilingual corpus for contrastive analysis and translation studies. Lang Comput 43(1):47–59
Koyama, J., Kato, M., Hirose, A.: Handwritten character distinction method inspired by human vision mechanism. In: Proceedings of Neural Information Processing, pp. 1031–1040. (2008)
Kuhnke, K., Simoncini, L., Kovacs-V, Z.M.: A system for machine-written and hand-written character distinction. In: Proceedings of the Third International Conference on Document Analysis and Recognition, pp. 811–814. (1995)
Kundu, A., He, Y., Bahl, P.: Recognition of handwritten word: first and second order hidden Markov model based approach. In: Proceedings of Computer Vision and Pattern Recognition (CVPR), pp. 457–462. (1988)
Lewis D, Agam G, Argamon S, Frieder O, Grossman D, Heard J (2006) Building a test collection for complex document information processing. In: Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval, pp. 665–666
Liu Q, Zha Z, Yang Y (2014) Gradient-domain-based enhancement of multi-view depth video. Inf Sci 281:750–761
Maguire P, Wisniewski EJ, Storms G (2010) A corpus study of semantic patterns in compounding. Corpus Linguist Linguist Theory 6:49–73
Pal U, Chaudhuri BB (2001) Machine-printed and hand-written text lines identification. Pattern Recogn Lett 22(3–4):431–441
Soffer, A.: Image categorization using texture features. In: Proceedings of the Fourth International Conference on Document Analysis and Recognition, pp. 233–237. (1997)
Srihari SN, Shin YC, Ramanaprasad V, Lee DS (1996) A system to read names and addresses on tax forms. Proceedings of the IEEE 84(7):1038–1049
Tan TN (1998) Rotation invariant texture features and their use in automatic script identification. IEEE Transact Pattern Anal Mach Intell 20(7):751–756
Vyatkina N (2014) Review of multilingual corpora and multilingual corpus analysis. Lang Learn Technol 18(2):70–74
Zheng Y, Liu C, Ding X (2001) Single-character type identification. In: Proceedings of SPIE Conference Document Recognition and Retrieval, pp. 49–56
Zheng Y, Li H, Doermann D (2002) The segmentation and identification of handwriting in noisy document images. In: Proceedings of the 5th International Workshop on Document Analysis Systems, pp. 95–105
Zheng Y, Li H, Doermann D (2004) Machine printed text and handwriting identification in noisy document images. IEEE Trans Pattern Anal Mach Intell 26(3):337–353
Acknowledgments
This work was supported by Shaanxi Social Science Foundation of China under Grant Nos. 13 K093 and 2015 K014, National Social Science Foundation of China under Grant No. 12BYY055, Shaanxi Twelfth Year Planning Foundation of China under Grant No. SGH13015, Social Science Foundation of Ministry of Education of China under Grant No.15YJA740016 and the Fundamental Research Funds for the Central Universities under Grant No. Sk2013008.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Lin, Y., Song, Y., Li, Y. et al. Multilingual corpus construction based on printed and handwritten character separation. Multimed Tools Appl 76, 4123–4139 (2017). https://doi.org/10.1007/s11042-015-2995-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-015-2995-5