
Abstract
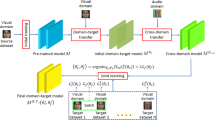
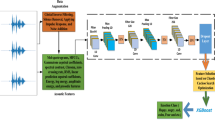
Research in emotion recognition seeks to develop insights into the variances of features of emotion in one common domain. However, automatic emotion recognition from speech is challenging when training data and test data are drawn from different domains due to different recording conditions, languages, speakers and many other factors. In this paper, we propose a novel feature transfer approach with PCANet (a deep network), which extracts both the domain-shared and the domain-specific latent features to facilitate performance improvement. The proposal attempts to learn multiple intermediate feature representations along an interpolating path between the source and target domains using PCANet by considering the distribution shift between source domain and target domain, and then aligns other feature representations on the path with target subspace to control them to change in the right direction towards the target. To exemplify the effectiveness of our approach, we select the INTERSPEECH 2009 Emotion Challenge’s FAU Aibo Emotion Corpus as the target database and two public databases (ABC and Emo-DB) as source set. Experimental results demonstrate that the proposed feature transfer learning method outperforms the conventional machine learning methods and other transfer learning methods on the performance.




Similar content being viewed by others

References
Abdel-Hamid O, Mohamed A, Jiang H, Penn G (2012) Applying convolutional neural networks concepts to hybrid nn-hmm model for speech recognition. In: 2012 IEEE international conference on Acoustics, speech and signal processing (ICASSP), pp 4277–4280
Bengio Y (2012) Deep learning of representations for unsupervised and transfer learning. In: Unsupervised and transfer learning challenges in machine learning, vol 7, p 19
Burkhardt F, Paeschke A, Rolfes M, Sendlmeier W, Weiss B (2005) A database of german emotional speech, vol 5
Chan TH, Jia K, Gao S, Lu J, Zeng Z, Pcanet MY (2014) A simple deep learning baseline for image classification? arXiv preprint arXiv:1404.3606
Chopra S, Balakrishnan S, Dlid GR (2013) Deep learning for domain adaptation by interpolating between domains. ICML workshop on challenges in representation learning 2:5
Dahl GE, Yu D, Deng L, Acero A (2012) Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. IEEE Trans Audio Speech Lang Process 20(1):30– 42
Daumé I IIH, Marcu D (2006) Domain adaptation for statistical classifiers. J Artif Intell Res:101– 126
Deng J, Xia R, Zhang Z, Liu Y, Schuller B (2014) Introducing shared-hidden-layer autoencoders for transfer learning and their application in acoustic emotion recognition. In: 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp 4818–4822
Deng J, Zhang Z, Marchi E, Schuller B (2013) Sparse autoencoder-based feature transfer learning for speech emotion recognition. In: 2013 Humaine Association Conference on Affective computing and intelligent interaction (ACII), pp 511–516
Deng J, Zhang Z, Eyben F, Schuller B (2014) Autoencoder-based unsupervised domain adaptation for speech emotion recognition. IEEE Signal Process Lett 21(9):1068–1072
Eyben F, Wollmer M, Schuller B (2009) Openear-introducing the munich open-source emotion and affect recognition toolkit, pp 1–6
Fernando B, Habrard A, Sebban M, Tuytelaars T (2013) Unsupervised visual domain adaptation using subspace alignment, pp 2960–2967
Glorot X, Bordes A, Bengio Y (2011) Domain adaptation for large-scale sentiment classification: A deep learning approach. In: Inproceedings of the 28th International Conference on Machine Learning, pp 513–520
Gretton A, Smola A, Huang J et al (2009) Covariate shift by kernel mean matching. Dataset shift in machine learning 3(4):5
Han K, Yu D, Tashev I (2014) Speech emotion recognition using deep neural network and extreme learning machine. In: Fifteenth Annual Conference of the International Speech Communication Association
Huang Z, Xue W, Mao Q (2015) Speech emotion recognition with unsupervised feature learning. Frontiers of Information Technology & Electronic Engineering 16:358–366
Kim Y, Provost EM (2013) Emotion classification via utterance-level dynamics: A pattern-based approach to characterizing affective expressions. In: 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp 3677–3681
Kim Y, Lee H, Provost EM (2013) Deep learning for robust feature generation in audiovisual emotion recognition Acoustics. In: 2013 IEEE International Conference on Speech and Signal Processing (ICASSP), pp 3687–3691
Le D, Provost EM, Zhan Y (2013) Emotion recognition from spontaneous speech using hidden markov models with deep belief networks, pp 216–221
Li L, Jin X, Long M (2012) Topic correlation analysis for cross-domain text classification. AAAI Conference on Artificial Intelligence
Mao Q, Wang X, Zhan Y (2010) Speech emotion recognition method based on improved decision tree and layered feature selection. International Journal of Humanoid Robotics 7(02):245–261
Mao Q, Zhao X, Huang Z, Zhan Y (2013) Speaker-independent speech emotion recognition by fusion of functional and accompanying paralanguage features. Journal of Zhejiang University SCIENCE C 14(7):573–582
Mao Q, Dong M, Huang Z, Zhan Y (2014) Learning salient features for speech emotion recognition using convolutional neural networks. IEEE Trans Multimed 716(8):2203–2213
Oquab M, Bottou L, Laptev I, Sivic J (2014) Learning and transferring mid-level image representations using convolutional neural networks. 2014 Proc. IEEE Conf Comput Vis Pattern Recognit (CVPR):1717–1724
Pan S, Yang Q (2010) Survey on transfer learning. IEEE Trans Knowl Data Eng 22(10):1345–1359
Sarikaya R, Hinton GE, Deoras A (2014) Application of deep belief networks for natural language understanding. IEEE/ACM Transactions on Audio Speech and Language Processing 22(4):778–784
Schmidt EM, Kim YE (2011) Learning emotion-based acoustic features with deep belief networks. In: 2011 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), pp 65–68
Schuller B, Arsic D, Rigoll G, Wimmer M, Radig B (2007) Audiovisual behavior modeling by combined feature spaces. In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), vol 2, pp II–733
Schuller B, Steidl S, Batliner A (2009) The interspeech 2009 emotion challenge. In: INTERSPEECH, vol 2009, pp 312–315
Schuller B, Vlasenko B, Eyben F, Wollmer M, Stuhlsatz A, Wendemuth A, Rigoll G (2010) Cross-corpus acoustic emotion recognition: variances and strategies. IEEE Trans Affect Comput 1(2):119– 131
Swietojanski P, Ghoshal A, Renals S (2012) Unsupervised cross-lingual knowledge transfer in dnn-based lvcsr. In: 2012 IEEE Spoken Language Technology Workshop (SLT), pp 246–251
Sun Y, Wang X, Tang X (2014) Deep learning face representation by joint identification-verification. Advances in Neural Information Processing Systems:1988–1996
Yu D, Seltzer ML, Li J, Huang JT, Seide F (2013) Feature learning in deep neural networks-studies on speech recognition tasks. arXiv preprint arXiv:1301.3605
Zhang B, Provost EM, Swedberg R et al (2015) Predicting emotion perception across domains: a study of singing and speaking. In: Association for the advancement of artificial intelligence, vol 2015, pp 4277–4280
Acknowledgments
This work was supported in part by the National Nature Science Foundation of China under Grants 61272211, the Six Talent Peaks Foundation of Jiangsu Province under Grant DZXX-027, and by the general Financial Grant from the China Postdoctoral Science Foundation (No. 2015M570413).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Huang, Z., Xue, W., Mao, Q. et al. Unsupervised domain adaptation for speech emotion recognition using PCANet. Multimed Tools Appl 76, 6785–6799 (2017). https://doi.org/10.1007/s11042-016-3354-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-016-3354-x