
Abstract
Currently RNN-based methods achieve excellent performance on action recognition using skeletons. But the inputs of these approaches are limited to coordinates of joints, and they improve the performance mainly by extending RNN models in different ways and exploring relations of body parts directly from joint coordinates. Our method utilizes a universal spatial model perpendicular to the RNN model enhancement. Specifically, we propose two simple geometric features, inspired by previous work. With experiments on a 3-layer LSTM (Long Short-Term Memory) framework, we find that the geometric relational features based on vectors and normal vectors outperform other methods and achieve state-of-art results on two datasets. Moreover, we show that utilizing our features as input requires less data for training.





Similar content being viewed by others

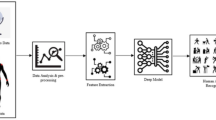

References
Bengio Y, Simard P, Frasconi P (1994) Learning long-term dependencies with gradient descent is difficult. IEEE Trans Neural Netw 5(2):157–166
Breuel TM (2015) Benchmarking of lstm networks. arXiv preprint arXiv:1508.02774
Chaudhry R, Ofli F, Kurillo G, Bajcsy R, Vidal R (2013) Bio-inspired dynamic 3D discriminative skeletal features for human action recognition, in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. Workshops 471–478
Chen C, Zhuang Y, Nie F, Yang Y, Wu F, Xiao J (2011) Learning a 3d human pose distance metric from geometric pose descriptor. IEEE Trans Vis Comput Graph 17(11):1676–1689
Donahue J, Anne Hendricks L, Guadarrama S, Rohrbach M, Venugopalan S, Saenko K, Darrell T (2015) Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE conference on computer vision and pattern recognition 2625–2634
Du Y, Wang W, Wang L (2015) Hierarchical recurrent neural network for skeleton based action recognition. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Evangelidis G, Singh G, Horaud R (2014) Skeletal quads: Human action recognition using joint quadruples. In International Conference on Pattern Recognition 4513–4518
Gavrila DM, Davis LS (1995) Towards 3-d model-based tracking and recognition of human movement: a multi-view approach. In International workshop on automatic face-and gesture-recognition. Citeseer, pp 272–277
Hinton GE, Srivastava N, Krizhevsky A, Sutskever I, Salakhutdinov RR (2012) Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv 1207:0580
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780
Hu J.-F, Zheng W.-S, Lai J, Zhang J (2015) Jointly learning heterogeneous features for rgb-d activity recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition 5344–5352
Ji Y, Ye G, Cheng H (2014) Interactive body part contrast mining for human interaction recognition. In Multimedia and Expo Workshops (ICMEW), 2014 I.E. international conference on 1–6. IEEE
Li W, Wen L, Choo Chuah M, Lyu S (2015) Category-blind human action recognition: a practical recognition system. In Proceedings of the IEEE international conference on computer vision, 4444–4452
Liu J, Shahroudy A, Xu D, Wang G (2016) Spatio-temporal lstm with trust gates for 3d human action recognition. In European Conference on Computer Vision 816–833. Springer
Lv F, Nevatia R (2006) Recognition and segmentation of 3D human action using HMM and multi-class adaboost,” in Proc. Eur. Conf. Comput. Vis., 359–372
Mahasseni B, Todorovic S (2016) Regularizing long short term memory with 3d human-skeleton sequences for action recognition. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Müller M, Röder T, Clausen M (2005) Efficient content-based retrieval of motion capture data. In ACM Transactions on Graphics (TOG) 24:677–685 ACM
Ohn-Bar E, Trivedi M (2013) Joint angles similarities and hog2 for action recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, 465–470
Oreifej O, Liu Z (2013) Hon4d: Histogram of oriented 4d normal for activity recognition from depth sequences. In Proceedings of the IEEE conference on computer vision and pattern recognition 716–723
Shahroudy A, Liu J, Ng T.-T., Wang G (2016) Ntu rgb+d: a large scale dataset for 3d human activity analysis. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Sharma S, Kiros R, Salakhutdinov R Action recognition using visual attention arXiv preprint arXiv:1511.04119, 2015
Sheikh Y, Sheikh M, Shah M (2005) Exploring the Space of a Human Action. In ICCV
Sutskever I, Martens J, Dahl GE, Hinton GE (2013) On the importance of initialization and momentum in deep learning. ICML (3) 28:1139–1147
Vemulapalli R, Arrate F, Chellappa R (2014) Human action recognition by representing 3d skeletons as points in a lie group. In Proceedings of the IEEE conference on computer vision and pattern recognition 588–595
Vinagre M, Aranda J, Casals A (2015) A new relational geometric feature for human action recognition. In Informatics in Control, Automation and Robotics 263–278. Springer
Wang C, Wang Y, Yuille AL (2013) An approach to pose-based action recognition, in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 915–922
Wu D, Shao L (2014) Leveraging hierarchical parametric networks for skeletal joints based action segmentation and recognition, in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 724–731
Xia L, Chen C.-C, Aggarwal J (2012) View invariant human action recognition using histograms of 3d joints. In 2012 I.E. computer society conference on computer vision and pattern recognition workshops, 20–27. IEEE
Xiaohan Nie B, Xiong C, Zhu S.-C (2015) Joint action recognition and pose estimation from video, in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 1293–1301
Xu K, Ba J, Kiros R, Cho K, Courville A, Salakhutdinov R, Zemel R, Bengio Y (2015) Show, attend and tell: Neural image caption generation with visual attention. arXiv preprint arXiv:1502.03044
Yang X, Tian Y (2014) Super normal vector for activity recognition using depth sequences. In Proceedings of the IEEE conference on computer vision and pattern recognition 804–811
Yao A, Gall J, Fanelli G, Van Gool LJ (2011) Does human action recognition benefit from pose estimation? In BMVC 3:6
Yue-Hei Ng J, Hausknecht M, Vijayanarasimhan S, Vinyals O, Monga R, Toderici G (2015) Beyond short snippets: deep networks for video classification. In Proceedings of the IEEE conference on computer vision and pattern recognition, 4694–4702
Yun K, Honorio J, Chattopadhyay D, Berg TL, Samaras D (2012) Two-person interaction detection using bodypose features and multiple instance learning. In 2012 I.E. computer society conference on computer vision and pattern recognition workshops, 28–35. IEEE
Zhu W, Lan C, Xing J, Zeng W, Li Y, Shen L, Xie X (2016) Co-occurrence feature learning for skeleton based action recognition using regularized deep lstm networks. In Thirtieth AAAI Conference on Artificial Intelligence
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Feng, J., Zhang, S. & Xiao, J. Explorations of skeleton features for LSTM-based action recognition. Multimed Tools Appl 78, 591–603 (2019). https://doi.org/10.1007/s11042-017-5290-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-017-5290-9