
Abstract
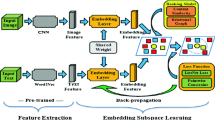
Recent years have witnessed a surge of interests in cross-modal ranking. To bridge the gap between heterogeneous modalities, many projection based methods have been studied to learn common subspace where the correlation across different modalities can be directly measured. However, these methods generally consider pair-wise relationship merely, while ignoring the high-order relationship. In this paper, a combinative hypergraph learning in subspace for cross-modal ranking (CHLS) is proposed to enhance the performance of cross-modal ranking by capturing high-order relationship. We formulate the cross-modal ranking as a hypergraph learning problem in latent subspace where the high-order relationship among ranking instances can be captured. Furthermore, we propose a combinative hypergraph based on fused similarity information to encode both the intra-similarity in each modality and the inter-similarity across different modalities into the compact subspace representation, which can further enhance the performance of cross-modal ranking. Experiments on three representative cross-modal datasets show the effectiveness of the proposed method for cross-modal ranking. Furthermore, the ranking results achieved by the proposed CHLS can recall 80% of the relevant cross-modal instances at a much earlier stage compared against state-of-the-art methods for both cross-modal ranking tasks, i.e. image query text and text query image.






Similar content being viewed by others


References
Ding G, Guo Y, Zhou J (2014) Collective matrix factorization hashing for multimodal data. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA. https://doi.org/10.1109/CVPR.2014.267, pp 2083–2090
Gao Y, Wang M, Luan H, Shen J, Yan S, Tao D (2011) Tag-based social image search with visual-text joint hypergraph learning. In: ACM international conference on Multimedia, pp 1517–1520
He R, Zhang M, Wang L, Ji Y, Yin Q (2015) Cross-modal subspace learning via pairwise constraints. IEEE Trans Image Process 24(12):5543–5556. https://doi.org/10.1109/TIP.2015.2466106, arXiv:1411.7798v1 1411.7798v1
He X (2004) Incremental semi-supervised subspace learning for image retrieval. In: MM’04, pp 2–8
He X, Niyogi P (2004) Locality preserving projections. Neural Inf Proces Syst 16:153
He Y, Xiang S, Kang C, Wang J, Pan C (2016) Cross-modal retrieval via deep and bidirectional representation learning. IEEE Trans Multimedia 18(7):1363–1377. https://doi.org/10.1109/TMM.2016.2558463
Irie G, Arai H, Taniguchi Y (2016) Alternating co-quantization for cross-modal hashing. In: Proceedings of the IEEE International Conference on Computer Vision, pp 1886–1894. https://doi.org/10.1109/ICCV.2015.219
Jin Y, Cao J, Ruan Q, Wang X (2014) Cross-modality 2D-3D face recognition via multiview smooth discriminant analysis based on ELM. J Electr Comput Eng 2014 (21):1–10. https://doi.org/10.1155/2014/584241
Kang C, Xiang S, Liao S, Xu C, Pan C (2015) Learning consistent feature representation for cross-modal multimedia retrieval. IEEE Trans Multimedia 17 (3):370–381. https://doi.org/10.1109/TMM.2015.2390499
Kitanovski I, Strezoski G, Dimitrovski I, Madjarov G, Loskovska S (2016) Multimodal medical image retrieval system. Multimedia Tools Appl 76:2955–2978. https://doi.org/10.1007/s11042-016-3261-1
Kumar S, Udupa R (2011) Learning hash functions for cross-view similarity search. In: Proceedings of International Joint Conference on Artificial Intelligence, Barcelona, Spain. https://doi.org/10.5591/978-1-57735-516-8/IJCAI11-230, pp 1360–1365
Lan X, Ma A J, Yuen P C, Chellappa R (2015) Joint sparse representation and robust feature-level fusion for multi-cue visual tracking. IEEE Trans Image Process 24(12):5826–5841. https://doi.org/10.1109/TIP.2015.2481325
Lan X, Ma AJ, Yuen PC (2014) Multi-cue visual tracking using robust feature-level fusion based on joint sparse representation. In: 2014 IEEE Conference on Computer Vision and Pattern Recognition, pp 1194–1201. https://doi.org/10.1109/CVPR.2014.156
Lan X, Zhang S, Yuen PC (2016) Robust joint discriminative feature learning for visual tracking. In: IJCAI, pp 3403–3410
Leng L, Li M, Kim C, Bi X (2017) Dual-source discrimination power analysis for multi-instance contactless palmprint recognition. Multimedia Tools Appl 76(1):333–354
Leng L, Li M, Leng L, Teoh A B J (2013) Conjugate 2dpalmhash code for secure palm-print-vein verification. In: 2013 6th International Congress on Image and Signal Processing (CISP). https://doi.org/10.1109/CISP.2013.6743951, vol 03, pp 1705–1710
Leng L, Zhang J, Chen G, Khan MK, Alghathbar K (2011) Two-directional two-dimensional random projection and its variations for face and palmprint recognition. In: International Conference on Computational Science and Its Applications, Springer, pp 458–470
Leng L, Zhang J, Khan M K, Chen X, Alghathbar K (2010) Dynamic weighted discrimination power analysis: a novel approach for face and palmprint recognition in dct domain. Int J Phys Sci 5(17):2543–2554
Leng L, Zhang J, Xu J, Khan MK, Alghathbar K (2010) Dynamic weighted discrimination power analysis in dct domain for face and palmprint recognition. In: 2010 International Conference on Information and Communication Technology Convergence (ICTC), pp 467–471. https://doi.org/10.1109/ICTC.2010.5674791
Leng L, Zhang S, Bi X, Khan MK (2012) Two-dimensional cancelable biometric scheme. In: 2012 International Conference on Wavelet Analysis and Pattern Recognition, pp 164–169. https://doi.org/10.1109/ICWAPR.2012.6294772
Lienhart R, Romberg S, Hȯrster E (2009) Multilayer pLSA for multimodal image retrieval. In: Proceedings of the ACM International Conference on Image and Video Retrieval (CIVR), Santorini, GR. https://doi.org/10.1145/1646396.1646408, pp 1–8
Liu H, Ji R, Wu Y, Hua G (2016) Supervised matrix factorization for cross-modality hashing. In: Proceedings of International Joint Conference on Artificial Intelligence 2016-Janua(7). https://doi.org/10.1109/TIP.2016.2564638, arXiv:1603.05572, pp 1767–1773
Liu Y, Chen Z, Deng C, Gao X (2016) Joint coupled-hashing representation for cross-modal retrieval. In: Proceedings of the International Conference on Internet Multimedia Computing and Service, ACM, pp 35–38
Lu X, Wu F, Li X, Zhang Y, Lu W, Wang D, Zhuang Y (2014) Learning multimodal neural network with ranking examples. In: Proceedings of the ACM International Conference on Multimedia - MM ’14, pp 985–988. https://doi.org/10.1145/2647868.2655001
Lu X, Wu F, Tang S, Zhang Z, He X, Zhuang Y (2013) A low rank structural large margin method for cross-modal ranking. In: Proceedings of ACM SIGIR’13, pp 433–442. https://doi.org/10.1145/2484028.2484039
Rasiwasia N, Costa Pereira J, Coviello E, Doyle G, Lanckriet G R, Levy R, Vasconcelos N (2010) A new approach to cross-modal multimedia retrieval. In: Proceedings of ACM International Conference on Multimedia, Firenze, Italy. https://doi.org/10.1145/1873951.1873987, pp 1–10
Rasiwasia N, Mahajan D, Mahadevan V, Aggarwal G (2014) Cluster canonical correlation analysis. In: Proceedings of Advances in Neural Information Processing Systems, pp 823–831
Rosipal R, Kr N (2006) Overview and recent advances in partial least squares. Subspace, Latent Structure and Feature Selection 3940:34–51
Shao J, Wang L, Zhao Z, Cai A (2016) Deep canonical correlation analysis with progressive and hypergraph learning for cross-modal retrieval. Neurocomputing 214:618–628
Sharma A, Jacobs DW (2011) Bypassing synthesis: PLS for face recognition with pose, low-resolution and sketch. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp 593–600. https://doi.org/10.1109/CVPR.2011.5995350
Shixun W, Peng P, Yansheng L (2013) A graph model for cross-modal retrieval. In: 3rd International Conference on Multimedia Technology (ICMT-13), Atlantis Press
Siddiquie B, White B, Sharma A, Davis LS (2014) Multi-modal image retrieval for complex queries using. In: Proceedings of ACM International Conference on Multimedia Retrieval, Glasgow, United Kingdom, pp 1–8
Simonyan K, Zisserman A (2015) Very Deep Convolutional Networks for Large-Scale Image Recognition. In: Proceedings of International Conference on Learning Representations, pp 1–14. https://doi.org/10.1016/j.infsof.2008.09.005, arXiv:1409.1556
Tang J, Wang K, Shao L (2016) Supervised matrix factorization hashing for cross-modal retrieval. IEEE Trans Image Process 25 (7):3157–3166. https://doi.org/10.1109/TIP.2016.2564638, arXiv:1603.05572
Wang C, Yang H, Meinel C (2016) A deep semantic framework for multimodal representation learning. Multimedia Tools Appl 75:9255–9276. https://doi.org/10.1007/s11042-016-3380-8
Wang D, Gao X, Wang X, He L (2015) Semantic topic multimodal hashing for cross-media retrieval. In: Proceedings of International Joint Conference on Artificial Intelligence, pp 3890–3896
Wang K, He R, Wang L, Wang W, Tan T (2016) Joint feature selection and subspace learning for cross-modal retrieval. IEEE Trans Pattern Anal Mach Intell 38(10):2010–2023. https://doi.org/10.1109/TPAMI.2015.2505311
Wang K, He R, Wang W, Wang L, Tan T (2013) Learning coupled feature spaces for cross-modal matching. In: Proceedings of the IEEE International Conference on Computer Vision, pp 2088–2095. https://doi.org/10.1109/ICCV.2013.261
Wang K, Wang W, He R, Wang L, Tan T (2013) Multi-modal subspace learning with joint graph regularization for cross-modal retrieval. In: Proceedings of 2nd IAPR Asian Conference on Pattern Recognition, pp 236–240. https://doi.org/10.1109/ACPR.2013.44
Wang L, Sun W, Zhao Z, Su F (2017) Modeling intra- and inter-pair correlation via heterogeneous high-order preserving for cross-modal retrieval. Signal Process 131:249–260. https://doi.org/10.1016/j.sigpro.2016.08.012
Wang S, Gu X, Lu J, Yang J, Wang R, Yang J (2014) Unsupervised discriminant canonical correlation analysis for feature fusion. In: ICPR, pp 1550–1555. https://doi.org/10.1109/ICPR.2014.275
Wang S, Pan P, Lu Y, Xie L (2015) Improving cross-modal and multi-modal retrieval combining content and semantics similarities with probabilistic model. Multimedia Tools Appl 74 (6):2009–2032. https://doi.org/10.1007/s11042-013-1737-9
Wang Y, Li P, Yao C (2014) Hypergraph canonical correlation analysis for multi-label classification. Signal Process 105:258–267. https://doi.org/10.1016/j.sigpro.2014.05.032
Wold S, Esbensen K, Geladi P (1987) Principal component analysis. Chemom Intell Lab Syst 2(1-3):37–52
Xie L, Shen J, Zhu L (2016) Online cross-modal hashing for web image retrieval. In: Proceedings of the 30th Conference on Artificial Intelligence (AAAI 2016), pp 294–300
Xie L, Zhu L, Chen G (2016) Unsupervised multi-graph cross-modal hashing for large-scale multimedia retrieval. Multimedia Tools Appl 75:9185–9204. https://doi.org/10.1007/s11042-016-3432-0
Xie L, Zhu L, Pan P, Lu Y (2016) Cross-modal self-taught hashing for large-scale image retrieval. Signal Process 124:81–92. https://doi.org/10.1016/j.sigpro.2015.10.010
Xu J, Singh V, Guan Z, Manjunath B (2012) Unified hypergraph for image ranking in a multimodal context. In: ICASSP, pp 2333–2336
Xu X, Yang Y, Shimada A, Ri Taniguchi, He L (2015) Semi-supervised coupled dictionary learning for cross-modal retrieval in internet images and texts. In: Proceedings of the ACM International Conference on Multimedia. https://doi.org/10.1145/2733373.2806346, pp 847–850
Yao T, Kong X, Fu H, Tian Q (2016) Semantic consistency hashing for cross-modal retrieval. Neurocomputing 193:250–259. https://doi.org/10.1016/j.neucom.2016.02.016
Yu J, Tao D, Wang M (2012) Adaptive hypergraph learning and its application in image classification. IEEE Trans Image Process 21(7):3262–3272
Zhan Y, Sun J, Niu D, Mao Q, Fan J (2015) A semi-supervised incremental learning method based on adaptive probabilistic hypergraph for video semantic detection. Multimedia Tools Appl 74(15):5513–5531. https://doi.org/10.1007/s11042-014-1866-9
Zhu X, Huang Z, Shen H T, Zhao X (2013) Linear cross-modal hashing for efficient multimedia search. In: Proceedings of ACM International Conference on Multimedia, Barcelona, Spain. https://doi.org/10.1145/2502081.2502107, pp 143–152
Zhuang Y, Wang Y, Wu F, Zhang Y, Lu W (2013) Supervised coupled dictionary learning with group structures for multi-modal retrieval. In: AAAI, pp 1070–1076
Acknowledgements
This work is jointly supported by the Nature Science Foundation of China under Grant 61672123, the State Key Program of National Natural Science of China under Grant U1301253, the Science and Technology Planning Key Project of Guangdong Province under Grant 2015B010110006, the National Key Research and Development Program of China under Grant 2016YFD0800300, and the Chinese Scholarship Council.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Zhong, F., Chen, Z., Min, G. et al. Combinative hypergraph learning in subspace for cross-modal ranking. Multimed Tools Appl 77, 25959–25982 (2018). https://doi.org/10.1007/s11042-018-5830-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-018-5830-y