
Abstract
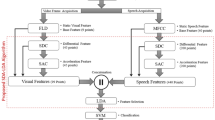
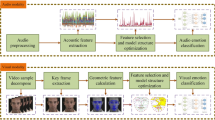
The peak frame selection with corresponding voice segment identification is a challenging problem in the audio-video human emotion recognition. The peak frame is a most relevant descriptor of facial expression that can be inferred from varied emotional states. In this paper, an improved Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) is proposed to select the key frame based on facial action units co-occurrence behavior in the visual sequences. The proposed method utilizes the experts judgments while identifying the peak frame in video modality. It locates the peak voiced segment in audio modality using synchronous and asynchronous temporal relationship with selected peak visual frame. The facial action unit features of peak frame are fused with nine statistical characteristics of spectral features of the voiced segment. The weighted product rule-based decision level fusion is performed to combine the posterior probabilities of two independent (i.e., audio, and video) support vector machines based classification models. The performance of the proposed peak frame and voiced segment selection method is evaluated and compared with the existing Maximum-Dissimilarity (MAX-DIST), Dendrogram -Clustering (DEND-CLUSTER), and Emotion Intensity (EIFS) based peak frame selection methods on two challenging emotion datasets in two different languages namely eNTERFACE’05 in English and BAUM-1a in Turkish. The results show that the system with the proposed method has performed better than the existing techniques, and it achieved 88.03%, and 84.61% emotion recognition accuracies on the eNTERFACE’05 and BAUM-1a datasets respectively.














Similar content being viewed by others

References
Alonso JA, Teresa Lamata M (2006) Consistency in the analytic hierarchy process: a new approach. Int J Uncertainty Fuzziness Knowledge Based Syst 14.4:445–459. https://doi.org/10.1142/S0218488506004114 https://doi.org/10.1142/S021848850600
Amiriparian S, Freitag M, Cummins N, Schuller B (2017) Feature selection in multimodal continuous emotion prediction. In: 17th IEEE international conference on affective computing and intelligent interaction workshops and demos (ACIIW), pp 30–37. https://doi.org/10.1109/ACIIW.2017.8272619
Atrey PK, Anwar Hossain M, Saddik AEl, Kankanhalli MS (2010) Multimodal fusion for multimedia analysis: a survey. Multimedia Systems 16.6:345–379. https://doi.org/10.1007/s00530-010-0182-0
Baltrušaitis T, Ahuja C, Morency L-P (2018) Multimodal machine learning: a survey and taxonomy. IEEE Transactions on Pattern Analysis and Machine Intelligence. p 99. https://doi.org/10.1109/TPAMI.2018.2798607 https://doi.org/10.1109/TPAMI.2018.2798607
Baltrusaitis T, Mahmoud M, Robinson P (2015) Cross-dataset learning and person-specific normalisation for automatic action unit detection. In: IEEE international conference and workshops on automatic face and gesture recognition (FG), vol 6. pp 1–6. https://doi.org/10.1109/FG.2015.7284869. https://github.com/TadasBaltrusaitis/FERA-2015. Accessed 21 Feb 2016
Baltrusaitis T, Robinson P, Morency L-P (2012) 3D constrained local model for rigid and non-rigid facial tracking. In: IEEE conference on computer vision and pattern recognition (CVPR), pp 2610–2617. https://doi.org/10.1109/CVPR.2012.6247980
Baltrusaitis T, Robinson P, Morency L-P (2013) Constrained local neural fields for robust facial landmark detection in the wild. In: Proceedings of the IEEE international conference on computer vision workshops, pp 354–361. https://doi.org/10.1109/ICCVW.2013.54
Baltrusaitis T, Robinson P, Morency L-P (2016) Openface: an open source facial behavior analysis toolkit. In: IEEE winter conference on applications of computer vision (WACV), pp 1–10. https://doi.org/10.1109/WACV.2016.7477553
Chang C-C, Lin C-J (2011) LIBSVM: A library for support vector machines. ACM transactions on Intelligent Systems and Technology (TIST) 2.3:27. https://doi.org/10.1145/1961189.1961199
Du S, Tao Y, Martinez AM (2014) Compound facial expressions of emotion. Proc Natl Acad Sci 111.15:1454–62. https://doi.org/10.1073/pnas.1322355111
Ekman P (1999) Basic emotions. The Handbook of Cognition and Emotion. pp 45–60
Ekman P, Friesen WV, Hager JC (2002) Facial action coding system: the manual on CD ROM instructor’s guide. Network Information Research Co, Salt Lake City
Escalera S, Pujol O, Radeva P (2009) Separability of ternary codes for sparse designs of error-correcting output codes. Pattern Recogn Lett 30.3:285–297. https://doi.org/10.1016/j.patrec.2008.10.002
Gharavian D, Bejani M, Sheikhan M (2017) Audio-visual emotion recognition using FCBF feature selection method and particle swarm optimization for fuzzy ARTMAP neural networks. Multimedia Tools and Applications 76.2:2331–2352. https://doi.org/10.1007/s11042-015-3180-6
Giannakopoulos T (2009) A method for silence removal and segmentation of speech signals, implemented in Matlab. University of Athens, Athens, p 2
Grant KW, Greenberg S (2001) Speech intelligibility derived from asynchronous processing of auditory-visual information. In: International conference on auditory-visual speech processing (AVSP), pp 132–137
Haq S, Jackson PJB (2009) Speaker-dependent audio-visual emotion recognition. In: Proceedings of international conference on auditory-visual speech processing, pp 53—58
Hermansky H, Morgan N (1994) RASTA Processing of speech. IEEE Transactions on Speech and Audio Processing 2.4:578–589. https://doi.org/10.1109/89.326616
Hwang C-L, Yoon K (1981) Methods for multiple attribute decision making. In: Multiple attribute decision making, Springer, Berlin, pp 58–191. https://doi.org/10.1007/978-3-642-48318-9_3
King DE (2009) Dlib-ml: a machine learning toolkit. J Mach Learn Res 10:1755–1758
Kolakowska A, Landowska A, Szwoch M, Wrobel MR (2014) Emotion recognition and its applications. Human-Computer Systems Interactions: Backgrounds and Applications. pp 51–62. https://doi.org/10.1007/978-3-319-08491-6_5
Kohler CG, Turner T, Stolar NM, Bilker WB, Brensinger CM, Gur RE, Gur RC (2004) Differences in facial expressions of four universal emotions. Psychiatry Res 128.3:235–244. https://doi.org/10.1016/j.psychres.2004.07.003 https://doi.org/10.1016/j.psychres.2004.07.003
Martin O, Kotsia I, Macq B, Pitas I (2006) The enterface’05 audio-visual emotion database. In: 22nd IEEE international conference on data engineering workshops, pp 1–8. http://www.enterface.net/enterface05/docs/results/databases/project2_database.zip. Accessed 13 Sept 2016
Mehmet K, Cigdem EE (2015) Affect recognition using key frame selection based on minimum sparse reconstruction. In: Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, pp 519–524. https://doi.org/10.1145/2818346.2830594
Mohammad Mavadati S, Mahoor MH, Bartlett K, Trinh P, Cohn JF (2013) DISFA: A spontaneous facial action intensity database. IEEE Trans Affect Comput 4.2:151–60. https://doi.org/10.1109/T-AFFC.2013.4
Picard RW, Picard R (1997) Affective computing. MIT Press, Cambridge, p 252
Rao RV (2013) Improved multiple attribute decision making methods. In: Decision making in manufacturing environment using graph theory and fuzzy multiple attribute decision making methods, Springer, London, pp 7–39. https://doi.org/10.1007/978-1-4471-4375-8_2
Sidorov M, Sopov E, Ivanov I, Minker W (2015) Feature and decision level audio-visual data fusion in emotion recognition problem. In: 12th IEEE international conference on informatics in control automation and robotics (ICINCO), vol 2. pp 246–251
Valstar MF, Almaev T, Girard JM, McKeown G, Mehu M, Yin L, Pantic M, Cohn JF (2015) FERA 2015-Second facial expression recognition and analysis challenge. In: 11th IEEE international conference and workshops on automatic face and gesture recognition (FG) vol 6. pp 1–8. https://doi.org/10.1109/FG.2015.7284874
Yan C, Zhang Y, Xu J, Dai F, Zhang J, Dai Q, Wu F (2014) Efficient parallel framework for HEVC motion estimation on Many-Core processors. IEEE Trans Circuits Syst Video Technol 24.12:2077–2089. https://doi.org/10.1109/TCSVT.2014.2335852
Yan C, Zhang Y, Xu J, Dai F, Li L, Dai Q, Wu F (2014) A highly parallel framework for HEVC coding unit partitioning tree decision on many-core processors. IEEE Signal Process Lett 21.5:573–576. https://doi.org/10.1109/LSP.2014.2310494
Yan C, Xie H, Yang D, Yin J, Zhang Y, Dai Q (2018) Supervised hash coding with deep neural network for environment perception of intelligent vehicles. IEEE Trans Intell Transp Syst 19.1:284–295. https://doi.org/10.1109/TITS.2017.2749965
Zhalehpour S, Akhtar Z, Erdem CE (2014) Multimodal emotion recognition with automatic peak frame selection. In: Proceedings of IEEE international symposium on innovations in intelligent systems and applications (INISTA), pp 116–121
Zhalehpour S, Akhtar Z, Erdem CE (2016) Multimodal emotion recognition based on peak frame selection from video. Signal Image and Video Processing. 10:827–834. https://doi.org/10.1007/s11760-015-0822-0 https://doi.org/10.1007/s11760-015-0822-0
Zhalehpour S, Onder O, Akhtar Z, Erdem CE (2016) BAUM-1: A Spontaneous Audio-Visual Face Database of Affective and Mental States. IEEE Trans Affect Comput 8.3:300–313. https://doi.org/10.1109/TAFFC.2016.2553038 https://doi.org/10.1109/TAFFC.2016.2553038. http://baum1.bahcesehir.edu.tr/R/. Accessed 18 Aug 2017
Zhang X, Yin L, Cohn JF, Canavan SJ, Reale MJ, Horowitz A, Liu P, Girard JM (2014) BP4D-spontaneous: a high-resolution spontaneous 3d dynamic facial expression database. Image and Vision Computing 32.10:692–706
Acknowledgements
This work was supported by University Grant Commission (UGC), Ministry of Human Resource Development (MHRD) of India under Basic Scientific Research (BSR) fellowship for meritorious fellows vide UGC letter no. F.25-1/2013-14(BSR)/7-379/2012(BSR) Dated 30.5. 2014.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Singh, L., Singh, S. & Aggarwal, N. Improved TOPSIS method for peak frame selection in audio-video human emotion recognition. Multimed Tools Appl 78, 6277–6308 (2019). https://doi.org/10.1007/s11042-018-6402-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-018-6402-x