
Abstract
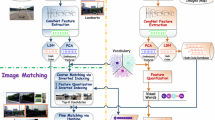
In this work, we present DeepCamera, a novel framework that combines visual recognition and spatial recognition for identifying places-of-interest (POIs) from smartphone photos. Both deep visual features and geographic features of images are explored in our framework. For visual recognition, we first design the HashNet model extended from an ordinary convolutional neural network (ConvNet) by adding a “hash layer” following the last fully connected layer. Furthermore, we compress multiple pre-trained deep HashNets into one single shallow and hash network namely “SHNet” that outputs semantic labels and compact hash codes simultaneously. As a result, it significantly reduces the time and memory consumption during POI recognition. For spatial recognition, a new layer called Spatial Layer is appended to a ConvNet to capture spatial information. Finally, both visual and spatial knowledge contribute to generating a hybrid probability distribution over all possible POI candidates by plugging the spatial layer into SHNet. Notably, the proposed SHNet model can be used for general visual recognition and retrieval. The experiments conducted on real-world datasets and classic datasets (MNIST and CIFAR-10) demonstrate the competitive accuracy and run-time performance of our proposed framework.














Similar content being viewed by others


Notes
FOV is a tuple of 4 camera parameters: GPS location, the angles of view, the maximum visible distance, and the direction of the camera.
The weight matrix WH connects the fully connected layer and the hash layer, while the weight matrix WL connects the hash layer and the output layer
http://www.geonames.org/
http://yann.lecun.com/exdb/mnist/ and CIFAR-10Footnote 7
https://www.cs.toronto.edu/ kriz/cifar.html
References
Ba LJ, Caurana R (2014) Do deep nets really need to be deep? In: NIPS, pp 2654–2662
Cheng Z, Ding Y, He X, Zhu L, Song X, Kankanhalli MS (2018) A3ncf: an adaptive aspect attention model for rating prediction. In: IJCAI, pp 3748–3754
Cheng Z, Shen J, Nie L, Chua TS, Kankanhalli MS (2017) Exploring user-specific information in music retrieval. In: SIGIR, pp 655–664
Cheng Z, Shen J, Zhu L, Kankanhalli MS, Nie L (2017) Exploiting music play sequence for music recommendation. In: IJCAI, pp 3654–3660
Gao F, Wang Y, Li P, Tan M, Yu J, Zhu Y (2017) Deepsim: deep similarity for image quality assessment. Neurocomputing 257:104–114
Gao F, Yu J, Zhu S, Huang Q, Tian Q (2018) Blind image quality prediction by exploiting multi-level deep representations. Pattern Recogn 81:432–442
Girshick RB (2015) Fast r-cnn. arXiv:1504.08083
Girshick RB, Donahue J, Darrell T, Malik J (2014) Rich feature hierarchies for accurate object detection and semantic segmentation. In: CVPR, pp 580–587
Gu X, Peng P, Li M, Wu S, Shou L, Chen G (2015) Cross-scenario eyeglasses retrieval via Egypt model. In: ICMR. ACM, pp 463–466
Gu X, Wong Y, Peng P, Shou L, Chen G, Kankanhalli M S (2017) Understanding fashion trends from street photos via neighbor-constrained embedding learning. In: ACM multimedia, pp 190–198
Gu X, Wu S, Peng P, Shou L, Chen K, Chen G (2017) Csir4g: an effective and efficient cross-scenario image retrieval model for glasses. Inf Sci 417:310–327
He K, Zhang X, Ren S, Sun J (2015) Delving deep into rectifiers: surpassing human-level performance on imagenet classification. In: ICCV
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: CVPR. IEEE Computer Society, pp 770–778
He K, Gkioxari G, Dollár P, Girshick RB (2017) Mask r-cnn. In: ICCV. IEEE Computer Society, pp 2980–2988
Hornik K (1991) Approximation capabilities of multilayer feedforward networks. Neural Netw 4(2):251–257
Ioffe S, Szegedy C (2015) Batch normalization: accelerating deep network training by reducing internal covariate shift. In: ICML, vol 37, pp 448–456
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: NIPS, pp 1097–1105
Li R, Jia J (2016) Visual question answering with question representation update (qru). In: NIPS, pp 4655–4663
Liong VE, Lu J, Wang G, Moulin P, Zhou J (2015) Deep hashing for compact binary codes learning. In: CVPR, pp 2475–2483
Luo X, Nie L, He X, Wu Y, Chen ZD, Xu XS (2018) Fast scalable supervised hashing. In: SIGIR, pp 735–744
Nie L, Wang M, Zha ZJ, Chua TS (2012) Oracle in image search: a content-based approach to performance prediction. ACM Trans Inf Syst 30(2):13
Nie L, Yan S, Wang M, Hong R, Chua TS (2012) Harvesting visual concepts for image search with complex queries. In: ACM multimedia, pp 59–68
Nistér D, Stewénius H (2006) Scalable recognition with a vocabulary tree. In: CVPR. IEEE Computer Society, pp 2161–2168
Peng P, Shou L, Chen K, Chen G, Wu S (2013) The knowing camera: recognizing places-of-interest in smartphone photos. In: SIGIR, pp 969–972
Peng P, Shou L, Chen K, Chen G, Wu S (2014) The knowing camera 2: recognizing and annotating places-of-interest in smartphone photos. In: SIGIR, pp 707–716
Ren S, He K, Girshick RB, Sun J (2015) Faster r-cnn: towards real-time object detection with region proposal networks. arXiv:1506.01497
Rui Y, Huang TS, Chang SF (1999) Image retrieval: current techniques, promising directions, and open issues. J Vis Commun Image Represent 10(1):39–62
Salakhutdinov R, Hinton GE (2009) Semantic hashing. Int J Approx Reasoning 50:969–978
Sermanet P, Eigen D, Zhang X, Mathieu M, Fergus R, LeCun Y (2014) Overfeat: integrated recognition, localization and detection using convolutional networks. In: ICLR
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. In: ICLR
Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R (2014) Dropout: a simple way to prevent neural networks from overfitting. JLMR 15:1929–1958
Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A (2015) Going deeper with convolutions. In: CVPR, pp 1–9
Xia R, Pan Y, Lai H, Liu C, Yan S (2014) Supervised hashing for image retrieval via image representation learning. In: AAAI, pp 2156–2162
Xie L, Shen J, Zhu L (2016) Online cross-modal hashing for web image retrieval. In: AAAI, pp 294–300
Xie L, Shen J, Han J, Zhu L, Shao L (2017) Dynamic multi-view hashing for online image retrieval. In: IJCAI, pp 3133–3139
Xu K, Ba J, Kiros R, Cho K, Courville AC, Salakhutdinov R, Zemel RS, Bengio Y (2015) Show, attend and tell: neural image caption generation with visual attention. In: ICML, vol 37, pp 2048–2057
Yang HF, Lin K, Chen CS (2015) Supervised learning of semantics-preserving hashing via deep neural networks for large-scale image search. arXiv:1507.00101
Yu J, Yang X, Gao F, Tao D (2017) Deep multimodal distance metric learning using click constraints for image ranking. IEEE Trans Cybern 47(12):4014–4024
Yu J, Zhang B, Kuang Z, Lin D, Fan J (2017) Iprivacy: image privacy protection by identifying sensitive objects via deep multi-task learning. IEEE Trans Inf Forensics Secur 12(5):1005–1016
Yu Z, Yu J, Xiang C, Fan J, Tao D (2018) Beyond bilinear: generalized multi-modal factorized high-order pooling for visual question answering. IEEE Transactions on Neural Networks and Learning Systems. https://doi.org/10.1109/TNNLS.2018.2817340
Yu J, Kuang Z, Zhang B, Zhang W, Lin D, Fan J (2018) Leveraging content sensitiveness and user trustworthiness to recommend fine-grained privacy settings for social image sharing. IEEE Trans Inf Forensics Secur 13(5):1317–1332
Zhou ZH (2012) Ensemble methods: foundations and algorithms, 1st edn. Chapman & Hall/CRC
Zhu L, Huang Z, Chang X, Song J, Shen HT (2017) Exploring consistent preferences: discrete hashing with pair-exemplar for scalable landmark search. In: ACM Multimedia, pp 726– 734
Zhu L, Huang Z, Liu X, He X, Sun J, Zhou X (2017) Discrete multimodal hashing with canonical views for robust mobile landmark search. IEEE Trans Multimed 19(9):2066–2079
Zhu L, Huang Z, Li Z, Xie L, Shen HT (2018) Exploring auxiliary context: discrete semantic transfer hashing for scalable image retrieval. IEEE Trans Neural Netw Learn Syst 29:5264–5276
Acknowledgments
The project was supported by the National Basic Research Program (973 Program, GrantNo.2015CB352400), and the National Science Foundation of China (GrantNo. 61802100, 61672455, 61528207 and 61472348). The project was also supported by the Natural Science Foundation of Zhejiang Province of China (GrantNo. LY18F020005).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was done while the author was with Zhejiang university.
Rights and permissions
About this article

Cite this article
Peng, P., Gu, X., Zhu, S. et al. One net to rule them all: efficient recognition and retrieval of POI from geo-tagged photos. Multimed Tools Appl 78, 24347–24371 (2019). https://doi.org/10.1007/s11042-018-6847-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-018-6847-y