
Abstract
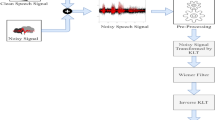
Variance based two dimensional time-frequency mask estimation for unsupervised speech enhancement is proposed to improve the speech quality and intelligibility by reducing the low-frequency residual noise distortion in the noisy speech signals. Unlike conventional speech enhancement methods, the proposed method is able to reduce the residual noise distortion by utilizing benefits of the less aggressive Wiener gain and variance based two dimensional time-frequency mask to establish a two-stage speech enhancement method. In the first stage, the less aggressive Wiener gain with modified a priori signal-to-noise (SNR) estimate is applied to the input noisy speech to obtain a reduced noise pre-processed speech signal. In the second stage, variance based features are extracted from the pre-processed speech and compared to a nonparametric adaptive threshold to construct a two dimensional time-frequency mask. The estimated mask is then applied to the pre-processed speech from the first stage to suppress the annoying residual noise distortion. A comparative performance study is included to demonstrate the effectiveness of the proposed method in various noisy conditions. The experimental results showed large improvements in terms of the perceptual evaluation of speech quality (PESQ), segmental SNR (SegSNR), residual noise distortion (BAK) and speech distortion (SIG) over that achieved with competing methods at different input SNRs. To measure the understanding of enhanced speech in different noisy conditions, short-time intelligibility prediction (STOI) is used which reinforced a better performance of the proposed method in terms of the speech intelligibility. The time-varying spectral analysis validated significant reduction of the residual noise components in the enhanced speech.









Similar content being viewed by others


References
Abel A, Hussain A (2015). Cognitively inspired audiovisual speech filtering: towards an intelligent, fuzzy based, multimodal, two-stage speech enhancement system(Vol. 5). Springer
Aicha AB (2017) Noise estimation for speech enhancement algorithms with post-smoothness processor incorporating global posterior SNR. Multimed Tools Appl 76(22):23661–23678
Bao F, Abdulla WH (2018) Noise masking method based on an effective ratio mask estimation in Gammatone channels. APSIPA Transactions on Signal and Information Processing, 7
Boll S (1979) Suppression of acoustic noise in speech using spectral subtraction. IEEE Trans Acoust Speech Signal Process 27(2):113–120
Braun S, Kowalczyk K, Habets EA (2015) In Residual noise control using a parametric multichannel Wiener filter, Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on, IEEE; pp 360–364
Chatlani N, Soraghan JJ (2012) EMD-based filtering (EMDF) of low-frequency noise for speech enhancement. IEEE Trans Audio Speech Lang Process 20(4):1158–1166
Chehrehsa S, Moir TJ (2017) Speech and noise power estimation using gamma modeling. International Journal of Adaptive Control and Signal Processing 31(10):1491–1502
Cohen I, Berdugo B (2002) Noise estimation by minima controlled recursive averaging for robust speech enhancement. IEEE Signal processing letters 9(1):12–15
Ephraim Y, Malah D (1984) Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator. IEEE Trans Acoust Speech Signal Process 32(6):1109–1121
Ephraim Y, Malah D (1985) Speech enhancement using a minimum mean-square error log-spectral amplitude estimator. IEEE Trans Acoust Speech Signal Process 33(2):443–445
Ferreira LB, Duarte AB, da Cunha FF, Fernandes Filho EI (2019) Multivariate adaptive regression splines (MARS) applied to daily reference evapotranspiration modeling with limited weather data. Acta Scientiarum Agronomy 41:e39880
Goehring T, Bolner F, Monaghan JJ, van Dijk B, Zarowski A, Bleeck S (2017) Speech enhancement based on neural networks improves speech intelligibility in noise for cochlear implant users. Hear Res 344:183–194
Gogate M, Adeel A, Marxer R, Barker J, Hussain A (2018) Dnn driven speaker independent audio-visual mask estimation for speech separation. arXiv preprint arXiv:1808.00060
Guang-Yan W, Xiao-qun Z, Xia W (2009) Musical noise reduction based on spectral subtraction combined with Wiener filtering for speech communication
Gustafsson H, Nordholm SE, Claesson I (2001) Spectral subtraction using reduced delay convolution and adaptive averaging. IEEE transactions on speech and audio processing 9(8):799–807
Han T, Yao H, Sun X, Zhao S, Zhang Y (2016) Unsupervised discovery of crowd activities by saliency-based clustering. Neurocomputing 171:347–361
Hermus K, Wambacq P (2006) A review of signal subspace speech enhancement and its application to noise robust speech recognition. EURASIP journal on advances in signal processing 2007(1):045821
Hirsch H-G, Pearce D (2000) In The Aurora experimental framework for the performance evaluation of speech recognition systems under noisy conditions, ASR2000-Automatic Speech Recognition: Challenges for the new Millenium ISCA Tutorial and Research Workshop (ITRW)
Hu Y, Loizou PC (2003) A generalized subspace approach for enhancing speech corrupted by colored noise. IEEE transactions on speech and audio processing 11(4):334–341
Hu Y, Loizou PC (2008) Evaluation of objective quality measures for speech enhancement. IEEE Trans Audio Speech Lang Process 16(1):229–238
Huang NE, Shen Z, Long SR, Wu MC, Shih HH, Zheng Q, Yen N-C, Tung CC, Liu HH (1998) In The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis, Proceedings of the Royal Society of London A: mathematical, physical and engineering sciences, The Royal Society; pp 903–995
Kamath S, Loizou, P. (2002) In A multi-band spectral subtraction method for enhancing speech corrupted by colored noise, ICASSP, pp 44164–44164
Li H, Wang Y, Zhao R, Zhang X (2018) An unsupervised two-talker speech separation system based on CASA. Int J Pattern Recognit Artif Intell 32(07):1858002
Lim J, Oppenheim A (1978) All-pole modeling of degraded speech. IEEE Trans Acoust Speech Signal Process 26(3):197–210
Liu Z, Wang T. (2016) An Adaptive Image Denoising Algorithm Based on Wavelet Transform and Independent Component Analysis, Sixth International Conference on Intelligent Systems Design and Engineering Applications. IEEE:104–107
Loizou P (2007) Subjective evaluation and comparison of speech enhancement methods. Speech Commun 49:588–601
Lu C-T (2007) Reduction of musical residual noise for speech enhancement using masking properties and optimal smoothing. Pattern Recogn Lett 28(11):1300–1306
Lu C-T (2014) Noise reduction using three-step gain factor and iterative-directional-median filter. Appl Acoust 76:249–261
Lu Y, Loizou PC (2011) Estimators of the magnitude-squared spectrum and methods for incorporating SNR uncertainty. IEEE Trans Audio Speech Lang Process 19(5):1123
Luo Y, Mesgarani N (2018) TasNet: Surpassing ideal time-frequency masking for speech separation. arXiv preprint arXiv:1809.07454
Martin R (2001) Noise power spectral density estimation based on optimal smoothing and minimum statistics. IEEE transactions on speech and audio processing 9(5):504–512
Marxer R, Barker J (2017) Binary Mask Estimation Strategies for Constrained Imputation-Based Speech Enhancement. In INTERSPEECH, pp. 1988–1992
Min G, Zhang X, Zou X, Sun M (2016) In Mask estimate through Itakura-Saito nonnegative RPCA for speech enhancement, Acoustic Signal Enhancement (IWAENC), 2016 IEEE International Workshop on, IEEE; pp 1–5
Nasir S, Sher A, Usman K, Farman U (2013) Speech enhancement with geometric advent of spectral subtraction using connected time-frequency regions noise estimation. Res J Appl Sci Eng Technol 6(6):1081–1087
Otsu N (1979) A threshold selection method from gray-level histograms. IEEE transactions on systems, man, and cybernetics 9(1):62–66
Rahali H, Hajaiej Z (2017) Enhancement of noise-suppressed speech by spectral processing implemented in a digital signal processor. Analog Integr Circ Sig Process 93(2):341–350
Rangachari S, Loizou PC (2006) A noise-estimation method for highly non-stationary environments. Speech Comm 48(2):220–231
Renson L, Sieber J, Barton DAW, Shaw AD, Neild SA (2019) Numerical Continuation in Nonlinear Experiments using Local Gaussian Process Regression. arXiv preprint arXiv:1901.06970
Rix AW, Beerends JG, Hollier MP, Hekstra AP (2001) In Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs, Acoustics, Speech, and Signal Processing, 2001. Proceedings.(ICASSP'01). 2001 IEEE International Conference on, IEEE: pp 749–752
Rothauser E (1969) IEEE recommended practice for speech quality measurements. IEEE Trans on Audio and Electroacoustics 17:225–246
Saleem N (2017) Single channel noise reduction system in low SNR. International Journal of Speech Technology 20(1):89–98
Saleem N, Ijaz G (2018) Low rank sparse decomposition model based speech enhancement using gammatone filterbank and Kullback–Leibler divergence. International Journal of Speech Technology 21(2):217–231
Saleem N, Irfan M (2018) Noise reduction based on soft masks by incorporating SNR uncertainty in frequency domain. Circuits, Systems, and Signal Processing 37(6):2591–2612
Saleem N, Shafi M, Mustafa E, Nawaz A (2015) A novel binary mask estimation based on spectral subtraction gain-induced distortions for improved speech intelligibility and quality. University of Engineering and technology Taxila. Technical Journal 20(4):36
Saleem N, Khattak MI, Shafi M (2018) Unsupervised speech enhancement in low SNR environments via sparseness and temporal gradient regularization. Appl Acoust 141:333–347
Scalart P (1996) In Speech enhancement based on a priori signal to noise estimation, Acoustics, Speech, and Signal Processing, 1996. ICASSP-96. Conference Proceedings, 1996 IEEE International Conference on, IEEE; pp 629-63e2
Singh S, Tripathy M, Anand R (2015) Binary mask based method for enhancement of mixed noise speech of low SNR input. International Journal of Speech Technology 18(4):609–617
Sorensen KV, Andersen SV (2005) Speech enhancement with natural sounding residual noise based on connected time-frequency speech presence regions. EURASIP Journal on Applied Signal Processing 2005:2954–2964
Srinivasan S, Roman N, Wang D (2006) Binary and ratio time-frequency masks for robust speech recognition. Speech Comm 48(11):1486–1501
Taal CH, Hendriks RC, Heusdens R, Jensen J (2011) An method for intelligibility prediction of time–frequency weighted noisy speech. IEEE Trans Audio Speech Lang Process 19(7):2125–2136
Tavares R, Coelho R (2016) Speech enhancement with nonstationary acoustic noise detection in time domain. IEEE Signal Processing Letters 23(1):6–10
Wang D (2005) On ideal binary mask as the computational goal of auditory scene analysis. In Speech separation by humans and machines, Springer: pp 181–197
Wang D (2008) Time-frequency masking for speech separation and its potential for hearing aid design. Trends in Amplification 12(4):332–353
Wang D, Brown GJ (2006) Computational auditory scene analysis: Principles, methods, and applications. Wiley-IEEE press
Yan C, Xie H, Chen J, Zha Z, Hao X, Zhang Y, Dai Q (2018) A fast uyghur text detector for complex background images. IEEE Transactions on Multimedia 20(12):3389–3398
Yan C, Li L, Zhang C, Liu B, Zhang Y, Dai Q (2019) Cross-modality bridging and knowledge transferring for image understanding. IEEE Transactions on Multimedia
Yan C, Li Z, Zhang Y, Qin P, Ji X and Dai Q. (2019) Depth image denoising using nuclear norm and learning graph model. IEEE Transactions on Multimedia
Yan C, Tu Y, Wang X, Zhang Y, Hao X, Zhang Y and Dai Q (2019) STAT: Spatial-Temporal Attention Mechanism for Video Captioning. IEEE Transactions on Multimedia
You X, Du L, Cheung Y-m, Chen Q (2010) A blind watermarking scheme using new nontensor product wavelet filter banks. IEEE Trans Image Process 19(12):3271–3284
Zao L, Coelho R, Flandrin P (2014) Speech enhancement with emd and Hurst-based mode selection. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP) 22(5):899–911
Zhao S, Yao H, Wang F, Jiang X, Zhang W (2014) Emotion based image musicalization. IEEE International conference on multimedia and expo workshops (ICMEW) pp. 1–6
Zou X, Jancovic P, Liu J, Kokuer M (2008) Speech signal enhancement based on MAP method in the ICA space. IEEE Trans Signal Process 56(5):1812–1820
Zou Y, Liu Z, Ritz C (2018) Enhancing target speech based on nonlinear soft masking using a single acoustic vector sensor. Appl Sci 8(9):1436
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Saleem, N., Khattak, M.I., Witjaksono, G. et al. Variance based time-frequency mask estimation for unsupervised speech enhancement. Multimed Tools Appl 78, 31867–31891 (2019). https://doi.org/10.1007/s11042-019-08032-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-019-08032-y