
Abstract
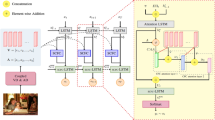
Visual attention has been widely used in deep image captioning models for its capacity of selectively aligning visual features to the corresponding words, i.e., the word-to-region alignment. In many cases, existing attention modules may not highlight task-related image regions for lack of high-level semantics. To advance captioning model, it is non-trivial for image captioning to effectively leverage high-level semantics. To defeat such issues, we propose a gated spatial and semantic attention captioning model (GateCap) which adaptively fuses spatial attention features with semantic attention features to achieve this goal. In particular, GateCap brings into two novel aspects: 1) spatial and semantic attention features are further enhanced via triple LSTMs in a divide-and-fuse learning manner, and 2) a context gate module is explored to reweigh spatial and semantic attention features in a fair manner. Benefitting from them, GateCap could reduce the side effect of the word-to-region misalignment at a time step over subsequent word prediction, thereby possibly alleviating emergence of incorrect words during testing. Experiments on MSCOCO dataset verify the efficacy of the proposed GateCap model in terms of quantitative and qualitative results.









Similar content being viewed by others


References
Anderson P, Fernando B, Johnson M, Gould S (2016) Spice: Semantic propositional image caption evaluation. In: European conference on computer vision, pp 382–398
Anderson P, He X, Buehler C, Teney D, Johnson M, Gould S, Zhang L (2018) Bottom-up and top-down attention for image captioning and visual question answering. In: IEEE conference on computer vision and pattern recognition
Banerjee S, Lavie A (2005) METEOR: An automatic metric for mt evaluation with improved correlation with human judgments. In: The acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pp 65–72
Bird S, Klein E, Loper E (2009) Natural language processing with Python: analyzing text with the natural language toolkit. ” O’Reilly Media, Inc.”
Chen L, Zhang H, Xiao J, Nie L, Shao J, Liu W, Chua TS (2017) SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning. In: IEEE conference on computer vision and pattern recognition, pp 6298–6306
Cheng Z, Bai F, Xu Y, Zheng G, Pu S, Zhou S (2017) Focusing attention: Towards accurate text recognition in natural images. In: IEEE International Conference on Computer Vision, pp 5076–5084
Fang F, Wang H, Chen Y, Tang P (2018) Looking deeper and transferring attention for image captioning. Multimed Tools Appl 77(23):31,159–31,175
Gan Z, Gan C, He X, Pu Y, Tran K, Gao J, Carin L, Deng L (2017) Semantic compositional networks for visual captioning. In: IEEE conference on computer vision and pattern recognition, pp 5630–5639
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: IEEE conference on computer vision and pattern recognition, pp 770–778
Jiang W, Ma L, Jiang YG, Liu W, Zhang T (2018) Recurrent fusion network for image captioning. In: European conference on computer vision, pp 499–515
Jin J, Fu K, Cui R, Sha F, Zhang C (2015) Aligning where to see and what to tell: image caption with region-based attention and scene factorization. arXiv:150606272
Karpathy A, Fei-Fei L (2015) Deep visual-semantic alignments for generating image descriptions. In: IEEE conference on computer vision and pattern recognition, pp 3128–3137
Kingma D P, Ba J (2014) Adam: A method for stochastic optimization
Li L, Tang S, Deng L, Zhang Y, Tian Q (2017) Image caption with global-local attention. In: 31st AAAI conference on artificial intelligence
Lin CY (2004) Rouge: A package for automatic evaluation of summaries. Text Summarization Branches Out
Lin TY, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick CL (2014) Microsoft coco: Common objects in context. In: European conference on computer vision, pp 740–755
Liu C, Sun F, Wang C, Wang F, Yuille A (2017) MAT: A multimodal attentive translator for image captioning
Lu J, Xiong C, Parikh D, Socher R (2017) Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In: IEEE Conference on Computer Vision and Pattern Recognition, pp 3242–3250
Mao J, Xu W, Yang Y, Wang J, Huang Z, Yuille A (2014) Deep captioning with multimodal recurrent neural networks (m-rnn)
Papineni K, Roukos S, Ward T, Zhu WJ (2002) BLEU: a method for automatic evaluation of machine translation. In: The 40th annual meeting on association for computational linguistics, pp 311–318
Pedersoli M, Lucas T, Schmid C, Verbeek J (2017) Areas of attention for image captioning. In: IEEE international conference on computer vision, pp 1242–1250
Ren S, He K, Girshick R, Sun J (2015) Faster r-cnn: Towards real-time object detection with region proposal networks. In: Advances in neural information processing systems, pp 91–99
Ren Z, Wang X, Zhang N, Lv X, Li LJ (2017) Deep reinforcement learning-based image captioning with embedding reward. In: IEEE conference on computer vision and pattern recognition, pp 290–298
Rennie SJ, Marcheret E, Mroueh Y, Ross J, Goel V (2017) Self-critical sequence training for image captioning. In: IEEE conference on computer vision and pattern recognition, pp 1179–1195
Selvaraju RR, Das A, Vedantam R, Cogswell M, Parikh D, Batra D (2016) Grad-cam: Why did you say that?. arXiv:161107450
Vedantam R, Lawrence Zitnick C, Parikh D (2015) Cider: Consensus-based image description evaluation. In: IEEE conference on computer vision and pattern recognition, pp 4566–4575
Vinyals O, Toshev A, Bengio S, Erhan D (2015) Show and tell: A neural image caption generator. In: IEEE conference on computer vision and pattern recognition, pp 3156–3164
Wu Q, Shen C, Liu L, Dick A, van den Hengel A (2016) What value do explicit high level concepts have in vision to language problems? In: IEEE conference on computer vision and pattern recognition, pp 203–212
Xu K, Ba J, Kiros R, Cho K, Courville A, Salakhudinov R, Zemel R, Bengio Y (2015) Show, attend and tell: Neural image caption generation with visual attention. In: International conference on machine learning, pp 2048–2057
Yang Z, Yuan Y, Wu Y, Cohen WW, Salakhutdinov RR (2016) Review networks for caption generation. In: Advances in neural information processing systems, pp 2361–2369
Yao T, Pan Y, Li Y, Mei T (2017) Incorporating copying mechanism in image captioning for learning novel objects. In: IEEE conference on computer vision and pattern recognition, pp 5263–5271
Yao T, Pan Y, Li Y, Qiu Z, Mei T (2017) Boosting image captioning with attributes. In: IEEE International Conference on Computer Vision, pp 22–29
You Q, Jin H, Wang Z, Fang C, Luo J (2016) Image captioning with semantic attention. In: IEEE conference on computer vision and pattern recognition, pp 4651–4659
Yu Y, Ko H, Choi J, Kim G (2017) End-to-end concept word detection for video captioning, retrieval, and question answering. In: IEEE conference on computer vision and pattern recognition, pp 3165–3173
Zhou B, Khosla A, Lapedriza A, Oliva A, Torralba A (2016) Learning deep features for discriminative localization. In: IEEE conference on computer vision and pattern recognition, pp 2921–2929
Zhou L, Xu C, Koch P, Corso JJ (2016) Image caption generation with text-conditional semantic attention. arXiv:160604621.2
Acknowledgements
This work was supported by the National Natural Science Foundation of China [61806213]
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Wang, S., Lan, L., Zhang, X. et al. GateCap: Gated spatial and semantic attention model for image captioning. Multimed Tools Appl 79, 11531–11549 (2020). https://doi.org/10.1007/s11042-019-08567-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-019-08567-0