
Abstract
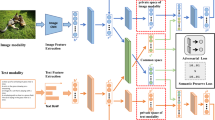
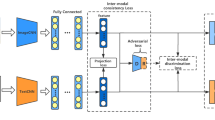
Cross-modal retrieval aims to search the semantically similar instances from the other modalities given a query from one modality. However, the differences of the distributions and representations between different modalities make that the similarity of different modalities can not be measured directly. To address this problem, in this paper, we propose a novel semantic consistent adversarial cross-modal retrieval (SC-ACMR), which learns semantic consistent representation for different modalities under adversarial learning framework by considering the semantic similarity from intra-modality and inter-modality. Specifically, for intra-modality, we minimize the intra-class distances. For the inter-modality, we require class center of different modalities with same semantic label to be as close as possible, and also minimize the distances between the samples and the class center with same semantic label from different modalities. Furthermore, we preserve the semantic similarity of transformed features of different modalities through a semantic similarity matrix. Comprehensive experiments on two benchmark datasets are conducted and the experimental results show that the proposed method have learned more compact semantic representations and achieved better performance than many existing methods in cross-modal retrieval.











Similar content being viewed by others

References
Andrew G, Arora R, Bilmes J, Livescu K (2013) Deep canonical correlation analysis. In: The 30th international conference on machine learning (ICML), pp 1247–1255
Chua TS, Tang J, Hong R, Li H, Luo Z, Zheng Y (2009) Nus-wide: a real-world web image database from national university of singapore. In: ACM International conference on image and video retrieval, pp 48
Costa PJ, Coviello E, Doyle G, Rasiwasia N, Lanckriet GR, Levy R, Vasconcelos N (2014) On the role of correlation and abstraction in cross-modal multimedia retrieval. IEEE Trans Pattern Anal Mach Intell 36(3):521–35
Deng C, Chen Z, Liu X, Gao X, Tao D (2018) Triplet-based deep hashing network for cross-modal retrieval. IEEE Trans Image Process 27(8):3893–3903
Dong S, Gao Z, Sun S, Wang X, Li M, Zhang H, Yang G, Liu H, Li S (2018) Holistic and deep feature pyramids for saliency detection. In: British machine vision conference (BMVC), Northumbria University, Newcastle, UK, September 3–6, p 67
Feng F, Wang X, Li R (2014) Cross-modal retrieval with correspondence autoencoder. The 22nd International conference on multimedia (ACM):7–16
Gao L, Guo Z, Zhang H, Xu X, Shen HT (2017) Video captioning with attention-based lstm and semantic consistency. IEEE Trans Multimedia 19(9):2045–2055
Gao Z, Li Y, Sun Y, Yang J, Xiong H, Zhang H, Liu X, Wu W, Liang D, Li S (2018) Motion tracking of the carotid artery wall from ultrasound image sequences: a nonlinear state-space approach. IEEE Trans Med Imaging 37(1):273–283
Gao Z, Xiong H, Liu X, Zhang H, Ghista D, Wu W, Li S (2017) Robust estimation of carotid artery wall motion using the elasticity-based state-space approach. Med Image Anal 37:1–21
Gong Y, Ke Q, Isard M, Lazebnik S (2014) A multi-view embedding space for modeling internet images, tags, and their semantics. Int J Comput Vis 106 (2):210–233
Gong M, Zhang K, Liu T, Tao D, Glymour C, Schölkopf B (2016) Domain adaptation with conditional transferable components. In: Proceedings of the 33nd international conference on machine learning (ICML), New York City, NY, USA, June 19–24, vol 48, pp 2839–2848
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative adversarial nets. In: Advances in neural information processing systems (NIPS), pp 2672–2680
Hardoon DR, Szedmak S, Shawetaylor J (2004) Canonical correlation analysis: an overview with application to learning methods. Neural Comput 16(12):2639–2664
He Z, Li X, You X, Tao D, Tang YY (2016) Connected component model for multi-object tracking. IEEE Trans Image Process 25(8):3698–3711
Hua Y, Tian H, Cai A, Shi P (2016) Cross-modal correlation learning with deep convolutional architecture. In: Visual communications and image processing, pp 1–4
Huang X, Peng Y, Yuan M (2018) Mhtn: Modal-adversarial hybrid transfer network for cross-modal retrieval. IEEE Transactions on Cybernetics, https://doi.org/10.1109/TCYB.2018.2879846
Jacobs DW, Daume H, Kumar A, Sharma A (2012) Generalized multiview analysis: a discriminative latent space. In: IEEE conference on computer vision and pattern recognition (CVPR), pp 2160– 2167
Jiang X, Wu F, Li X, Zhao Z, Lu W, Tang S, Zhuang Y (2015) Deep compositional cross-modal learning to rank via local-global alignment. In: International conference on multimedia ACM, pp 69–78
Kang C, Xiang S, Liao S, Xu C, Pan C (2015) Learning consistent feature representation for cross-modal multimedia retrieval. IEEE Trans Multimedia 17 (3):370–381
Li C, Deng C, Li N, Liu W, Gao X, Tao D (2018) Self-supervised adversarial hashing networks for cross-modal retrieval. arXiv:1804.01223
Li H, Xu X, Lu H, Yang Y, Shen F, Shen HT (2017) Unsupervised cross-modal retrieval through adversarial learning. In: IEEE international conference on multimedia and expo, pp 1153–1158
Liu Q, Lu X, He Z, Zhang C, Wen-sheng C (2017) Deep convolutional neural networks for thermal infrared object tracking. Knowl-Based Syst 134:189–198
Lu H, Li B, Zhu J, Li Y, Li Y, Xu X, He L, Li X, Li J, Serikawa S (2017) Wound intensity correction and segmentation with convolutional neural networks. Concurrency & Computation Practice & Experience. https://doi.org/10.1002/cpe.3927
Lu H, Li Y, Chen M, Kim H, Serikawa S (2018) Brain intelligence: Go beyond artificial intelligence. Mobile Networks & Applications 23(2):368–375
Lu H, Li Y, Mu S, Wang D, Kim H, Serikawa S Motor anomaly detection for unmanned aerial vehicles using reinforcement learning. IEEE Internet Things J, https://doi.org/10.1109/JIOT.2017.2737479
Lu H, Li Y, Uemura T, Ge Z, Xu X, Li H, Serikawa S, Kim H (2017) Fdcnet: filtering deep convolutional network for marine organism classification. Multimed Tools Appl(2):1–14
Lu H, Li Y, Uemura T, Kim H, Serikawa S (2018) Low illumination underwater light field images reconstruction using deep convolutional neural networks. Futur Gener Comput Syst. https://doi.org/10.1016/j.future.2018.01.001
Maaten Laurens van der, Hinton G (2008) Visualizing data using t-sne. J Mach Learn Res 9(11):2579–2605
Ngiam J, Khosla A, Kim M, Nam J, Lee H, Ng AY (2011) Multimodal deep learning. In: The 28th international conference on machine learning (ICML), Washington, USA, from June 28 to July 2, 2011, pp 689–696
Peng Y, Huang X, Zhao Y (2017) An overview of cross-media retrieval: Concepts, methodologies, benchmarks and challenges. IEEE Trans Circuits Syst Video Technol: 1–14
Peng Y, Qi J, Yuan Y Cm-gans: Cross-modal generative adversarial networks for common representation learning. arXiv:1710.05106
Peng Y, Zhang J, Yuan M (2018) Sch-gan: Semi-supervised cross-modal hashing by generative adversarial network. IEEE Transactions on Cybernetics, https://doi.org/10.1109/TCYB.2018.2868826
Rasiwasia N, Pereira JC, Coviello E, Doyle G, Lanckriet GRG, Levy R, Vasconcelos N (2010) A new approach to cross-modal multimedia retrieval. In: International conference on multimedia (ACM), pp 251–260
Rosipal R, Kramer N (2006) Overview and recent advances in partial least squares. International Statistical and Optimization Perspectives Workshop 3940:34–51
Song J, Yuyu G, Gao L, Li X, Hanjalic A, Shen HT (2018) From deterministic to generative: Multi-modal stochastic rnns for video captioning. IEEE Transactions on Neural Networks and Learning Systems, https://doi.org/10.1109/TNNLS.2018.2851077
Song J, Zhang H, Li X, Gao L, Wang M, Hong R (2018) Self-supervised video hashing with hierarchical binary auto-encoder. IEEE Trans Image Process 27 (7):3210
Srivastava N, Salakhutdinov R (2012) Learning representations for multimodal data with deep belief nets. ICML workshop:79
Tenenbaum JB, Freeman WT (2000) Separating style and content with bilinear models. Neural Comput 12(6):1247–1283
Wang B, Yang Y, Xu X, Hanjalic A, Shen HT (2017) Adversarial cross-modal retrieval. In: International conference on multimedia (ACM), pp 154–162
Wang K, He R, Wang W, Wang L, Tan T (2013) Learning coupled feature spaces for cross-modal matching. IEEE International Conference on Computer Vision (ICCV):2088–2095
Wang J, He Y, Kang C, Xiang S, Pan C (2015) Image-text cross-modal retrieval via modality-specific feature learning. In: International conference on multimedia retrieval (ACM), pp 347–354
Wang K, He R, Wang L, Wang W, Tan T (2016) Joint feature selection and subspace learning for cross-modal retrieval. IEEE Trans Pattern Anal Mach Intell (PAMI) 38(10):2010–2023
Wang K, Yin Q, Wang W, Wu S, Wang L (2016) A comprehensive survey on cross-modal retrieval. arXiv:1607.06215
Wei Y, Zhao Y, Lu C , Wei S, Liu L, Zhu Z, Yan S (2016) Cross-modal retrieval with cnn visual features: a new baseline. IEEE Transactions on Cybernetics 47(2):449–460
Xi Z, Zhou S, Feng J, Lai H, Li B, Pan Y, Yin J, Yan S (2017) Hashgan: Attention-aware deep adversarial hashing for cross modal retrieval. arXiv:1711.09347
Xu T, Yang Y, Deng C, Gao X (2016) Coupled dictionary learning with common label alignment for cross-modal retrieval. IEEE Trans Multimedia 18 (2):208–218
Xu X, Li H, Shimada A, Taniguchi RI, Huimin L (2016) Learning unified binary codes for cross-modal retrieval via latent semantic hashing. Neurocomputing 213:191–203
Xu X, Li H, Lu H, Gao L, Ji Y (2018) Deep adversarial metric learning for cross-modal retrieval. World Wide Web:1–16. https://doi.org/10.1007/s11280-018-0541-x
Xu X, Shen F, Yang Y, Shen HT, Li X (2017) Learning discriminative binary codes for large-scale cross-modal retrieval. IEEE Trans Image Process 26(5):2494–2507
Xu X, Song J, Lu H, Yang Y, Shen F, Zi H (2018) Modal-adversarial semantic learning network for extendable cross-modal retrieval. In: International conference on multimedia retrieval (ICMR), Yokohama, Japan, June 11–14, pp 46–54. https://doi.org/10.1145/3206025.3206033
Yao T, Mei T, Ngo CW (2015) Learning query and image similarities with ranking canonical correlation analysis. In: IEEE International conference on computer vision (ICCV), pp 28–36
Zhai X, Peng Y, Xiao J (2014) Learning cross-media joint representation with sparse and semisupervised regularization. IEEE Trans Circuits Syst Video Technol 24 (6):965–978
Acknowledgments
Weihua Ou and Quan Zhou are the corresponding author. This work was supported by the National Natural Science Foundation of China (No. 61762021,61502208,61876093, 61881240048), Natural Science Foundation of Guizhou Province (Grant No.[2017]1130, [2017]5726-32), Key Disciplines of Guizhou Province (ZDXK[2016]8), the 2014 Ph.D. Recruitment Program of Guizhou Normal University, Natural Science Foundation of Jiangsu Province (Grant No.BK20150522,BK20181393), Foundation of Guizhou Educational Department (KY[2016]027), HIRP Open 2018 Project of Huawei. International Postdoctoral Exchange Fellowship Program of China Postdoctoral Council (No. 20180051).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Ou, W., Xuan, R., Gou, J. et al. Semantic consistent adversarial cross-modal retrieval exploiting semantic similarity. Multimed Tools Appl 79, 14733–14750 (2020). https://doi.org/10.1007/s11042-019-7343-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-019-7343-8