
Abstract
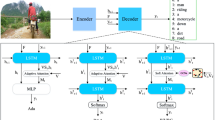
For automated visual captioning, existing neural encoder-decoder methods commonly use a simple sequence-to-sequence or an attention-based mechanism. The attention-based models pay attention to specific visual areas or objects; using a single heat map that indicates which portion of the image is most important rather than treating the objects (within the image) equally. These models are usually a mixture of Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN) architectures. CNN’s generally extract global visual signals that only provide global information of main objects, attributes, and their relationship, but fail to provide local (regional) information within objects, such as lines, corners, curve and edges. On one hand, missing some of the information and details of local visual signals may lead to misprediction, misidentification of objects or completely missing the main object(s). On the other hand, additional visual signals information produces meaningless and irrelevant description, which may be coming from objects in foreground or background. To address these concerns, we created a new joint signals attention image captioning model for global and local signals that is adaptive by nature. Primarily, proposed model extracts global visual signals at image-level and local visual signals at object-level. The joint signal attention model (JSAM) plays a dual role in visual signal extraction and non-visual signal prediction. Initially, JSAM selects meaningful global and regional visual signals to discard irrelevant visual signals and integrates selected visual signals smartly. Subsequently, in a language model, smart JSAM decides at each time-step (level) on how to attend visual or non-visual signals to generate accurate, descriptive, and elegant sentences. Lastly, we examine the efficiency and superiority of the projected model over recent similar image captioning models by conducting essential experimentations on the MS-COCO dataset.









Similar content being viewed by others


References
Anderson P, He X, Buehler C, Teney D, Johnson M, Gould S, Zhang L (2018) Bottom-up and top-down attention for image captioning and visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 6077–6086
Bahdanau D, Cho K, Bengio Y (2014) Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473
Chen H, Ding G, Lin Z, Zhao S, Han J (2018) Show, observe and tell: attribute-driven attention model for image captioning. In: IJCAI, pp 606-612
Devlin J, Cheng H, Fang H, Gupta S, Deng L, He X, Zweig G, Mitchell M (2015). Language models for image captioning: the quirks and what works. arXiv:1505.01809
Donahue J, Anne Hendricks L, Guadarrama S, Rohrbach M, Venugopalan S, Saenko K, Darrell T (2015) Long-term recurrent convolutional networks for visual recognition and description. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2625-2634
Fan DP, Wang W, Cheng MM, Shen J (2019) Shifting more attention to video salient object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 8554–8564
Farhadi A, Hejrati M, Sadeghi MA, Young P, Rashtchian C, Hockenmaier J, Forsyth D (2010) Every picture tells a story: generating sentences from images. In: European conference on computer vision, pp 15–29. Springer, Berlin, Heidelberg
Gong Y, Wang L, Hodosh M, Hockenmaier J, Lazebnik S (2014) Improving image-sentence embeddings using large, weakly annotated photo collections. In: European conference on computer vision, pp 529–545. Springer, Cham
Gupta A, Mannem P (2012) From image annotation to image description. In: International conference on neural information processing, pp 196-204. Springer, Berlin, Heidelberg
Karpathy A, Fei-Fei L (2015) Deep visual-semantic alignments for generating image descriptions. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3128–3137
Kingma DP, Welling M (2013) Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114
Kiros R, Salakhutdinov R, Zemel R (2014a) Multimodal neural language models. In: International conference on machine learning, pp 595–603
Kulkarni G, Premraj V, Ordonez V, Dhar S, Li S, Choi Y, Berg TL (2013) Babytalk: understanding and generating simple image descriptions. IEEE Trans Pattern Anal Mach Intell 35(12):2891–2903
Kuznetsova P, Ordonez V, Berg AC, Berg TL, Choi Y (2012). Collective generation of natural image descriptions. In: Proceedings of the 50th annual meeting of the Association for Computational Linguistics: Long papers-volume 1, pp 359–368. Association for Computational Linguistics.
Kuznetsova P, Ordonez V, Berg TL, Choi Y (2014) Treetalk: composition and compression of trees for image descriptions. Transactions of the Association for Computational Linguistics 2:351–362
Lavie A, & Agarwal A (2007, June). METEOR: An automatic metric for MT evaluation with high levels of correlation with human judgments. In Proceedings of the Second Workshop on Statistical Machine Translation (pp. 228–231).
Li L, Tang S, Deng L, Zhang Y, Tian Q (2017) Image caption with global-local attention. In: Thirty-First AAAI Conference on Artificial Intelligence
Long C, Yang X, Xu C (2019) Cross-domain personalized image captioning. Multimedia Tools and Applications, 1–16.
Lu J, Xiong C, Parikh D, Socher R (2017) Knowing when to look: adaptive attention via a visual sentinel for image captioning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 375–383
Mitchell M, Han X, Dodge J, Mensch A, Goyal A, Berg A, Daumé III, H (2012) Midge: generating image descriptions from computer vision detections. In: Proceedings of the 13th conference of the European chapter of the Association for Computational Linguistics, pp 747-756. Association for Computational Linguistics
Papineni K, Roukos S, Ward T, Zhu W-J (2002) BLEU: a method for automatic evaluation of machine translation. In: Proceedings of the 40 than nual meeting on association for computational linguistics. Association for Computational Linguistics, 311–318
Ren S, He K, Girshick R, Sun J (2015) Faster R-CNN: towards real-time object detection with region proposal networks. In: Advances in neural information processing systems, pp 91–99
Sun C, Gan C, Nevatia R (2015) Automatic concept discovery from parallel text and visual corpora. In: Proceedings of the IEEE international conference on computer vision, pp 2596-2604
Vanderwende L, Banko M, Menezes A (2004) Event-centric summary generation. Working notes of DUC, pp 127–132
Vedantam R, Lawrence Zitnick C, & Parikh D (2015) Cider: Consensus-based image description evaluation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4566–4575)
Vinyals O, Toshev A, Bengio S, Erhan D (2015) Show and tell: a neural image caption generator. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3156-3164
Wang F, Jiang M, Qian C, Yang S, Li C, Zhang H, Tang X (2017) Residual attention network for image classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 3156–3164
Wang L, Chu X, Zhang W, Wei Y, Sun W, Wu C (2018a) Social image captioning: exploring visual attention and user attention. Published online Sensors (Basel) 18(2):646
Wang Q, Liu S, Ssot J, Li X (2018b) Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans Geosci Remote Sens 57(2):1155–1167
Wang T, Hu H, He C (2019) Image caption with endogenous–exogenous attention. Neural Process Lett:1–13
Xu K, Ba J, Kiros R, Cho K, Courville A, Salakhudinov R, Bengio Y (2015) Show, attend and tell: Neural image caption generation with visual attention. In: International conference on machine learning, pp 2048-2057
Yao T, Pan Y, Li Y, Mei T (2018) Exploring visual relationship for image captioning. In: Proceedings of the European conference on computer vision (ECCV), pp 684-699
You Q, Jin H, Wang Z, Fang C, Luo J (2016) Image captioning with semantic attention. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4651-4659
Yu J, Rui Y, Tao D (2014) Click prediction for web image re-ranking using multimodal sparse coding. IEEE Trans Image Process 23(5):2019–2032
Yuan Y, Xiong Z, Wang Q (2019) VSSA-NET: vertical spatial sequence attention network for traffic sign detection. IEEE Trans Image Process 28(7):3423–3434
Zhou Y, Sun Y, Honavar V (2019) Improving image captioning by leveraging knowledge graphs. arXiv preprint arXiv: 1901. 08942
Acknowledgements
This research is supported by the Fundamental Research Funds for the Central Universities (Grant no.WK2350000002). In the end, we collectively thanks all fellow researchers namely Asad Khan, Rashid Khan, M Shujah Islam, Mansoor Iqbal and, Aliya Abbasi for their insightful help that allowing us to improved the quality of revise manuscript and make it fully considerable for publication.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Naqvi, N., Ye, Z. Image captions: global-local and joint signals attention model (GL-JSAM). Multimed Tools Appl 79, 24429–24448 (2020). https://doi.org/10.1007/s11042-020-09128-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-020-09128-6