
Abstract
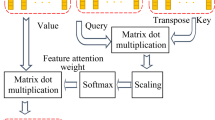
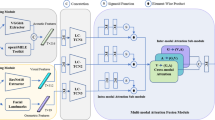
A video multimodal emotion recognition method based on Bi-GRU and attention fusion is proposed in this paper. Bidirectional gated recurrent unit (Bi-GRU) is applied to improve the accuracy of emotion recognition in time contexts. A new network initialization method is proposed and applied to the network model, which can further improve the video emotion recognition accuracy of the time-contextual learning. To overcome the weight consistency of each modality in multimodal fusion, a video multimodal emotion recognition method based on attention fusion network is proposed. The attention fusion network can calculate the attention distribution of each modality at each moment in real-time so that the network model can learn multimodal contextual information in real-time. The experimental results show that the proposed method can improve the accuracy of emotion recognition in three single modalities of textual, visual, and audio, meanwhile improve the accuracy of video multimodal emotion recognition. The proposed method outperforms the existing state-of-the-art methods for multimodal emotion recognition in sentiment classification and sentiment regression.






Similar content being viewed by others

Availability of data and material
Data and material are fully available without restriction.
References
Bairaju SPR, Ari S, Garimella RM (2019) Emotion detection using visual information with deep auto-encoders[C]//2019 IEEE 5th international conference for convergence in technology (I2CT). IEEE:1–5
Byeon YH, Kwak KC (2014) Facial expression recognition using 3D convolutional neural network[J]. Int J Adv Comput Sci Appl 5(12):107–112
Degottex G, Kane J, Drugman T et al (2014) COVAREP—A collaborative voice analysis repository for speech technologies[C]// IEEE international conference on acoustics, speech and signal processing. IEEE, Florence, pp 960–964
Drugman T, Alwan A (2011) Joint robust voicing detection and pitch estimation based on residual harmonics[C]// Twelfth Annual Conference of the International Speech Communication Association : 1973–1976.
Drugman T, Thomas M, Gudnason J, Naylor P, Dutoit T (2012) Detection of glottal closure instants from speech signals: a quantitative review[J]. IEEE Trans Audio Speech Lang Process 20(3):994–1006
Ebrahimi Kahou S, Michalski V, Konda K, et al (2015) Recurrent neural networks for emotion recognition in video[C]// Proceedings of the 2015 ACM on international conference on multimodal interaction, ACM, Seattle, Washington, USA, Nov 09-13: 467–474.
Ekman P (1992) An argument for basic emotions[J]. Cognit Emot 6(3–4):169–200
Ekman P, Freisen WV, Ancoli S (1980) Facial signs of emotional experience[J]. J Pers Soc Psychol 39(6):1125–1134
Fujisaki H, Ljungqvist M (1986) Proposal and evaluation of models for the glottal source waveform[C]// ICASSP'86. IEEE International Conference on Acoustics, Speech, and Signal Processing. IEEE, Tokyo, Japan, 11: 1605-1608.
Ghosh S, Laksana E, Morency L P, et al. (2016) Representation Learning for Speech Emotion Recognition[C]// Interspeech : 3603–3607.
Hatzivassiloglou V, McKeown K R (1997) Predicting the semantic orientation of adjectives[C]// proceedings of the 35th annual meeting of the association for computational linguistics and eighth conference of the european chapter of the association for computational linguistics. Assoc Comput Linguist Madrid, Spain, July 07 : 174–181.
Iyyer M, Manjunatha V, Boyd-Graber J, et al (2015) Deep unordered composition rivals syntactic methods for text classification[C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, 1: 1681-1691.
Kalchbrenner N, Grefenstette E, Blunsom P (2014) A convolutional neural network for modelling sentences[J]. arXiv preprint arXiv:1404.2188.
Kane J, Gobl C (2013) Wavelet maxima dispersion for breathy to tense voice discrimination[J]. IEEE Trans Audio Speech Lang Process 21(6):1170–1179
Kingma D P, Ba J (2014) Adam: a method for stochastic optimization[J]. arXiv preprint arXiv:1412.6980.
Kumawat S, Verma M, Raman S (2019) LBVCNN: local binary volume convolutional neural network for facial expression recognition from image sequences[C]//proceedings of the IEEE conference on computer vision and pattern recognition workshops.
Lee J, Tashev I (2015) High-level feature representation using recurrent neural network for speech emotion recognition[C]// Sixteenth Annual Conference of the International Speech Communication Association.
Li J, Ren F (2013) A hybrid approach for word emotion recognition[J]. IEEJ Trans Electr Electron Eng 8(6):616–626
Lim W, Jang D, Lee T (2016) Speech emotion recognition using convolutional and recurrent neural networks[C]// Asia-Pacific signal and information processing association annual summit and conference (APSIPA). IEEE, Jeju, pp 1–4
Liu Z, Shen Y, Lakshminarasimhan V B, et al (2018) Efficient low-rank multimodal fusion with modality-specific factors[C]// proceedings of the 56th annual meeting of the Association for Computational Linguistics (volume 1: long papers).
Ma L, Ju F, Wan J, Shen X (2019) Emotional computing based on cross-modal fusion and edge network data incentive[J]. Pers Ubiquit Comput 23(3–4):363–372
Moilanen K, Pulman S (2007) Sentiment composition[C]// Proceedings of RANLP , 7: 378–382.
Morency LP, Mihalcea R, Doshi P (2011) Towards multimodal sentiment analysis: harvesting opinions from the web[C]// proceedings of the 13th international conference on multimodal interfaces, ICMI 2011, Alicante, Spain, Nov 14-18, 2011. ACM:169–176
Nojavanasghari B, Gopinath D, Koushik J, et al (2016) Deep multimodal fusion for persuasiveness prediction[C]// international conference on multimodal interfaces (ICMI). ACM.
Orjesek R, Jarina R, Chmulik M, et al (2019) DNN based music emotion recognition from raw audio signal[C]//2019 29th international conference RADIOELEKTRONIKA (RADIOELEKTRONIKA). IEEE: 1–4.
Park S, Shim HS, Chatterjee M et al (2014) Computational analysis of persuasiveness in social multimedia: a novel dataset and multimodal prediction approach[C]// proceedings of the 16th international conference on multimodal interaction. ACM, Istanbul, Turkey, Nov 12-16:50–57
Pennington J, Socher R, Manning C (2014) Glove: Global vectors for word representation[C]// Proceedings of the 2014 conference on empirical methods in natural language processing : 1532–1543.
Polanyi L, Zaenen A (2006) Contextual valence shifters[M]// computing attitude and affect in text: theory and applications. Springer, Dordrecht, pp 1–10
Poria S, Cambria E, Gelbukh A (2015) Deep convolutional neural network textual features and multiple kernel learning for utterance-level multimodal sentiment analysis[C]// Proceedings of the 2015 conference on empirical methods in natural language processing : 2539–2544.
Poria S, Cambria E, Howard N, et al (2015) Fusing audio, visual and textual clues for sentiment analysis from multimodal content[J]. Neurocomputing: S0925231215011297.
Rajagopalan S S, Morency L P (2016) Tadas Baltrus̆aitis, et al. Extending Long Short-Term Memory for Multi-View Structured Learning[M]// Computer Vision – ECCV 2016. Springer International Publishing.
Seyeditabari A, Tabari N, Gholizadeh S, et al (2019) Emotion Detection in Text: Focusing on Latent Representation[J]. arXiv preprint arXiv:1907.09369.
Shrivastava K, Kumar S, Jain DK et al (2019) An effective approach for emotion detection in multimedia text data using sequence based convolutional neural network[J]. Multimed Tools Appl 78(20):29607–29639
Socher R, Perelygin A, Wu J, et al (2013) Recursive deep models for semantic compositionality over a sentiment treebank[C]// proceedings of the 2013 conference on empirical methods in natural language processing, Seattle, WA, USA, Oct 18-21: 1631-1642.
Socher, R, et al (2013) Recursive deep models for semantic compositionality over a sentiment treebank[C]// Proceedings of the 2013 conference on empirical methods in natural language processing.
Taboada M, Brooke J, Tofiloski M, Voll K, Stede M (2011) Lexicon-based methods for sentiment analysis[J]. Comput Linguist 37(2):267–307
Takamura H, Inui T, Okumura M (2006) Latent variable models for semantic orientations of phrases[C]// 11th conference of the European chapter of the association for. Comput Linguist:201–208
Trigeorgis G, Ringeval F, Brueckner R et al (2016) Adieu features? End-to-end speech emotion recognition using a deep convolutional recurrent network[C]// IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, Shanghai, pp 5200–5204
Wang H, Meghawat A, Morency L P, et al (2017) Select-additive learning: improving generalization in multimodal sentiment analysis[C]//2017 IEEE international conference on multimedia and expo (ICME). IEEE : 949–954.
Wu X, et al (2019) Speech Emotion Recognition Using Capsule Networks[C]// ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE.
Yang B, Cardie C (2012) Extracting opinion expressions with semi-Markov conditional random fields[C]// proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning. Assoc Comput Linguist, Jeju Island, Korea, July 12-14 : 1335–1345.
Zadeh A, Chen M, Poria S, et al (2017) Tensor fusion network for multimodal sentiment analysis[J]. arXiv preprint arXiv:1707.07250.
Zadeh A, Liang P P, Mazumder N, et al (2018) Memory fusion network for multi-view sequential learning[C]//thirty-second AAAI conference on artificial intelligence.
Zadeh A, Liang P, Poria S, et al (2018) Multi-attention recurrent network for human communication comprehension[C]//thirty-second AAAI conference on artificial intelligence.
Zadeh A, Zellers R, Pincus E, et al (2016) MOSI: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos[J]. arXiv preprint arXiv:1606.06259.
Zhao J, Chen S, Wang S, et al (2018) Emotion recognition using multimodal features[C]//2018 first Asian conference on affective computing and intelligent interaction (ACII Asia). IEEE: 1–6.
Acknowledgements
This work was supported by the Zhejiang Provincial Natural Science Foundation of China [grant number LY19F020032], and National Natural Science Foundation of China [grant number U1909203, 61872322].
Funding
This study was funded by the Zhejiang Provincial Natural Science Foundation of China (grant number LY19F020032), and National Natural Science Foundation of China (grant number U1909203, 61872322).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Code availability
Custom code is available without restriction.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Huan, RH., Shu, J., Bao, SL. et al. Video multimodal emotion recognition based on Bi-GRU and attention fusion. Multimed Tools Appl 80, 8213–8240 (2021). https://doi.org/10.1007/s11042-020-10030-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-020-10030-4