
Abstract
Keyword spotting (KWS) is the task of detecting some specific words of interest in a text or speech signal. The intention or context of a conversation posted on different social platforms can be predicted by detecting the keywords. KWS in continuous speech is challenging due to variation in pitch, speaking rate of the speakers and environment-induced mismatches between training and testing speech. This paper proposes an approach for penalizing the pitch effect on the short-term Fourier transform magnitude spectra (STFT-MS) to reduce the pitch effect on the most frequently used Mel-frequency cepstral coefficient (MFCC) feature for the development of KWS system. To achieve this, we have employed moving average filtering of STFT-MS over different frequency windows for vowel and non-vowel frames. The validity of the proposed spectral filtering approach is verified by analyzing the pitch effect on filtered STFT-MS and evaluating keyword spotting performances without and with vocal-tract length normalization and data-augmented training through explicit pitch modification. The MFCC extracted from the filtered spectra is less affected by pitch, which enhances the keyword spotting performance in pitch-mismatch test cases without loss of performance in match test cases.




Similar content being viewed by others

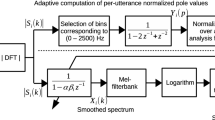
References
Batliner A, Blomberg M, D’Arcy S, Elenius D, Giuliani D, Gerosa M, Hacker C, Russell M, Steidl S, Wong M (2005) The PF_STAR children’s speech corpus. In: Proc. Ninth European Conference on Speech Communication and Technology, pp 1–4
Cardillo PS, Clements M, Miller MS (2002) Phonetic searching vs. LVCSR: How to find what you really want in audio archives. International Journal of Speech Technology 5(1):9–22
Chen G, Khudanpur S, Povey D, Trmal J, Yarowsky D, Yilmaz O (2013) Quantifying the value of pronunciation lexicons for keyword search in lowresource languages. In: Proc. International Conference on Acoustics, Speech and Signal Processing, pp 8560–8564
Davis S, Mermelstein P (1980) Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Transactions on Acoustics, Speech, and Signal Processing 28(4):357–366
Dubois C, Charlet D (2008) Using textual information from lvcsr transcripts for phonetic-based spoken term detection. In: Proc. International Conference on Acoustics, Speech and Signal Processing, pp 4961–4964
Garofolo J, Lamel L, Fisher W, Fiscus J, Pallett D, Dahlgren N, Zue V (1993) Timit acoustic-phonetic continuous speech corpus ldc93s1. Linguistic Data Consortium, 33
Gerosa M, Giuliani D, Narayanan S, Potamianos A (2009) A review of ASR technologies for children’s speech. In: Proc. of the 2nd Workshop on Child, Computer and Interaction, pp 7:1–7:8
Hermes DJ (1990) Vowel onset detection. The Journal of the Acoustical Society of America 87(2):866–873
Kumar A, Pradhan G (2018) Detection of vowel onset and offset points using non-local similarity between dwt approximation coefficients. Electron Lett 54(11):722–724
Kumar A, Shahnawazuddin S, Pradhan G (2017) Non-local estimation of speech signal for vowel onset point detection in varied environments. Proc. Interspeech, pp 429–433
Kumari K, Singh JP (2020) Identification of cyberbullying on multi-modal social media posts using genetic algorithm. Transactions on Emerging Telecommunications Technologies, pp 1–13
Kumari K, Singh JP, Dwivedi YK, Rana NP (2020) Towards cyberbullying-free social media in smart cities: a unified multi-modal approach. Soft Comput 24(15):11059–11070
Lee L, Rose R (1998) A frequency warping approach to speaker normalization. IEEE Transactions on Speech and Audio Processing 6(1):49–60
Lee S, Potamianos A, Narayanan SS (1999) Acoustics of children’s speech: Developmental changes of temporal and spectral parameters. The Journal of the Acoustical Society of America 105(3):1455–1468
Mishne G, Carmel D, Hoory R, Roytman A, Soffer A (2005) Automatic analysis of call-center conversations. In: Proc. of the 14th ACM international conference on Information and knowledge management, pp 453–459
Mittal VK, Yegnanarayana B, Bhaskararao P (2014) Study of the effects of vocal tract constriction on glottal vibration. The Journal of the Acoustical Society of America 136(4):1932–1941
Motlicek P, Valente F, Szoke I (2012) Improving acoustic based keyword spotting using LVCSR lattices. In: Proc. International Conference on Acoustics, Speech and Signal Processing, pp 4413–4416
Narayanan S, Potamianos A (2002) Creating conversational interfaces for children. IEEE Transactions on Speech and Audio Processing 10(2):65–78
Pattanayak B, Rout JK, Pradhan G (2019) Adaptive spectral smoothening for development of robust keyword spotting system. IET Signal Processing 13(5):544–550
Paul S, Saha S, Hasanuzzaman M (2020) Identification of cyberbullying: A deep learning based multimodal approach. Multimedia Tools and Applications, pp 1–20
Potamianos A, Narayanan S (2003) Robust recognition of children’s speech. IEEE Transactions on Speech and Audio processing 11(6):603–616
Povey D, Ghoshal A, Boulianne G, Burget L, Glembek O, Goel N, Hannemann M, Motlicek P, Qian Y, Schwarz P et al (2011) The Kaldi speech recognition toolkit. In: Proc. Workshop on Automatic speech recognition and understanding, pp 1–4
Pradhan G, Kumar A, Shahnawazuddin S (2017) Excitation source features for improving the detection of vowel onset and offset points in a speech sequence. Proc. Interspeech 2017, pp 1884–1888
Pradhan G, Prasanna SRM (2013) Speaker verification by vowel and nonvowel like segmentation. IEEE Transactions on Audio Speech and Language Processing 21(4):854–867
Prasanna SRM, Govind D, Rao KS, Yegnanarayana B (2010) Fast prosody modification using instants of significant excitation. In: Proc. Speech Prosody, pp 1–4
Prasanna SRM, Pradhan G (2011) Significance of vowel-like regions for speaker verification under degraded conditions. IEEE Transactions on Audio Speech and Language Processing 19(8):2552–2565
Prasanna SRM, Reddy BVS, Krishnamoorthy P (2009) Vowel onset point detection using source, spectral peaks, and modulation spectrum energies. IEEE Transactions on Audio Speech and Language Processing 17(4):556–565
Rao KS, Yegnanarayana B (2009) Duration modification using glottal closure instants and vowel onset points. Speech Comm 51(12):1263–1269
Rath SP, Povey D, Veselỳ K, Cernockỳ J (2013) Improved feature processing for deep neural networks.. In: Proc. Interspeech, pp 109–113
Robinson T, Fransen J, Pye D, Foote J, Renals S (1995) WSJCAMO: a British English speech corpus for large vocabulary continuous speech recognition. In: Proc. International Conference on Acoustics, Speech and Signal Processing, pp 81–84
Sai BT, Yadav IC, Shahnawazuddin S, Pradhan G (2018) Enhancing pitch robustness of speech recognition system through spectral smoothing. In: Proc. International Conference on Signal Processing and Communications, pp 242–246
Shahnawazuddin S, Deepak KT, Pradhan G, Sinha R (2017) Enhancing noise and pitch robustness of children’s asr. In: Proc. International Conference on Acoustics, Speech, and Signal Processing, pp 5225–5229
Shahnawazuddin S, Maity K, Pradhan G (2019) Improving the performance of keyword spotting system for children’s speech through prosody modification. Digital Signal Processing 86:11–18
Shahnawazuddin S, Adiga N, Kathania HK, Pradhan G, Sinha R (2018) Studying the role of pitch-adaptive spectral estimation and speaking-rate normalization in automatic speech recognition. Digital Signal Processing 79:142–151
Shahnawazuddin S, Sinha R, Pradhan G (2017) Pitch-normalized acoustic features for robust children’s speech recognition. IEEE Signal Processing Letters 24(8):1128–1132
Sinha R, Shahnawazuddin S (2018) Assessment of pitch-adaptive front-end signal processing for children’s speech recognition. Computer Speech & Language 48:103–121
Smídl L, Psutka JV (2006) Comparison of keyword spotting methods for searching in speech. In: Proc. Ninth International Conference on Spoken Language Processing
Srinivas N, Pradhan G, Kumar PK (2018) An efficient hardware architecture for detection of vowel-like regions in speech signal. Integration 63:185–195
Srinivas N, Pradhan G, Kumar PK (2019) Detection of vowel-like speech: an efficient hardware architecture and it’s FPGA prototype. Microsyst Technol 25(4):1333–1343
Stevens KN (2000) Acoustic phonetics. The MIT Press Cambridge, Massachusetts, London, England
Tabibian S, Akbari A, Nasersharif B (2018) Discriminative keyword spotting using triphones information and n-best search. Inf Sci 423:157–171
Thambiratnam Albert JK (2005) Acoustic keyword spotting in speech with applications to data mining. Ph.D. Thesis, Queensland University of Technology
Vuppala AK, Yadav J, Chakrabarti S, Rao KS (2012) Vowel onset point detection for low bit rate coded speech. IEEE Transactions on Audio Speech and Language Processing 20(6):1894–1903
Vuppala AK, Rao KS, Chakrabarti S (2012) Improved vowel onset point detection using epoch intervals. AEU- International Journal of Electronics and Communications 66(8):697–700
Wallace RG, Vogt RJ, Sridharan S (2007) A phonetic search approach to the 2006 NIST spoken term detection evaluation, pp 1–4
Wang D, Frankel J, Tejedor J, King S (2008) A comparison of phone and grapheme-based spoken term detection. In: Proc. International Conference on Acoustics, Speech and Signal Processing, pp 4969–4972
Wang JF, Hu CH, Hung S, Lee JY (1991) A hierarchical neural network based C/V segmentation algorithm for Mandarin speech recognition. IEEE Transactions on Signal Processing 39(9):2141–2146
Wegmann S, Faria A, Janin A, Riedhammer K, Morgan N (2013) The tao of ATWV: Probing the mysteries of keyword search performance. In: Proc. Workshop on Automatic Speech Recognition and Understanding, pp 192–197
Yadav IC, Pradhan G (2019) Significance of pitch-based spectral normalization for children’s speech recognition. IEEE Signal Processing Letters 26 (12):1822–1826
Yadav IC, Kumar A, Shahnawazuddin S, Pradhan G (2018) Non-uniform spectral smoothing for robust children’s speech recognition.. In: Proc. Interspeech, pp1601–1605
Yadav IC, Shahnawazuddin S, Govind D, Pradhan G (2018) Spectral smoothing by variational mode decomposition and its effect on noise and pitch robustness of ASR system. In: Proc. International Conference on Acoustics, Speech and Signal Processing, pp 5629–5633
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Garnaik, S., Pradhan, G. & Sethi, K. An approach for reducing pitch induced mismatches to detect keywords in children’s speech. Multimed Tools Appl 81, 27057–27071 (2022). https://doi.org/10.1007/s11042-021-11243-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-021-11243-x