
Abstract
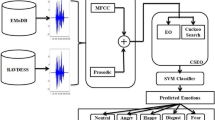
Speech plays an important role among the human communication and also a dominant source of medium for human computer interaction (HCI) to exchange information. Hence, it has always been an important research topic in the fields of Artificial Intelligence (AI) and Machine Learning (ML). However, in the traditional machine learning approach, when the dimension of the feature vector becomes quite large, it takes a huge amount of storage space and processing time for the learning algorithms. To address this problem, we have proposed a hybrid wrapper feature selection algorithm, called CEOAS, using clustering-based Equilibrium Optimizer (EO) and Atom Search Optimization (ASO) algorithm for recognizing different human emotions from speech signals. We have extracted Linear Prediction Coding (LPC) and Linear Predictive Cepstral Coefficient (LPCC) from the audio signals. Our proposed model helps to reduce the feature dimension as well as improves the classification accuracy of the learning model. The model has been evaluated on four standard benchmark datasets namely, SAVEE, EmoDB, RAVDESS, and IEMOCAP and impressive recognition accuracies of 98.01%, 98.72%, 84.62% and 74.25% respectively have been achieved which are better than many state-of-the-art algorithms.






Similar content being viewed by others


References
Barros P, Weber C, Wermter S (2015) Emotional expression recognition with a cross-channel convolutional neural network for human-robot interaction. In: 2015 IEEE- RAS 15Th international conference on humanoid robots (Humanoids), IEEE, pp 582–587
Blum A, Mitchell T (1998) Combining labeled and unlabeled data with co-training. In: Proceedings of the eleventh annual conference on Computational learning theory, pp 92–100
Boigne J, Liyanage B, Östrem T (2020) Recognizing more emotions with less data using self-supervised transfer learning. arXiv:201105585
Bookstein A, Kulyukin VA, Raita T (2002) Generalized hamming distance. Inf Retr 5(4):353–375
Burkhardt F, Paeschke A, Rolfes M, Sendlmeier WF, Weiss B (2005) A database of german emotional speech. In: Ninth european conference on speech communication and technology
Busso C, Bulut M, Lee CC, Kazemzadeh A, Mower E, Kim S, Chang JN, Lee S, Narayanan SS (2008) Iemocap: Interactive emotional dyadic motion capture database. Lang Resour Eval 42(4):335–359
Chatterjee B, Bhattacharyya T, Ghosh KK, Singh PK, Geem ZW, Sarkar R (2020) Late acceptance hill climbing based social ski driver algorithm for feature selection. IEEE Access 8:75393–75408
Chen L, Su W, Feng Y, Wu M, She J, Hirota K (2020) Two-layer fuzzy multiple random forest for speech emotion recognition in human-robot interaction. Inf Sci 509:150–163
Chibelushi CC, Bourel F (2003) Facial expression recognition: a brief tutorial overview. CVonline: On-Line Compendium of Computer Vision 9
Cummins N, Amiriparian S, Hagerer G, Batliner A, Steidl S, Schuller BW (2017) An image-based deep spectrum feature representation for the recognition of emotional speech. In: Proceedings of the 25th ACM international conference on Multimedia, pp 478–484
Daneshfar F, Kabudian SJ, Neekabadi A (2020) Speech emotion recognition using hybrid spectral-prosodic features of speech signal/glottal waveform, metaheuristic-based dimensionality reduction, and gaussian elliptical basis function network classifier. Appl Acoust 166:107360
Das A, Das HS, Das HS (2020) Impact of cuckoo algorithm in speech processing. In: Applications of cuckoo search algorithm and its variants, Springer, pp 207–228
Dey A, Chattopadhyay S, Singh PK, Ahmadian A, Ferrara M, Sarkar R (2020) A hybrid meta-heuristic feature selection method using golden ratio and equilibrium optimization algorithms for speech emotion recognition, vol 8
Emary E, Zawbaa HM, Grosan C, Hassenian AE (2015) Feature subset selection approach by gray-wolf optimization. In: Afro-European conference for industrial advancement, Springer, pp 1–13
Eyben F, Weninger F, Gross F, Schuller B (2013) Recent developments in opensmile, the munich open-source multimedia feature extractor. In: Proceedings of the 21st ACM international conference on Multimedia, pp 835–838
Faramarzi A, Heidarinejad M, Stephens B, Mirjalili S (2020) Equilibrium optimizer: a novel optimization algorithm. Knowl-Based Syst 191:105190
Fayek HM, Lech M, Cavedon L (2017) Evaluating deep learning architectures for speech emotion recognition. Neural Netw 92:60–68
Geem ZW, Kim JH, Loganathan GV (2001) A new heuristic optimization algorithm:, harmony search. simulation 76(2):60–68
Ghosh KK, Ahmed S, Singh PK, Geem ZW, Sarkar R (2020a) Improved binary sailfish optimizer based on adaptive β-hill climbing for feature selection. IEEE Access 8:83548–83560
Ghosh M, Guha R, Alam I, Lohariwal P, Jalan D, Sarkar R (2020) Binary genetic swarm optimization: A combination of ga and pso for feature selection. J Intell Syst 29(1):1598–1610
Gideon J, Provost EM, Mcinnis M (2016) Mood state prediction from speech of varying acoustic quality for individuals with bipolar disorder. In: 2016 IEEE International conference on acoustics, speech and signal processing (ICASSP) IEEE pp 2359-2363
Goldberg DE, Samtani MP (1986) Engineering optimization via genetic algorithm. In: Electronic computation, ASCE, pp 471–482
Golilarz NA, Addeh A, Gao H, Ali L, Roshandeh AM, Munir HM, Khan RU (2019) A new automatic method for control chart patterns recognition based on convnet and harris hawks meta heuristic optimization algorithm. IEEE Access 7:149398–149405
Guha R, Ghosh M, Singh PK, Sarkar R, Nasipuri M (2019) M-hmoga: a new multi-objective feature selection algorithm for handwritten numeral classification. J Intell Syst 29(1):1453–1467
Guha R, Ghosh M, Chakrabarti A, Sarkar R, Mirjalili S (2020) Introducing clustering based population in binary gravitational search algorithm for feature selection. Appl Soft Comput 93:106341
Guha S, Das A, Singh PK, Ahmadian A, Senu N, Sarkar R (2020) Hybrid feature selection method based on harmony search and naked mole-rat algorithms for spoken language identification from audio signals. IEEE Access 8:182868–182887
Gupta H (2016) Lpc and lpcc method of feature extraction in speech recognition system. In: 2016 6Th international conference-cloud system and big data engineering (Confluence) IEEE, pp 498-502
Hajarolasvadi N, Demirel H (2019) 3d cnn-based speech emotion recognition using k-means clustering and spectrograms. Entropy 21(5):479
Huang J, Chen B, Yao B, He W (2019) Ecg arrhythmia classification using stft-based spectrogram and convolutional neural network. IEEE Access 7:92871–92880
Huang Y, Tian K, Wu A, Zhang G (2019) Feature fusion methods research based on deep belief networks for speech emotion recognition under noise condition. J Ambient Intell Humaniz Comput 10(5):1787–1798
Issa D, Demirci MF, Yazici A (2020) Speech emotion recognition with deep convolutional neural networks. Biomed Signal Process Control 59:101894
Jackson P, Haq S (2014) Surrey audio-visual expressed emotion (savee) database. University of Surrey: Guildford, UK
Karan B, Sahu SS, Mahto K (2020) Parkinson disease prediction using intrinsic mode function based features from speech signal. Biocybern Biomed Eng 40(1):249–264
Lai H, Chen H, Wu S (2020) Different contextual window sizes based rnns for multimodal emotion detection in interactive conversations. IEEE Access 8:119516–119526
Latif S, Rana R, Khalifa S, Jurdak R, Epps J (2019) Direct modelling of speech emotion from raw speech. arXiv:190403833
Liu ZT, Xie Q, Wu M, Cao WH, Mei Y, Mao JW (2018) Speech emotion recognition based on an improved brain emotion learning model. Neurocomputing 309:145–156
Livingstone SR, Russo FA (2018) The ryerson audio-visual database of emotional speech and song (ravdess): a dynamic, multimodal set of facial and vocal expressions in north american english. PloS one 13(5):e0196391
Lu Z, Cao L, Zhang Y, Chiu CC, Fan J (2020) Speech sentiment analysis via pre-trained features from end-to-end asr models. In: ICASSP 2020-2020 IEEE International conference on acoustics, speech and signal processing (ICASSP), IEEE pp 7149-7153
Mahdhaoui A, Chetouani M (2010) Emotional speech classification based on multi view characterization. In: 2010 20th international conference on pattern recognition, IEEE, pp 4488–4491
Mao S, Ching P, Lee T (2020) Eigenemo: Spectral utterance representation using dynamic mode decomposition for speech emotion classification.arXiv:200806665
Mao S, Ching P, Lee T (2020) Emotion profile refinery for speech emotion classification. arXiv:200805259
Mukherjee H, Obaidullah SM, Santosh K, Phadikar S, Roy K (2020) A lazy learning-based language identification from speech using mfcc-2 features. Int J Mach Learn Cybern 11(1):1–14
Muthusamy H, Polat K, Yaacob S (2015) Particle swarm optimization based feature enhancement and feature selection for improved emotion recognition in speech and glottal signals. PloS one 10(3):e0120344
Nagarajan S, Nettimi SSS, Kumar LS, Nath MK, Kanhe A (2020) Speech emotion recognition using cepstral features extracted with novel triangular filter banks based on bark and erb frequency scales. Digit Signal Process 104:102763
Nantasri P, Phaisangittisagul E, Karnjana J, Boonkla S, Keerativittayanun S, Rugchatjaroen A, Usanavasin S, Shinozaki T (2020) A light-weight artificial neural network for speech emotion recognition using average values of mfccs and their derivatives. In: 2020 17Th international conference on electrical engineering/electronics, computer, telecommunications and information technology (ECTI-CON) IEEE, pp 41-44
Navyasri M, RajeswarRao R, DaveeduRaju A, Ramakrishnamurthy M (2017) Robust features for emotion recognition from speech by using gaussian mixture model classification. In: International conference on information and communication technology for intelligent systems, Springer, pp 437–444
Nematollahi AF, Rahiminejad A, Vahidi B (2020) A novel meta-heuristic optimization method based on golden ratio in nature. Soft Comput 24 (2):1117–1151
Nguyen D, Nguyen K, Sridharan S, Abbasnejad I, Dean D, Fookes C (2018) Meta transfer learning for facial emotion recognition
Nwe TL, Foo SW, De Silva LC (2003) Speech emotion recognition using hidden markov models. Speech Commun 41(4):603–623
Ortega MGS, Rodríguez LF, Gutierrez-Garcia JO (2019) Towards emotion recognition from contextual information using machine learning. Journal of Ambient Intelligence and Humanized Computing pp 1–21
Osman IH, Kelly JP (1997) Meta-heuristics theory and applications. J Oper Res Soc 48(6):657–657
Pao TL, Chen YT, Yeh JH, Liao WY (2005) Combining acoustic features for improved emotion recognition in mandarin speech. In: International conference on affective computing and intelligent interaction, Springer, pp 279–285
Patil A, Samant S, Ramtekkar M, Ragaji S, Khanapuri J (2020) Intelligent voice assistant. Available at SSRN 3568721
Peng H, Zhang Z, Wang J, Shi P (2013) Audio watermarking framework using multi-objective particle swarm optimization. PhD thesis, ICIC International
Pepino L, Riera P, Ferrer L, Gravano A (2020) Fusion approaches for emotion recognition from speech using acoustic and text-based features. In: ICASSP 2020-2020 IEEE International conference on acoustics, speech and signal processing (ICASSP) IEEE, pp 6484-6488
Qazi H, Kaushik BN (2020) A hybrid technique using CNN+LSTM for speech emotion recognition. International Journal of Engineering and Advanced Technology (IJEAT) 9(5):1126–1130. https://doi.org/10.35940/ijeat.E1027.069520
Rajak R, Mall R (2019) Emotion recognition from audio, dimensional and discrete categorization using cnns. In: TENCON 2019-2019 IEEE Region 10 Conference (TENCON), IEEE, pp 301-305
Rajasekhar B, Kamaraju M, Sumalatha V (2020) A novel speech emotion recognition model using mean update of particle swarm and whale optimization-based deep belief network. Data Technologies and Applications
Rana R, Latif S, Gururajan R, Gray A, Mackenzie G, Humphris G, Dunn J (2019) Automated screening for distress: a perspective for the future. Eur J Cancer Care 28(4):e13033
Ren Z, Kong Q, Qian K, Plumbley MD, Schuller B et al (2018) Attention-based Convolutional neural networks for acoustic scene classification. In: DCASE 2018 Workshop Proceedings
Saha S, Ghosh M, Ghosh S, Sen S, Singh PK, Geem ZW, Sarkar R (2020) Feature selection for facial emotion recognition using cosine similarity-based harmony search algorithm. Appl Sci 10(8):2816
Saldanha JC, Suvarna M (2020) Perceptual linear prediction feature as an indicator of dysphonia. In: Advances in control instrumentation systems, Springer, pp 51–64
Schuller B, Rigoll G, Lang M (2003) Hidden markov model-based speech emotion recognition. In: 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003. Proceedings.(ICASSP’03)., IEEE, vol 2, pp II–1
Sheikh KH, Ahmed S, Mukhopadhyay K, Singh PK, Yoon JH, Geem ZW, Sarkar R (2020) Ehhm: Electrical harmony based hybrid meta-heuristic for feature selection. IEEE Access 8:158125–158141
Shetty S, Hegde S (2020) Automatic classification of carnatic music instruments using mfcc and lpc. In: Data management, analytics and innovation, Springer, pp 463-474
da Silva R, Valter Filho M, Souza M (2020) Interaffection of multiple datasets with neural networks in speech emotion recognition. In: Anais do XVII encontro nacional de inteligência artificial e computacional, SBC pp 342-353
Singh A (2020) Speech emotion recognition using enhanced cat swarm optimization algorithm. International Journal of Information Technology (IJIT) 6(5)
Su BH, Chang CM, Lin YS, Lee CC (2020) Improving speech emotion recognition using graph attentive bi-directional gated recurrent unit network. Proc Interspeech 2020 pp 506–510
Trelea IC (2003) The particle swarm optimization algorithm: convergence analysis and parameter selection. Inf Process Lett 85(6):317–325
Wang K, An N, Li BN, Zhang Y, Li L (2015) Speech emotion recognition using fourier parameters. IEEE Trans Affect Comput 6(1):69–75
Wang K, Su G, Liu L, Wang S (2020) Wavelet packet analysis for speaker-independent emotion recognition. Neurocomputing 398:257–264
Wolpert DH, Macready WG (1997) No free lunch theorems for optimization. IEEE Trans Evol Comput 1(1):67–82
Wu CH, Liang WB (2010) Emotion recognition of affective speech based on multiple classifiers using acoustic-prosodic information and semantic labels. IEEE Trans Affect Comput 2(1):10–21
Wu W, Zhang C, Woodland PC (2020) Emotion recognition by fusing time synchronous and time asynchronous representations. arXiv:201014102
Yogesh C, Hariharan M, Ngadiran R, Adom AH, Yaacob S, Berkai C, Polat K (2017) A new hybrid pso assisted biogeography-based optimization for emotion and stress recognition from speech signal. Expert Syst Appl 69:149–158
Yu Y, Kim YJ (2020) Attention-lstm-attention model for speech emotion recognition and analysis of iemocap database. Electronics 9(5):713
Zamil AAA, Hasan S, Baki SMJ, Adam JM, Zaman I (2019) Emotion detection from speech signals using voting mechanism on classified frames. In: 2019 International conference on robotics, electrical and signal processing techniques (ICREST), IEEE, pp 281–285
Zhao J, Mao X, Chen L (2019) Speech emotion recognition using deep 1d & 2d cnn lstm networks. Biomed Signal Process Control 47:312–323
Zhao W, Wang L, Zhang Z (2019) Atom search optimization and its application to solve a hydrogeologic parameter estimation problem. Knowl Based Syst 163:283–304
Zhao W, Zhang Z, Wang L (2020) Manta ray foraging optimization: an effective bio-inspired optimizer for engineering applications. Eng Appl Artif Intell 87:103300
Zhu Y, Shang Y, Shao Z, Guo G (2017) Automated depression diagnosis based on deep networks to encode facial appearance and dynamics. IEEE Trans Affect Comput 9(4):578–584
Acknowledgements
We would like to thank the Center for Microprocessor Applications for Training Applications and Research (CMATER) research laboratory of the Computer Science and Engineering Department, Jadavpur University, Kolkata, India for providing us the infrastructural support.
Funding
The authors hereby declare that no funding from any research organisations or research companies has been provided to conduct this research work.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The author declare that there have no conflict of interest regarding the publication of the paper.
Additional information
Informed Consent
No informed consent was required since no animals or human were involved.
Human and Animal Rights
This article does not contain any studies with human or animal subjects performed by any of the authors.
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Chattopadhyay, S., Dey, A., Singh, P.K. et al. A feature selection model for speech emotion recognition using clustering-based population generation with hybrid of equilibrium optimizer and atom search optimization algorithm. Multimed Tools Appl 82, 9693–9726 (2023). https://doi.org/10.1007/s11042-021-11839-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-021-11839-3