
Abstract
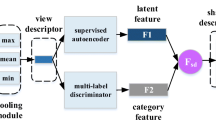
In recent years, 3D model retrieval has become a hot topic. With the development of deep learning technology, many state-of-the-art deep learning based multi-view 3D model retrieval algorithms have emerged. One of the major challenges in view-based 3D model retrieval is how to achieve rotation invariant. MVCNN (Multi-View Convolutional Neural Networks) achieving higher performance while maintaining rotation invariant. However, the element-wise maximum operation across the views leads to the loss of detailed information. To address this problem, in this paper, we use a deep cross-modal learning method to treat the features of different views as different modal features. First, we select two of the views as the input of the deep multimodal learning method. Then we combine the proposed method with an improved contrastive center loss, so that we can align the features in the same subspace and obtain a higher discriminative fused feature. Experimental results show that the training of the proposed CNN (Convolutional Neural Networks) model is based on the existing MVCNN pre-trained model, which takes only 18 epochs to converge, and it obtains 90.07% in terms of mAP (mean average precision) using only the MVCNN as the backbone, which is comparable to the feature fusion algorithm PVRNet (Point-View Relation Neural Network) and much higher than the mAP of MVCNN (80.2%). The experimental results demonstrated that the proposed method avoids explicitly learning the weights for fusion of different view features, while incorporating more details into the 3D model’s final descriptor can improve the retrieval results.





Similar content being viewed by others


Data availability
The Modelnet40 can be downloaded from http://modelnet.cs.princeton.edu/. The ShapeNet Core 55 dataset can be found at https://shapenet.cs.stanford.edu/iccv17/.
Code availability
We will release the code at https://github.com/anyuecq25/MVCNN_ContrastiveCenterLoss.
References
Bai S, Bai X, Liu W, Roli F (2015) Neural shape codes for 3D model retrieval. Pattern Recognit Lett 65:15–21. https://doi.org/10.1016/J.PATREC.2015.06.022
Bai X, Bai S, Zhu Z, Latecki L (2015) 3D shape matching via two layer coding. IEEE Trans Pattern Anal Mach Intell 37(12):2361–2373. https://doi.org/10.1109/TPAMI.2015.2424863
Bai S, Bai X, Zhou Z, Zhang Z, Tian Q, Latecki L (2017) GIFT: towards scalable 3D shape retrieval. IEEE Trans Multimed 19(6):1257–1271. https://doi.org/10.1109/TMM.2017.2652071
Chang A, Funkhouser T, Guibas L, Hanrahan P, Huang Q-X, Li Z et al (2015) ShapeNet: An Information-Rich 3D Model Repository. arXiv preprint arXiv:1512.03012
Chatfield K, Simonyan K, Vedaldi A, Zisserman A (2014) Return of the devil in the details: delving deep into convolutional nets. 2014 British Machine Vision Conference. https://doi.org/10.5244/C.28.6
Chen Y (2020) IoT cloud big data and AI in interdisciplinary domains. Simul Model Pract Theory 102:102070. https://doi.org/10.1016/J.SIMPAT.2020.102070
Chen Y, Luca G (2021) Technologies supporting artificial intelligence and robotics application development. J Artif Intell Technol 1(1):1–8. https://doi.org/10.37965/JAIT.2020.0065
Chen D-Y, Tian X-P, Shen Y-T, Ouhyoung M (2003) On Visual Similarity Based 3D Model Retrieval. Computer Graphics Forum 22(3):223–232. https://doi.org/10.1111/1467-8659.00669
Chen Q, Fang B, Yu Y-M, Tang Y (2015) 3D CAD model retrieval based on the combination of features. Multimed Tools Appl 74(13):4907–4925. https://doi.org/10.1007/S11042-013-1850-9
Feng Y, Zhang Z, Zhao X, Ji R, Gao Y (2018) GVCNN: group-view convolutional neural networks for 3D shape recognition. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 264-272. https://doi.org/10.1109/CVPR.2018.00035
Fernandes D, Silva A, Névoa R, Simões C, Gonzalez D, Guevara M et al (2021) Point-cloud based 3D object detection and classification methods for self-driving applications: A survey and taxonomy. Inf Fusion 68:161–191. https://doi.org/10.1016/J.INFFUS.2020.11.002
Hadsell R, Chopra S, LeCun Y (2006) Dimensionality reduction by learning an invariant mapping. 2006 IEEE Conference on Computer Vision and PatternRecognition, pp 1735-1742. https://doi.org/10.1109/CVPR.2006.100
Han Z, Shang M, Liu Z, Vong C-M, Liu Y-S, Zwicker M et al (2019) SeqViews2SeqLabels: learning 3D global features via aggregating sequential views by RNN with attention. IEEE Trans Image Process 28(2):658–672. https://doi.org/10.1109/TIP.2018.2868426
He X, Zhou Y, Zhou Z, Bai S, Bai X (2018) Triplet-center loss for multi-view 3D object retrieval. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 1945-1954. https://doi.org/10.1109/CVPR.2018.00208
Jiang J, Bao D, Chen Z, Zhao X, Gao Y (2019) MLVCNN: Multi-loop-view convolutional neural network for 3D shape retrieval. Proceedings of the AAAI Conference on Artificial Intelligence, 33(01), pp 8513-8520. https://doi.org/10.1609/aaai.v33i01.33018513
Kanezaki A, Matsushita Y, Nishida Y (2018) RotationNet: Joint object categorization and pose estimation using multiviews from unsupervised viewpoints. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 5010-5019. https://doi.org/10.1109/CVPR.2018.00526
Krizhevsky A, Sutskever I, Hinton G (2017) ImageNet classification with deep convolutional neural networks. Commun ACM 60(6):84–90. https://doi.org/10.1145/3065386
Lengauer S, Komar A, Labrada A, Karl S, Trinkl E, Preiner R et al (2020) A sketch-aided retrieval approach for incomplete 3D objects. Comput Graph 87:111–122. https://doi.org/10.1016/J.CAG.2020.02.001
Li B, Johan H (2013) 3D model retrieval using hybrid features and class information. Multimed Tools Appl 62(3):821–846. https://doi.org/10.1007/S11042-011-0873-3
Li B, Lu Y, Li C, Godil A, Schreck T, Aono M et al (2014) SHREC’14 Track: Large Scale Comprehensive 3D Shape Retrieval. Co-event of the 35rd Annual Conference of the European Association for Computer Graphics (Eurographics 2014)
Li B, Lu Y, Li C, Godil A, Schreck T, Aono M et al (2015) A comparison of 3D shape retrieval methods based on a large-scale benchmark supporting multimodal queries. Comput Vis Image Underst 131:1–27. https://doi.org/10.1016/J.CVIU.2014.10.006
Li Z, Xu C, Leng B (2019) Angular triplet-center loss for multi-view 3D shape retrieval. Proceedings of the AAAI Conference on Artificial Intelligence, 33(01), pp 8682-8689. https://doi.org/10.1609/aaai.v33i01.33018682
Lian Z, Godil A, Sun X, Xiao J (2013) CM-BOF: visual similarity-based 3D shape retrieval using Clock Matching and Bag-of-Features. Mach Vis Appl 24(8):1685–1704. https://doi.org/10.1007/S00138-013-0501-5
Mademlis A, Daras P, Tzovaras D, Strintzis M (2009) 3D object retrieval using the 3D shape impact descriptor. Pattern Recogn 42(11):2447–2459. https://doi.org/10.1016/J.PATCOG.2009.04.024
Makantasis K, Doulamis A, Doulamis N, Ioannides M (2016) In the wild image retrieval and clustering for 3D cultural heritage landmarks reconstruction. Multimed Tools Appl 75(7):3593–3629. https://doi.org/10.1007/S11042-014-2191-Z
Papadakis P, Pratikakis I, Theoharis T, Perantonis S (2010) PANORAMA: A 3D Shape Descriptor Based on Panoramic Views for Unsupervised 3D Object Retrieval. Int J Comput Vision 89(2):177–192. https://doi.org/10.1007/S11263-009-0281-6
Qi C, Su F (2017) Contrastive-center loss for deep neural networks. 2017 IEEE International Conference on Image Processing, pp 2851-2855. https://doi.org/10.1109/ICIP.2017.8296803
Qi S, Ning X, Yang G, Zhang L, Long P, Cai W, Li W (2021) Review of multi-view 3D object recognition methods based on deep learning. Displays 69:102053. https://doi.org/10.1016/J.DISPLA.2021.102053
Savva M, Yu F, Su H, Aono M, Chen B, Cohen-Or D et al (2016) Large-scale 3D shape retrieval from ShapeNet core55. 3DOR ‘16 Proceedings of the Eurographics 2016 Workshop on 3D Object Retrieval, pp 89-98. https://doi.org/10.2312/3DOR.20161092
Savva M, Yu F, Su H, Kanezaki A, Furuya T, Ohbuchi R et al (2017) Large-scale 3D shape retrieval from ShapeNet Core55: SHREC’17 track. 3Dor ‘17 Proceedings of the Workshop on 3D Object Retrieval, pp 39-50. https://doi.org/10.2312/3DOR.20171050
Sfikas K, Pratikakis I, Theoharis T (2018) Ensemble of PANORAMA-based convolutional neural networks for 3D model classification and retrieval. Comput Graph 71:208–218. https://doi.org/10.1016/J.CAG.2017.12.001
Shi B, Bai S, Zhou Z, Bai X (2015) DeepPano: Deep panoramic representation for 3-D shape recognition. IEEE Signal Process Lett 22(12):2339–2343. https://doi.org/10.1109/LSP.2015.2480802
Shilane P, Min P, Kazhdan M, Funkhouser T (2004) The Princeton Shape Benchmark. Proceedings Shape Modeling Applications 2004, pp167-178. https://doi.org/10.1109/SMI.2004.1314504
Su H, Maji S, Kalogerakis E, Learned-Miller E (2015) Multi-view convolutional neural networks for 3D shape recognition. 2015 IEEE International Conference on Computer Vision, pp 945-953. https://doi.org/10.1109/ICCV.2015.114
Tangelder J, Veltkamp R (2008) A survey of content based 3D shape retrieval methods. Multimed Tools Appl 39(3):441–471. https://doi.org/10.1007/S11042-007-0181-0
Vranic D (2005) DESIRE: a composite 3D-shape descriptor. 2005 IEEE International Conference on Multimedia and Expo, pp 962-965. https://doi.org/10.1109/ICME.2005.1521584
Wang Y, Sun Y, Liu Z, Sarma S, Bronstein M, Solomon J (2019) Dynamic graph CNN for learning on point clouds. ACM Trans Graph 38(5):146. https://doi.org/10.1145/3326362
Wen Y, Zhang K, Li Z, Qiao Y (2016) A discriminative feature learning approach for deep face recognition. 2016 European Conference on Computer Vision, pp 499-515. https://doi.org/10.1007/978-3-319-46478-7_31
Wu Z, Song S, Khosla A, Yu F, Zhang L, Tang X, Xiao J (2015) 3D ShapeNets: A deep representation forvolumetric shapes. 2015 IEEE Conference on Computer Vision and PatternRecognition, pp 1912-1920. https://doi.org/10.1109/CVPR.2015.7298801
You H, Feng Y, Zhao X, Zou C, Ji R, Gao Y (2019) PVRNet: point-view relation neural network for 3D shape recognition. Proceedings of the AAAI Conference on Artificial Intelligence, 33(01), pp 9119-9126. https://doi.org/10.1609/aaai.v33i01.33019119
Zarpalas D, Daras P, Axenopoulos A, Tzovaras D, Strintzis M (2007) 3D model search and retrieval using the spherical trace transform. EURASIP J Adv Signal Process 2007(1):207–207. https://doi.org/10.1155/2007/23912
Zhen L, Hu P, Wang X, Peng D (2019) Deep supervised cross-modal retrieval. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 10394-10403. https://doi.org/10.1109/CVPR.2019.01064
Zhu Z, Wang X, Bai S, Yao C, Bai X (2016) Deep learning representation using autoencoder for 3D shape retrieval. Neurocomputing 204(204):41–50. https://doi.org/10.1016/J.NEUCOM.2015.08.127
Acknowledgements
This work was partly sponsored by the fundamental research funds for the Central Universities (XDJK2019C097), the Education Reform Project in Southwest University (2019JY046), and the National Key Research and Development Program of China (2018YFB1004201). Thanks to the Big Data Innovation Application Platform of Southwest University of China for providing computational resources. We are also grateful for the support for the maintenance of servers from Bin Jia.
Funding
This work was partly sponsored by the fundamental research funds for the Central Universities (XDJK2019C097), the Education Reform Project in Southwest University (2019JY046), and the National Key Research and Development Program of China (2018YFB1004201).
Author information
Authors and Affiliations
Contributions
Qiang Chen developed the idea for the study, Qiang Chen and Yinong Chen did the analyses and wrote the paper.
Corresponding author
Ethics declarations
Conflicts of interest/Competing interests
The authors declare no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Chen, Q., Chen, Y. Multi-view 3D model retrieval based on enhanced detail features with contrastive center loss. Multimed Tools Appl 81, 10407–10426 (2022). https://doi.org/10.1007/s11042-022-12281-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-022-12281-9