
Abstract
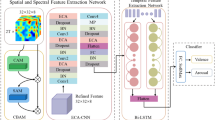
To improve the accuracy and efficiency of speech emotion recognition (SER), the acoustic feature set and speech emotion recognition model was designed based on the original speech signal, and explored the nonlinear relationship between acoustic features, the speech emotion recognition model, and the recognition task. Moreover, the original features of speech signals were studied rather than the traditional statistical features. A joint two-channel model was proposed based on the raw stacked waveform. To model raw waveform features, the convolutional recurrent neural network (CRNN) and bi-directional long short-term memory (BiLSTM) were introduced. An attention mechanism was integrated into the model to ensure that a single channel could learn the expression of the salient local region and global emotion features. Through these channels, the perception ability of speech acoustic features in multi-scale is improved, and the internal correlation between salient region and convolutional neural network is explored. The time domain and frequency domain features of speech are prominent, and the local expression of emotion is emphasized. Based on the preprocessing strategy of background separation and dimension unification, the convolutional recurrent neural network is used to extract global information. The proposed joint model could effectively integrate the advantages of the two channels. Several comparative experiments were conducted on the Interactive Emotional Dyadic Motion Capture (IEMOCAP) database. The experiments results showed that the proposed two-channel SER model could improve recognition accuracy (UA) by 5.1% and the convergence period was shortened by 58%, compared with the popular models. Furthermore, it performed best in solving data skew and improving efficiency, which proved the importance of having features and models based on the raw waveform.









Similar content being viewed by others


References
Aa A, Yz A, Mz B (2021) Exploiting dynamic spatio-temporal correlations for citywide traffic flow prediction using attention based neural networks[J]. Inf Sci 577:852–870
Aldeneh Z, Provost EM (2017) Using regional salient for speech emotion recognition[C]// IEEE international conference on acoustics. IEEE
Ali A, Zhu Y, Zakarya M (2021) A data aggregation based approach to exploit dynamic spatio-temporal correlations for citywide crowd flows prediction in fog computing[J]. Multimed Tools Appl 2:31401–31433
Bandela SR, Kumar TK (2017) Stressed speech emotion recognition using feature fusion of teager energy operator and MFCC[C]// international conference on computing. IEEE Computer Soc
Busso C, Bulut M, Lee CC, … Narayanan SS (2008) IEMOCAP: interactive emotional dyadic motion capture database[J]. Language Resourc Eval 42(4):335–359
Cho J, Pappagari R, Kulkarni P et al (2018) Deep neural networks for emotion recognition combining audio and transcripts[C]// Interspeech 2018
Chunjun Z, Wang C, Sun W (2019) Research on Speech Emotional Feature Extraction Based on Multidimensional Feature Fusion[C]// Advanced Data Mining and Applications. Springer.
Cummins N (2018) Shahin Amiriparian. Sandra Ottl, Multimodal Bag-of-Words for Cross Domains Sentiment Analysis, IEEE Interna- tional Conference on Acoustics, Speech, and Signal Processing, ICASSP
Dai D, Wu Z, Li R et al (2019) Learning discriminative features from spectrograms using center loss for speech emotion recognition [C]// 2019 IEEE international conference on acoustics, speech and signal processing (ICASSP)IEEE
Eyben F, Scherer KR, Truong KP et al (2017) The Geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing[J]. IEEE Trans Affect Comput 7(2):190–202
Gideon J, McInnis M, Provost EM (2019) Improving Cross-Corpus Speech Emotion Recognition with Adversarial Discriminative Domain Generalization (ADDoG)[J]. IEEE Trans Affect Comput PP(99):1–1
Han W, Ruan H, Chen X et al (2018) Towards temporal modelling of categorical speech emotion recognition[C]// Interspeech 2018
Hsiao P, Chen C. Effective attention mechanism in dynamic models for speech emotion recognition[C]. 2018, IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, 2018:2526–2530.
C. Huang and S. S. Narayanan, “Deep convolutional recurrent neural network with attention mechanism for robust speech emotion recognition,” in 2017 IEEE International Conference on Multimedia and Expo (ICME), 2017, pp. 583–588.
Jassim WA, Paramesran R, Harte N (2010) Speech emotion classification using combined neurogram and INTERSPEECH 2010 Paralinguistic challenge features[J]. Iet Signal Processing 11(5):587–595
Juvela L, Bollepalli B, Tsiaras V, … Alku P (2019) GlotNet—A raw waveform model for the glottal excitation in statistical parametric speech synthesis[J]. IEEE/ACM Trans Audio, Speech, and Language Processing 27(6):1019–1030
Kim E (2019) Jong won shin: DNN-based emotion recognition based on bottleneck acoustic features and lexical features. ICASSP:6720–6724
Latif S, Rana R, Khalifa S (2019) Direct modelling of speech emotion from raw speech[C]// Interspeech 2019
Jinkyu Lee and Ivan Tashev, High-level feature representation using recurrent neural network for speech emotion recognition, in Interspeech, 2015.
Li Y, Zhao T, and Kawahara T (2019) “Improved end-to-end speech emotion recognition using self attention mechanism and multitask learning,” in INTERSPEECH, .
Lin Jiang, Ping Tan, Junfeng Yang. Speech emotion recognition using emotion perception spectral feature[J]. Concurrency Comput Pract Exp, 2019(11):e5427.
Liu S , Cao Y , Meng H (2020) Multi-Target Emotional Voice Conversion With Neural Vocoders[J].
Liu ZT, Xie Q, Wu M, … Mao JW (2018) Speech emotion recognition based on an improved brain emotion learning model[J]. Neurocomputing 309:145–156
Mao Q, Ming D, Huang Z et al (2014) Learning salient features for speech emotion recognition using convolutional neural networks[J]. IEEE Trans Multimedia 16(8):2203–2213
Ming-hao YANG, Jian-hua TAO, Hao LI et al (2014) Nature multimodal human-computer-interaction dialog system [J]. Compu Sci 41(10):12–18
Oord AVD, Dieleman S, Zen H et al (2016) WaveNet: a generative model for raw audio[J]
Pandey SK, Shekhawat HS, Prasanna S (2019) Emotion Recognition from Raw Speech using Wavenet[C]// IEEE TENCON 2019. IEEE
J. Parry, D. Palaz, G. Clarke, et al. Analysis of deep learning architectures for cross-corpus speech emotion recognition, in Proc. of Interspeech, 2019.
Rajasekhar B, Kamaraju M, Sumalatha V (2019) Glowworm swarm based fuzzy classifier with dual features for speech emotion recognition [J]. Evol Intel 1
Ramanarayanan V , Pugh R , Yao Q , et al. Automatic turn-level language identification for code-switched Spanish–English dialog[M]. 2019.
Ran, Jincheng, Qiu et al (2019) Gender Identification using MFCC for Telephone Applications – A Comparative Study[J]. Composites Part B Eng
Sarma M, Ghahremani P, Povey D Emotion Identification from raw speech signals using DNNs. https://doi.org/10.21437/Interspeech.2018-1353
Schuller B , Steidl S , Batliner A , et al. The INTERSPEECH 2009 Emotion Challenge -- Results and Lessons Learnt[J]. interspeech, 2009.
Surekha Reddy Bandela, T. Kumar K (2017) Stressed speech emotion recognition using feature fusion of teager energy operator and MFCC[C]// 2017 8th International Conference on Computing, Communication and Networking Technologies (ICCCNT). IEEE Comput Soc,
Tzirakis P, Zhang J, and Schuller BW, “End-to-end speech emotion recognition using a deep convolutional recurrent network,” in ICASSP, 2018.
Wang Z-Q, Tashev I (2017) Learning utterance-level representations for speech emotion and age/gender recognition using deep neural networks[C]// ICASSPIEEE
Wang W, Yang L-P, Wei L (2013) Extraction and analysis of speech emotion characteristics [J]. Res Explor Lab 32(7):91–94
Xi M, Zhiyong W, Jia J (2018) Emotion recognition from variable-length speech segments using deep learning on spectrograms. Interspeech:3683–3687
Yenigalla P, Kumar A, Tripathi S et al (2018) Speech emotion recognition using spectrogram and phoneme embedding[C]// Interspeech 2018
Zhao J, Mao X, Chen L (2019) Speech emotion recognition using deep 1D & 2D CNN LSTM networks[J]. Biomed Signal Process Control 47(JAN):312–323
Zhao Z, Zheng Y, Zhang Z, Wang H, Zhao Y, and Li C, “Exploring spatio-temporal representations by integrating attention-based bidirectional-LSTM-RNNs and FCNs for speech emotion recognition,” in Proc. INTERSPEECH, Hyderabad, India, 2018, pp. 272–276.
Funding
This work was supported in part by the intercollegiate cooperation projects of Liaoning provincial Department of Education, grant number 86896244; the National Natural Science Foundation of China, grant number (61,370,070, 61,976,032, r 61,976,124). Dalian science and technology project, grant number 2019RQ120; the National Natural Science Foundation of China, grant number 61370070
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no competing interest
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zheng, C., Wang, C. & Jia, N. A two-channel speech emotion recognition model based on raw stacked waveform. Multimed Tools Appl 81, 11537–11562 (2022). https://doi.org/10.1007/s11042-022-12378-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-022-12378-1