
Abstract
Single channel speech separation (SS) is highly significant in many real-world speech processing applications such as hearing aids, automatic speech recognition, control humanoid robots, and cocktail-party issues. The performance of the SS is crucial for these applications, but better accuracy has yet to be developed. Some researchers have tried to separate speech using only the magnitude part, and some are tried to solve complex domains. We propose a dual transform SS method that serially uses the dual-tree complex wavelet transform (DTCWT) and short-term Fourier transform (STFT), and jointly learns the magnitude, real and imaginary parts of the signal applying a generative joint dictionary learning (GJDL). At first, the time-domain speech signal is decomposed by DTCWT, which produces a set of subband signals. Then STFT is connected to each subband signal, which converts each subband signal to the time-frequency domain and builds a complex spectrogram that prepares three parts like real, imaginary and magnitude for each subband signal. Next, we utilize the GJDL approach for making the joint dictionaries, and then the batch least angle regression with a coherence criterion (LARC) algorithm is used for sparse coding. Afterward, computes the initially estimated signals in two different ways, one by considering only the magnitude part and another by considering real and imaginary components. Finally, we apply the Gini index (GI) to the initially estimated signals to achieve better accuracy. The proposed algorithm demonstrates the best performance in all considered evaluation metrics compared to the mentioned algorithms.








Similar content being viewed by others
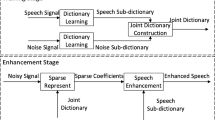

Data availability
The datasets created or analyzed during the present study are not openly available because they are the subject of continuing research but are available from the first author on an appropriate request basis.
References
Allen JB (1977) Short term spectral analysis, synthesis, and modification by discrete fourier transform. IEEE Trans Acoust Speech Signal Process ASSP-25:235–238
Bao G, Xu Y, Ye Z (2014) Learning a discriminative dictionary for single-channel speech separation. IEEE/ACM Trans Audio Speech Lang Process 22(7):1130–1138
Cooke M, Barker J, Cunningham S, Shao X (2006) An audio-visual corpus for speech perception and automatic speech recognition. J Acoust Soc Am 120(5):2421–2424
Demir C, Saraclar M, Cemgil A (2013) Single-channel speech-music separation for robust ASR with mixture models. IEEE Trans Audio Speech Lang Process 21(4):725–736
Fu J, Zhang L, Ye Z (2018) Supervised monaural speech enhancement using two level complementary joint sparse representations. Appl Acoust 132:1–7
Garofolo J et al (1993) TIMIT Acoustic-Phonetic Continuous Speech Corpus. LDC93S1, Web download, Philadelphia: Linguistic Data Consortium. https://doi.org/10.35111/17gk-bn40
Grais EM, Erdogan H (2013) Discriminative nonnegative dictionary learning using cross-coherence penalties for single channel source separation. In: Proceedings of the International Conference on Spoken Language Processing (INTERSPEECH), Lyon, France, pp. 808–812
Hossain MI, Islam MS, Khatun MT et al (2021) Dual-transform source separation using sparse nonnegative matrix factorization. Circ Syst Signal Process 40:1868–1891. https://doi.org/10.1007/s00034-020-01564-x
Huang PS, Kim M, Johnson MH, Smaragdis P (2015) Joint optimization of masks and deep recurrent neural networks for monaural source separation. IEEE/ACM Trans Audio Speech Lang Process 23(12):2136–2147
Hurley N, Rickard S (2009) Comparing measures of sparsity. IEEE Trans Inf Theory 55(10):4723–4741
Islam MS, Al Mahmud TH, Khan WU, Ye Z (2019) Supervised single channel speech enhancement based on stationary wavelet transforms and nonnegative matrix factorization with concatenated framing process and subband smooth ratio mask. J Sign Process Syst 92:445–458. https://doi.org/10.1007/s11265-019-01480-7
Islam MS, Al Mahmud TH, Khan WU, Ye Z (2019) Supervised Single Channel speech enhancement based on dual-tree complex wavelet transforms and nonnegative matrix factorization using the joint learning process and subband smooth ratio mask. Electronics 8(3):353
Islam MS, Zhu YY, Hossain MI, Ullah R, Ye Z (2020) Supervised single channel dual domains speech enhancement using sparse non-negative matrix factorization. Digital Signal Process 100:102697
Islam MS, Naqvi N, Abbasi AT, Hossain MI, Ullah R, Khan R, Islam MS, Ye Z (2021) Robust dual domain twofold encrypted image-in-audio watermarking based on SVD. Circ Syst Signal Process 40:4651–4685
Jang GJ, Lee TW (2003) A maximum likelihood approach to single channel source separation. J Mach Learn Res 4:1365–1392
Jia H, Wang W, Wang Y, Pei J (2019) Speech enhancement based on discriminative joint sparse dictionary alternate optimization. J Xidian Univ 46(3):74–81
Jiang D, He Z, Lin Y, Chen Y, Xu L (2021) An improved unsupervised single-channel speech separation algorithm for processing speech sensor signals. Wirel Commun Mob Comput 2021. https://doi.org/10.1155/2021/6655125
Kates JM, Arehart KH (2010) The hearing-aid speech quality index (HASQI). J Audio Eng Soc 58(5):363–381
Kates JM, Arehart KH (2014) The hearing-aid speech perception index (HASPI). Speech Comm 65:75–93
Ke S, Hu R, Wang X, Wu T, Li G, Wang Z (2020) Single Channel multi-speaker speech separation based on quantized ratio mask and residual network. Multimed Tools Appl 79:32225–32241
Kingsbury NG (1998) The dual-tree complex wavelet transforms: a new efficient tool for image restoration and enhancement. In: Proceedings of the 9th European Signal Process Conference, EUSIPCO, Rhodes, Greece. pp. 319–322
Lee DD, Seung HS (1999) Learning the pans of objects with nonnegative matrix factorization. Nature 401:788–791
Lian Q, Shi G, Chen S (2015) Research progress of dictionary learning model, algorithm and its application. J Autom 41(2):240–260
Lorenz MO (1905) Methods of measuring concentrations of wealth. J Am Stat Assoc 9:209
Luo Y, Bao G, Xu Y, Ye Z (2015) Supervised monaural speech enhancement using complementary joint sparse representations. IEEE Signal Process Lett 23:237–241
Mowlaee P, Saeidi R, Christensen MG, Tan ZH, Kinnunen T, Franti P, Jensen SH (2012) A joint approach for single-channel speaker identification and speech separation. IEEE Trans Audio Speech Lang Process 20(9):2586–2601
Muhammed B, Lekshmi MS (2017) Single channel speech separation in transform domain combined with DWT. National Conference on Technological Trends (NCTT), Manuscript Id: NCTTP006, pp. 15–18
Paatero P, Tapper U (1994) Positive matrix factorization: a nonnegative factor model with optimal utilization of error estimates of data values. Environmetrics 5(2):111–126
Rivet B, Wang W, Naqvi SM, Chambers JA (2014) Audiovisual speech source separation: an overview of key methodologies. IEEE Signal Process Mag 31(3):125–134
Rix A, Beerends J, Hollier M, Hekstra A (2010) Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. IEEE International Conference on Acoustics, Speech, Signal Processing, pp. 749–752
Roweis ST (2001) One microphone source separation. Adv Neural Inf Process Syst 13:793–799
Salman MS, Naqvi SM, Rehman A, Wang W, Chambers JA (2013) Video-aided model-based source separation in real reverberant rooms. IEEE Trans Audio Speech Lang Process 21(9):1900–1912
Sigg CD, Dikk T, Buhmann JM (2012) Speech enhancement using generative dictionary learning. IEEE Trans Audio Speech Lang Process 20(6):1698–1712
Sun Y, Rafique W, Chambers JA, Naqvi SM (2017) Undetermined source separation using time-frequency masks and an adaptive combined Gaussian-student's probabilistic model. In Proc IEEE Int Conf Acoust Speech Signal Process pp. 4187–4191
Sun L, Zhao C, Su M, Wang F (2018) Single-channel blind source separation based on joint dictionary with common sub-dictionary. Int J Speech Technol 21(1):19–27
Sun L, Xie K, Gu T, Chen J, Yang Z (2019) Joint dictionary learning using a new optimization method for single-channel blind source separation. Speech Comm 106:85–94
Sun Y, Xian Y, Wang W, Naqvi SM (2019) Monaural source separation in complex domain with long short-term memory neural network. IEEE J Sel Top Signal Process 13(2):359–369
Sun L, Zhu G, Li P (2020) Joint constraint algorithm based on deep neural network with dual outputs for single-channel speech separation. SIViP 14:1387–1395. https://doi.org/10.1007/s11760-020-01676-6
Sun L, Bu Y, Li P, Wu Z (2021) Single-channel speech enhancement based on joint constrained dictionary learning, Sun et al. EURASIP J Audio Speech Music Process. https://doi.org/10.1186/s13636-021-00218-3
Taal CH, Hendriks RC, Heusdens R, Jensen J (2011) An algorithm for intelligibility prediction of time-frequency weighted noisy speech. IEEE Trans Audio Speech Lang Process 19(7):2125–2136
Ullah R, Islam MS, Hossain MI, Wahab FE, Ye Z (2020) Single channel speech dereverberation and separation using RPCA and SNMF. Appl Acoust 167:107406. https://doi.org/10.1016/j.apacoust.2020.107406
Varshney YV, Abbasi ZA, Abidi MR, Farooq O (2017) Frequency selection based separation of speech signals with reduced computational time using sparse NMF. Arch Acoust 42(2):287–295
Vincent E, Gribonval R, Fevotte C (2006) Performance measurement in blind audio source separation. IEEE Trans Audio Speech Lang Process 14:1462–1469
Wang Y, Li Y, Ho KC, Zare A, Skubic M (2014) Sparsity promoted non-negative matrix factorization for source separation and detection. Proceedings of the 19th International Conference on Digital Signal Processing. IEEE, pp. 20–23
Wanng Z, Sha F (2014) Discriminative nonnegative matrix factorization for Single-Channel speech separation. IEEE International Conference on Acoustic, Speech and Signal Processing
Williamson DS, Wang Y, Wang D (2016) Complex ratio masking for monaural speech separation. IEEE/ACM Trans Audio Speech Lang Process 24(3):483–492
Wu B, Li K, Yang M, Lee C-H (2017) A reverberation time aware approach to speech dereverberation based on deep neural networks. IEEE/ACM Trans Audio Speech Lang Process 25(1):102–111
Xu Y, Bao G, Xu X, Ye Z (2015) Single-channel speech separation using sequential discriminative dictionary learning. Signal Process 106:134–140
Yang M, Zhang L, Yang J, Zhang D (2010) Metaface learning for sparse representation based face recognition. IEEE International Conference on Image Processing, pp. 1601–1604
Zohrevandi M, Setayeshi S, Rabiee A et al (2021) Blind separation of underdetermined convolutive speech mixtures by time–frequency masking with the reduction of musical noise of separated signals. Multimed Tools Appl 80:12601–12618. https://doi.org/10.1007/s11042-020-10398-3
Acknowledgments
This research was supported by the National Natural Science Foundation of China (no. 61671418).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflicts of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Hossain, M.I., Al Mahmud, T.H., Islam, M.S. et al. Dual transform based joint learning single channel speech separation using generative joint dictionary learning. Multimed Tools Appl 81, 29321–29346 (2022). https://doi.org/10.1007/s11042-022-12816-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-022-12816-0