
Abstract
Due to the significance of human behavioural intelligence in computing devices, this paper presents the Panjab University Multilingual Audio and Video Facial Expression (PUMAVE) dataset for multimodal emotion recognition in the Indian context. It discusses the characteristics and distinguishing features of the PUMAVE dataset compared with existing datasets. It described the detail procedure followed in the construction of PUMAVE dataset. The validation and reliability analysis are performed on the recorded speech and facial expressions of subjects in six emotions. The effectiveness of the recorded emotion clips is analysed against the responses of annotators. During and after responses, inter-rater responses, and intra-rater responses are analysed to measure the quality of subjective assessment, homogeneity, and consistency in the annotator responses. The PUMAVE dataset is the first multilingual tone-sensitive audio-video facial expression dataset which provides emotional labelled clips of subjects who speak the native language (Punjabi and Hindi) and foreign language (English).







Similar content being viewed by others



Data Availability
All recordings of the proposed PUMAVE are freely provided for academic research purposes under the license agreement with Design Innovation Centre, University Institute of Engineering and Technology, Panjab University, Chandigarh, INDIA.
Notes
https://github.com/dicuietpu/PUEAT_Tool
Fig. 6 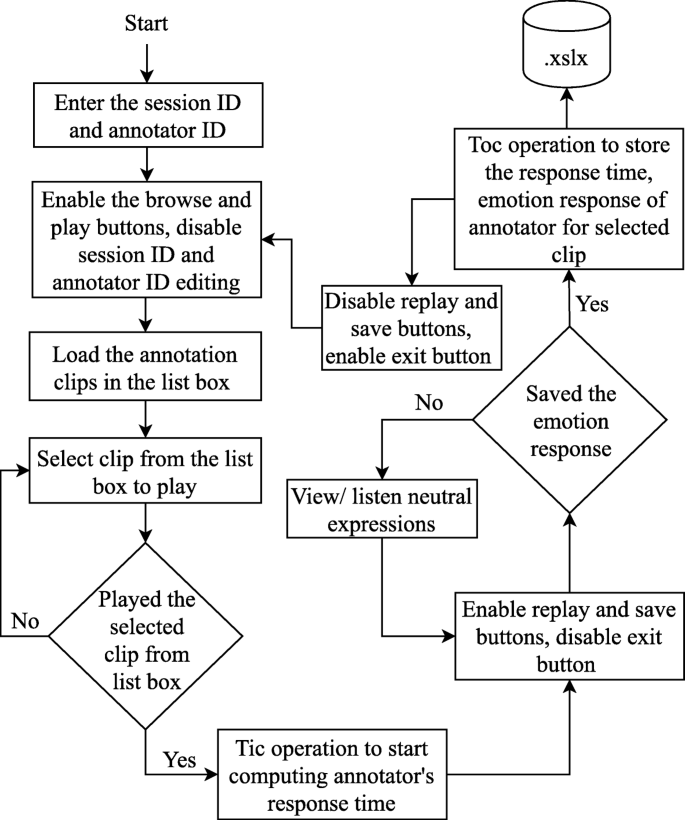
Flowchart of the working of developed PUEAT
Fig. 7 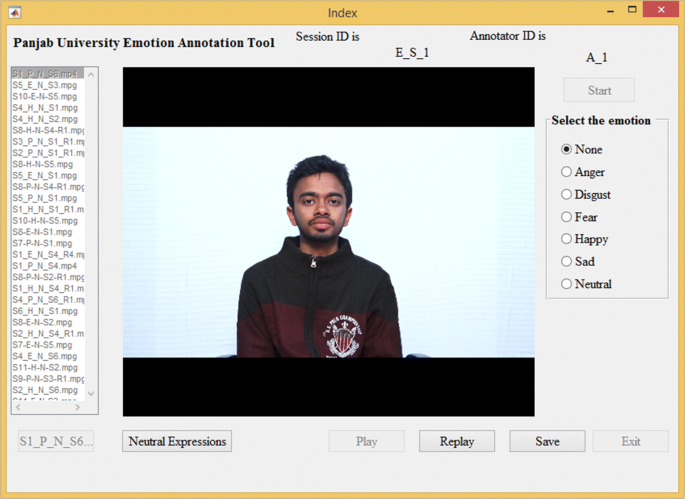
Graphical user interface of developed PUEAT


References
Bänziger T, Pirker H, Scherer K (2006) Gemep-geneva multimodal emotion portrayals: a corpus for the study of multimodal emotional expressions. In: Proceedings of LREC, vol 6, pp 15–019
Bastanfard A, Aghaahmadi M, Fazel M, Moghadam M et al (2009) Persian viseme classification for developing visual speech training application. In: Pacific-rim conference on multimedia. Springer, pp 1080–1085
Battocchi A, Pianesi F, Goren-Bar D (2005) Dafex: database of facial expressions. In: International conference on intelligent technologies for interactive entertainment. Springer, pp 303–306
Berry KJ, Mielke Jr PW (1988) A generalization of cohen’s kappa agreement measure to interval measurement and multiple raters. Educ Psychol Meas 48(4):921–933
Busso C, Bulut M, Lee C-C, Kazemzadeh A, Mower E, Kim S, Chang JN, Lee S, Narayanan SS (2008) Iemocap: interactive emotional dyadic motion capture database. Lang Resour Eval 42(4):335
Busso C, Parthasarathy S, Burmania A, AbdelWahab M, Sadoughi N, Provost EM (2016) Msp-improv: an acted corpus of dyadic interactions to study emotion perception. IEEE Trans Affect Comput 8(1):67–80
Cao H, Cooper DG, Keutmann MK, Gur RC, Nenkova A, Verma R (2014) Crema-d: crowd-sourced emotional multimodal actors dataset. IEEE Trans Affect Comput 5(4):377–390
Caridakis G, Wagner J, Raouzaiou A, Curto Z, Andre E, Karpouzis K (2010) A multimodal corpus for gesture expressivity analysis. Multimod Corpora Adv Capturing Coding Anal Multimodality, vol 80
Dhall A, Goecke R, Lucey S, Gedeon T et al (2012) Collecting large, richly annotated facial-expression databases from movies. IEEE Multimed 19(3):34–41
Douglas-Cowie E, Cowie R, Cox C, Amir N, Heylen D (2008) The sensitive artificial listener: an induction technique for generating emotionally coloured conversation. In: LREC workshop on corpora for research on emotion and affect. ELRA, pp 1–4
Du S, Tao Y, Martinez AM (2014) Compound facial expressions of emotion. Proc National Acad Sci 111(15):1454–1462
Erdem CE, Turan C, Aydin Z (2015) Baum-2: a multilingual audio-visual affective face database. Multimed Tools Appl 74(18):7429–7459
Fleiss JL, Levin B, Paik MC et al (1981) The measurement of interrater agreement. Stat Methods Rates Proportions 2(212-236):22–23
Haq S, Jackson PJ, Edge J (2008) Audio-visual feature selection and reduction for emotion classification. In: Proceeding intelligence conference on auditory-visual speech processing (AVSP’08), Tangalooma, Australia
Hussain MS, Monkaresi H, Calvo RA (2012) Combining classifiers in multimodal affect detection. In: Proceedings of the tenth australasian data mining conference-vol 134, pp 103–108. Australian Computer Society, Inc
Kim J, André E, Rehm M, Vogt T, Wagner J (2005) Integrating information from speech and physiological signals to achieve emotional sensitivity. In: Ninth european conference on speech communication and technology
Koelstra S, Muhl C, Soleymani M, Lee J-S, Yazdani A, Ebrahimi T, Pun T, Nijholt A, Patras I (2012) Deap: a database for emotion analysis; using physiological signals. IEEE Trans Affect Comput 3(1):18–31
Kossaifi J, Walecki R, Panagakis Y, Shen J, Schmitt M, Ringeval F, Han J, Pandit V, Schuller B, Star K et al (2019) Sewa db: a rich database for audio-visual emotion and sentiment research in the wild. arXiv:1901.02839
Li Y, Tao J, Chao L, Bao W, Liu Y (2017) Cheavd: a chinese natural emotional audio–visual database. J. Ambient Intell Human Comput 8 (6):913–924
Lin J-C, Wu C-H, Wei W-L (2012) Error weighted semi-coupled hidden markov model for audio-visual emotion recognition. IEEE Trans Multimed 14(1):142–156
Lin J-C, Wu C-H, Wei W-L (2012) Error weighted semi-coupled hidden markov model for audio-visual emotion recognition. IEEE Trans Multimed 14(1):142–156
Livingstone SR, Russo FA (2018) The ryerson audio-visual database of emotional speech and song (ravdess): a dynamic, multimodal set of facial and vocal expressions in north american english. PloS One 13(5):0196391
Martin O, Kotsia I, Macq B, Pitas I (2006) The enterface’05 audio-visual emotion database. In: 22nd International conference on data engineering workshops (ICDEW’06). IEEE, pp 8–8
McKeown G, Valstar MF, Cowie R, Pantic M (2010) The semaine corpus of emotionally coloured character interactions. In: Multimedia and Expo (ICME), 2010 IEEE international conference On. IEEE, pp 1079–1084
McKeown G, Valstar M, Cowie R, Pantic M, Schroder M (2011) The semaine database: annotated multimodal records of emotionally colored conversations between a person and a limited agent. IEEE Trans Affect Comput 3(1):5–17
Morency L-P, Mihalcea R, Doshi P (2011) Towards multimodal sentiment analysis: harvesting opinions from the web. In: Proceedings of the 13th international conference on multimodal interfaces. ACM, pp 169–176
Nazari K, Ebadi MJ, Berahmand K (2022) Diagnosis of alternaria disease and leafminer pest on tomato leaves using image processing techniques. J Sci Food Agri 102(15):6907–6920
ORGI: Census of India (2011) Comparative speaker's strength of scheduled languages-1951, 1961, 1971, 1981, 1991, 2001 and 2011. https://censusindia.gov.in/nada/index.php/catalog/42458/download/46089/C-16_25062018.pdf. Accessed 12 November 2022
Papapicco C (2020) Google mini: italian example of artificial prosociality. Online J Commun Media Technol 10(1):2020
Papapicco C, D’Errico F, Mininni G (2021) Affective detection of ‘brain drain’through video-narrative interview. World Futures 77(4):266–284
Ringeval F, Sonderegger A, Sauer J, Lalanne D (2013) Introducing the recola multimodal corpus of remote collaborative and affective interactions. In: Automatic face and gesture recognition (FG), 2013 10th IEEE international conference and workshops on. IEEE, pp 1–8
Rosas VP, Mihalcea R, Morency L-P (2013) Multimodal sentiment analysis of spanish online videos. IEEE Intell Syst 28(3):38–45
Rösner DF, Frommer J, Friesen R, Haase M, Lange J, Otto M (2012) Last minute: a multimodal corpus of speech-based user-companion interactions. In: LREC, pp 2559–2566
Rostami M, Forouzandeh S, Berahmand K, Soltani M (2020) Integration of multi-objective pso based feature selection and node centrality for medical datasets. Genomics 112(6):4370–4384
Savargiv M, Bastanfard A (2013) Text material design for fuzzy emotional speech corpus based on persian semantic and structure. In: 2013 International conference on fuzzy theory and its applications (iFUZZY). IEEE, pp 380–384
Schuller B, Arsic D, Rigoll G, Wimmer M, Radig B (2007) Audiovisual behavior modeling by combined feature spaces. In: 2007 IEEE international conference on acoustics, speech and signal processing-ICASSP’07. IEEE, vol 2, p 733
Wagner HL (1993) On measuring performance in category judgment studies of nonverbal behavior. J Nonverbal Behavior 17(1):3–28
Wang Y, Guan L (2008) Recognizing human emotional state from audiovisual signals. IEEE Trans Multimed 10(5):936–946
Weizenbaum J (1966) Eliza—a computer program for the study of natural language communication between man and machine. Commun ACM 9(1):36–45
Wöllmer M, Weninger F, Knaup T, Schuller B, Sun C, Sagae K, Morency L-P (2013) Youtube movie reviews: sentiment analysis in an audio-visual context. IEEE Intell Syst 28(3):46–53
Zadeh AB, Liang PP, Poria S, Cambria E, Morency L-P (2018) Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph. In: Proceedings of the 56th annual meeting of the association for computational linguistics (vol 1: long papers), pp 2236–2246
Zhalehpour S, Onder O, Akhtar Z, Erdem CE (2017) Baum-1: a spontaneous audio-visual face database of affective and mental states. IEEE Trans Affect Comput 8(3):300–313
Acknowledgements
I would especially like to thank Rajwinder Singh, Harshita Puri, Vijay Paul Singh and other members of Design Innovation Centre, University Institute of Engineering and Technology, Panjab University, Chandigarh, for their support in the data collection phase of this research work.
Funding
This work was supported by University Grant Commission (UGC), Ministry of Human Resource Development (MHRD) of India under Basic Scientific Research (BSR) fellowship for meritorious fellows vide UGC letter no. F.25-1/2013-14(BSR)/7-379/2012(BSR) Dated 30.5. 2014.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interests
All authors certify that they have no known conflicts of interest associated with this manuscript.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Singh, L., Aggarwal, N. & Singh, S. PUMAVE-D: panjab university multilingual audio and video facial expression dataset. Multimed Tools Appl 82, 10117–10144 (2023). https://doi.org/10.1007/s11042-022-14102-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-022-14102-5