
Abstract
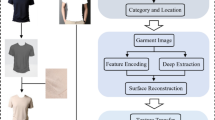
3D garment reconstruction has a wide range of applications in apparel design, digital human body, and virtual try-on. Reconstructing 3D shapes from single-view images is a completely undefined and challenging problem. Recent single-view methods require only single-view images of static or dynamic objects and mine the potential multi-view information in single-view images by statistical, geometric, and physical prior knowledge, which is tedious to obtain. In this paper, we use an implicit function of pixel alignment represented by a neural network to correlate 2D image pixels with the corresponding 3D clothing information for end-to-end training without any relevant prior model. The qualitative and quantitative analysis of the experimental results showed that our results reduced the relative error by an average of 2.6% and the chamfer distance by 2.37% compared to the previous method. Experiments show that our model can reasonably reconstruct the 3D model of garments from their collections of single-view images. Our method can not only capture the overall geometry of the garment but also extract the tiny but important wrinkle details of the fabric. Even with low-resolution input images, our model still achieves available results. In addition, experiments show that the reconstructed 3D models of garments can be used for texture migration and virtual fitting.











Similar content being viewed by others


References
Bălan AO, Black MJ (2008) “The naked truth: Estimating body shape under clothing,” in European Conference on Computer Vision, pp. 15–29
Baran I, Popović J (2007) Automatic rigging and animation of 3d characters. ACM Trans Graph 26(3):72-es
Bhatnagar BL, Tiwari G, Theobalt C, Pons-Moll G (2019) “Multi-garment net: Learning to dress 3d people from images,” in Proceedings of the IEEE/CVF international conference on computer vision, pp. 5420–5430
Bhatti UA, Yu Z, Li J, Nawaz SA, Mehmood A, Zhang K, Yuan L (2020) Hybrid watermarking algorithm using Clifford algebra with Arnold scrambling and chaotic encryption. IEEE Access 8:76386–76398
Bhatti UA, Yu Z, Yuan L, Nawaz SA, Aamir M, Bhatti MA (2022) “A Robust Remote Sensing Image Watermarking Algorithm Based on Region-Specific SURF,” in Proceedings of International Conference on Information Technology and Applications: ICITA 2021, pp. 75–85
Bogo F, Kanazawa A, Lassner C, Gehler P, Romero J, Black MJ (2016) “Keep it SMPL: Automatic estimation of 3D human pose and shape from a single image,” in European conference on computer vision, pp. 561–578
Bradley D, Popa T, Sheffer A, Heidrich W, Boubekeur T (2008) “Markerless garment capture,” in ACM SIGGRAPH 2008 papers, pp. 1–9
Chang AX et al (2015) “Shapenet: An information-rich 3d model repository,” arXiv Prepr. arXiv1512.03012
Chen X, Zhou B, Lu F-X, Wang L, Bi L, Tan P (2015) Garment modeling with a depth camera. ACM Trans Graph 34(6):201–203
Choy CB, Xu D, Gwak J, Chen K, Savarese S (2016) “3d-r2n2: A unified approach for single and multi-view 3d object reconstruction,” in European conference on computer vision, pp. 628–644
Daněřek R, Dibra E, Öztireli C, Ziegler R, Gross M (2017) Deepgarment: 3d garment shape estimation from a single image. Comput Graph Forum 36(2):269–280
De Aguiar E, Stoll C, Theobalt C, Ahmed N, Seidel H-P, Thrun S (2008) “Performance capture from sparse multi-view video,” in ACM SIGGRAPH 2008 papers, pp. 1–10
De Aguiar E, Sigal L, Treuille A, Hodgins JK (2010) Stable spaces for real-time clothing. ACM Trans Graph 29(4):1–9
Dou M, Khamis S, Degtyarev Y, Davidson P, Fanello SR, Kowdle A, Escolano SO, Rhemann C, Kim D, Taylor J, Kohli P, Tankovich V, Izadi S (2016) Fusion4d: real-time performance capture of challenging scenes. ACM Trans Graph 35(4):1–13
Fan H, Su H, Guibas LJ (2017) “A point set generation network for 3d object reconstruction from a single image,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 605–613
Guan P, Freifeld O, Black MJ (2010) “A 2D human body model dressed in eigen clothing,” in European conference on computer vision, pp. 285–298
Habermann M, Xu W, Zollhoefer M, Pons-Moll G, Theobalt C (2019) Livecap: Real-time human performance capture from monocular video. ACM Trans Graph 38(2):1–17
Huang S, Qi S, Zhu Y, Xiao Y, Xu Y, Zhu S-C (2018) “Holistic 3d scene parsing and reconstruction from a single rgb image,” in Proceedings of the European conference on computer vision (ECCV), pp. 187–203
Huynh L et al (2018) “Mesoscopic facial geometry inference using deep neural networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8407–8416
Izadi S et al (2011) “Kinectfusion: real-time 3d reconstruction and interaction using a moving depth camera,” in Proceedings of the 24th annual ACM symposium on User interface software and technology, pp. 559–568
Jackson AS, Manafas C, Tzimiropoulos G (2018) 3d human body reconstruction from a single image via volumetric regression,” in Proceedings of the European Conference on Computer Vision (ECCV) Workshops, p. 0
Jiang B, Zhang J, Cai J, Zheng J (2020) Disentangled human body embedding based on deep hierarchical neural network. IEEE Trans Vis Comput Graph 26(8):2560–2575
Kanazawa A, Black MJ, Jacobs DW, Malik J (2018) “End-to-end recovery of human shape and pose,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 7122–7131
Kocabas M, Athanasiou N, Black MJ (2020) “Vibe: Video inference for human body pose and shape estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5253–5263
Kolotouros N, Pavlakos G, Black MJ, Daniilidis K (2019) “Learning to reconstruct 3D human pose and shape via model-fitting in the loop,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2252–2261
Lahner Z, Cremers D, Tung T (2018) “Deepwrinkles: Accurate and realistic clothing modeling,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 667–684
Loper M, Mahmood N, Romero J, Pons-Moll G, Black MJ (2015) SMPL: A skinned multi-person linear model. ACM Trans Graph 34(6):1–16
Natsume R et al (2019) “Siclope: Silhouette-based clothed people,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4480–4490
Niu C, Li J, Xu K (2018) “Im2struct: Recovering 3d shape structure from a single rgb image,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4521–4529
Pavlakos G et al (2019) “Expressive body capture: 3d hands, face, and body from a single image,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10975–10985
Penna MA (1989) A shape from shading analysis for a single perspective image of a polyhedron. IEEE Trans Pattern Anal Mach Intell 11(6):545–554
Pollefeys M, Koch R, Van Gool L (1999) Self-calibration and metric reconstruction inspite of varying and unknown intrinsic camera parameters. Int J Comput Vis 32(1):7–25
Saito S, Huang Z, Natsume R, Morishima S, Kanazawa A, Li H (2019) “Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2304–2314
Scholz V, Stich T, Magnor M, Keckeisen M, Wacker M (2005) “Garment motion capture using color-coded patterns,” in ACM SIGGRAPH 2005 Sketches, pp. 38-es
Sclaroff S, Pentland A (1991) Generalized implicit functions for computer graphics. ACM Siggraph Comput Graph 25(4):247–250
Su H, Maji S, Kalogerakis E, Learned-Miller E (2015) “Multi-view convolutional neural networks for 3d shape recognition,” in Proceedings of the IEEE international conference on computer vision, pp. 945–953
Varol G et al (2018) “Bodynet: Volumetric inference of 3d human body shapes,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 20–36
Vlasic D et al (2009) “Dynamic shape capture using multi-view photometric stereo,” in ACM SIGGRAPH Asia 2009 papers, pp. 1–11
Wang CCL, Wang Y, Yuen MMF (2003) Feature based 3D garment design through 2D sketches. Comput Des 35(7):659–672
Wang F, Kang L, Li Y (2015) “Sketch-based 3d shape retrieval using convolutional neural networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1875–1883
Wang N, Zhang Y, Li Z, Fu Y, Liu W, Jiang Y-G (2018) “Pixel2mesh: Generating 3d mesh models from single rgb images,” in Proceedings of the European conference on computer vision (ECCV), pp. 52–67
White R, Crane K, Forsyth DA (2007) Capturing and animating occluded cloth. ACM Trans Graph 26(3):34-es
Wu Z et al (2015) “3d shapenets: A deep representation for volumetric shapes,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1912–1920
Yan X, Yang J, Yumer E, Guo Y, Lee H (2016) Perspective transformer nets: learning single-view 3d object reconstruction without 3d supervision. In: Lee D, Sugiyama M, Luxburg U, Guyon I, Garnett R (eds.) Advances in Neural Information Processing Systems, vol 29, pp 1696–1704
Yang S et al (2016) “Detailed garment recovery from a single-view image,” arXiv Prepr. arXiv1608.01250
Yu Q, Yang C, Wei H (2022) Part-wise AtlasNet for 3D point cloud reconstruction from a single image. Knowl Based Syst 242:108395
Zhao F, Wang W, Liao S, Shao L (2021) “Learning anchored unsigned distance functions with gradient direction alignment for single-view garment reconstruction,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 12674–12683
Zhou B, Chen X, Fu Q, Guo K, Tan P (2013) Garment modeling from a single image. Comput Graph Forum 32(7):85–91
Data sharing
Data sharing is not applicable to this article, as no new data were created or analyzed in this study.
Funding
This work was supported by National Natural Science Foundation of China (No. 61976105) and Postgraduate Research & Practice Innovation Program of Jiangsu Province (No. KYCX22_2342).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
Wentao He, Ning Zhang, Bingpeng Song and Ruru Pan* declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
He, W., Zhang, N., Song, B. et al. Garment reconstruction from a single-view image based on pixel-aligned implicit function. Multimed Tools Appl 82, 30247–30265 (2023). https://doi.org/10.1007/s11042-023-14924-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-14924-x