
Abstract
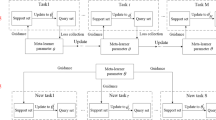
The goal of speech enhancement is to reduce and suppress the noise in noisy speech and improve the quality and intelligibility of damaged speech. With the development of deep learning, the performance of SE has been significantly improved. However, deep learning relies on massive training data, and the lack of data is an important reason for the failure and difficulty of many algorithms. Aiming at this problem, this paper proposed a novel meta-reinforcement learning framework, focusing on the few-shot learning for speech enhancement. Specifically, first, a reinforcement learning based meta-learner is proposed which initializes the actions by a finite number of T-F masks, and the related action-value function is developed. Second, to optimize the model, this paper develops the reward calculation for reinforcement learning by using the user perception. Third, the model-agnostic Meta learning (MAML) algorithm is applied to fully utilize the limited data to improve the generalization of the meta-learner and towards better generalization of learning new tasks. The experiment results show that in terms of subjective and objective measurements, this work achieves at least improvement of 1.3%~12.5% for 1-shot case and 3.1% ~14.3% for 5-shot case in contrast to the state-of-the-arts DNN based SE methods in challenging conditions, where the environment noises are diverse, and the signals are non-stationary.










Similar content being viewed by others

Data availability statements
The datasets generated during and/or analysed during the current study are available in the TIMIT repository, https://catalog.ldc.upenn.edu/; DEMAND repository, https://asa.scitation.org/doi/abs/10.1121/1.4799597; NOISEX-92 repository, http://www.auditory.org/mhonarc/2006/msg00609.html
References
Afouras T, Chung JS, Zisserman A (2018) The conversation: Deep audiovisual speech enhancement. Proc Interspeech 2018:3244–3248
Anand P, Singh AK, Srivastava S, Lall B (2019) Few Shot Speaker Recognition using Deep Neural Networks. arXiv preprint arXiv: arXiv:1904.08775
Baker B, Gupta O, Naik N, Raskar R (2017) Designing neural network architectures using reinforcement learning, arXiv preprint arXiv:1611.02167
Chen Y, Zhang Y, Yang J et al (2018) Structure-adaptive Fuzzy Estimation for Random-Valued Impulse Noise Suppression. IEEE Trans Circ Syst Video Technol 28(2):414–427
Chu W-H, Wang Y-CF (2018) Learning Semantics-Guided Visual Attention for Few-Shot Image Classification. IEEE International Conference on Image Processing (ICIP)
Debasmit Das CS, Lee G (2020) A Two-Stage Approach to Few-Shot Learning for Image Recognition. IEEE/ACM Trans Imag Proc 29:3336–3350
Deng F, Jiang T, Wang XR, Zhang C, Li Y (2020) NAAGN: Noise-aware Attention-gated Network for Speech Enhancement. Proc. Interspeech, 2457-2461
Erdogan H, Hershey JR, Watanabe S, Le Roux J (2019) Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks. In Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on, pp. 708–712
Erdogan H, Hershey JR, Watanabe S, Le Roux J (2019) Learning to Match Transient Sound Events Using Attentional Similarity for Few-shot Sound Recognition. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 125–128
Fakoor R, Chaudhari P, Soatto S, Smola AJ (2019) Meta-Q-Learning. In: Proceedings of International Conference on Learning Representations, pp 332–338
Finn C, Abbeel P, Levine S (2017) Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pp. 1126–1135. JMLR. org
Fu SW, Liao CF, Tsao Y, Lin SD (2019) MetricGAN: Generative adversarial networks based black-box metric scores optimization for speech enhancement. arXiv preprint arXiv:1905.04874
ITU-T Rec. (2001) Perceptual Evaluation of Speech Quality (PESQ):An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs, P.862
Jane X, Zeb K, Dhruva T et al (2018) Learning to reinforcement learn, arXiv preprint arXiv:1611.05763
Kang B , Liu Z, Wang X, Yu F, Feng J (2019) Few-Shot Object Detection via Feature Reweighting. IEEE/CVF International Conference on Computer Vision (ICCV), pp. 69–74
Li A, Zheng C, Peng R, Fan C, Li X (2020) Dynamic Attention Based Generative Adversarial Network with Phase Post-Processing for Speech Enhancement. arXiv preprint arXiv:2006.07530
Lin S-C, Chen C-J, Lee T-J (2018) A Multi-Label Classification With Hybrid Label-Based Meta-Learning Method in Internet of Things. IEEE Access 8:2169–3536
Loizou PC (2013) Speech enhancement: theory and practice. CRC Press
Masuyama Y, Togami M, Komats T (2018) Consistency-aware multi-channel speech enhancement using deep neural networks. arXiv preprint: arXiv:2002.05831
Mnih V et al (2015) Human-level control through deep reinforcement learning. Nature 518(7540):529
Moss HB, Aggarwal V, Prateek N, González J, Barra-Chicote R (2020) BOFFIN TTS: Few-Shot Speaker Adaptation by Bayesian Optimization. arXiv preprint arXiv:2002.01953
NOISEX-92 database http://www.auditory.org/mhonarc/2006/msg00609.html, Accessed 1 Jan 2020
Pan C, Huang J, Gong J, Yuan X (2019) Few-Shot Transfer Learning for Text Classification With Lightweight Word Embedding Based Models. IEEE Access 7:53296–53304
Pascual S, Bonafonte A, Serra J (2018) SEGAN: Speech enhancement generative adversarial network. In Proc. Interspeech, pp. 77–82
Rangachari S, Loizou P (2006) A noise estimation algorithm for highly nonstationary environments. Speech Comm 48(2):220–231
Rethage D, Pons J, Serra X (2019) A wavenet for speech denoising. In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 423–426
Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer assisted intervention, pp. 234–241
Santoro A, Bartunov S, Botvinick M, Wierstra D, Lillicrap T (2016) Meta learning with memory-augmented neural networks. Int Conf Machine Learn:767–771
Silver D et al (2017) Mastering the game of go without human knowledge. Nature 550(7676):p354
Silver D et al (2017) Mastering the game of go without human knowledge. Nature 550(7676):p354
Snell J, Swersky K, Zemel R (2017) Prototypical networks for few-shot learning. Adv Neural Inform Proc Syst:512–515
Tadas B, Chaitanya A, and Louis (2019) Multimodal machine learning: A survey and taxonomy. arXiv preprint arXiv:1705.094062
Thiemann J, Ito N, Vincent E (2013) The diverse environments multi-channel acoustic noise database: A database of multichannel environmental noise recordings. J Acoustical Soc Ame 133(5):3591–3591
TIMIT speech corpus, https://catalog.ldc.upenn.edu/, Accessed 20 Sept 2020
Wang D (2017) Deep learning reinvents the hearing aid. IEEE Spectr 54(3):32–37
Williamson DS, Wang Y, Wang D (2019) Complex ratio masking for monaural speech separation. IEEE/ACM Trans Audio, Speech Language Proc (TASLP) 24(3):483–492
Winata GI, Cahyawijaya S, Liu Z, Lin Z, Madotto A, Xu P, Fung P (2020) Learning Fast Adaptation on Cross-Accented Speech Recognition. arXiv preprint arXiv: 2003.01901
Zhou W,Zhu Z (2020) A novel BNMF-DNN based speech enhancement method for speech quality evaluation under complex environments,Int J Machi Learning Cybern. https://doi.org/10.1007/s13042-020-01214-3
Zhou WL, He QH, Gang W (2015) Quasi-clean speech construction based speech quality evaluation under complex environments, Proc. IEEE Int. Conf. on System, Man and Cybernetics, Hong Kong, pp. 2761-2765
Zhou W, He Q, Wang Y et al (2017) Sparse representation-based quasi-clean speech construction for speech quality assessment under complex environments. IET Sig Proc 11(4):486–493
Zhou W, Zhu Z, Liang P (2019) Speech denoising using Bayesian NMF with online base update,Multimed Tools Appl, 78:15647–15664
Zhou WL Mingliang,Ji R, Liang P (2021) Learning to enhance: A meta-learning framework for few-shot speech enhancement,IEEE/ACM Transactions on Audio, Speech, and Language Processing
Zoph B, Le QV (2016) Neural architecture search with reinforcement learning, arXiv preprint arXiv:1611.01578
Acknowledgments
This work is supported by the Foshan University Research Foundation for Advanced Talents (GG07005), the Natural Science Foundation of Guangdong Province (2018A0303130082, 2019A1515111148), Guangdong Province Colleges and Universities Young Innovative Talent Project (2019KQNCX168).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
The authors declare that no competing financial interests or personal relationships that could have appeared to influence the work reported in this paper. No conflict of interest exits in the submission of this manuscript, and the manuscript is approved by all authors for publication. The work described was original research that has not been published previously, and not under consideration for publication elsewhere, in whole or in part.
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhou, W., Ji, R. & Lai, J. MetaRL-SE: a few-shot speech enhancement method based on meta-reinforcement learning. Multimed Tools Appl 82, 43903–43922 (2023). https://doi.org/10.1007/s11042-023-14945-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-14945-6