
Abstract
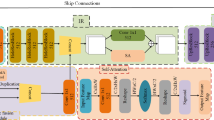
Hallucinating a photo-realistic high-resolution (HR) face image from an occluded low-resolution (LR) face image is beneficial for a series of face-related applications. However, previous efforts focused on either super-resolving HR face images from non-occluded LR counterparts or inpainting occluded HR faces. It is necessary to address all these challenges jointly for real-world face images in unconstrained environment. In this paper, we develop a novel Local-to-Global Face Hallucination Transformer (LGFH-Transformer), which simultaneously handles the occluded LR face image super-resolution (SR) and inpainting in a unified framework. Specifically, the LGFH-Transformer is built on self-attention modules which excel at modeling long-range information between image patch sequences. Meanwhile, we introduce a mask-guided convolution and gated mechanism into the building modules (i.e., multi-head attention and feed-forward network) of each Transformer block, which can bring in the complimentary strength of convolution operation to emphasize on the spatially local context. Moreover, equipped with the delicate designed local-to-global feature reasoning mechanism in the phase of encoder, we exploit facial geometry priors (i.e., facial parsing maps) as the semantic guidance during the hallucination process in the phase of decoder to reconstruct more realistic facial details. Extensive experiments demonstrate the effectiveness and advancement of LGFH-Transformer.












Similar content being viewed by others


Data Availability
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
References
Ballester C, Bertalmio M, Caselles V, Sapiro G, Verdera J (2001) Filling-in by joint interpolation of vector fields and gray levels. IEEE Trans Image Process 10(8):1200–1211. https://doi.org/10.1109/83.935036
Bertalmio M, Sapiro G, Caselles V, Ballester C (2000) Image inpainting. In: Proceedings of the 27th annual conference on computer graphics and interactive techniques, pp 417–424
Cai J, Han H, Shan S, Chen X (2019) Fcsr-gan: joint face completion and super-resolution via multi-task learning. IEEE Trans Biom Behav Ident Sci 2(2):109–121
Cao Q, Shen L, Xie W, Parkhi O M, Zisserman A (2018) Vggface2: a dataset for recognising faces across pose and age. In: 2018 13th IEEE international conference on automatic face & gesture recognition (FG 2018). IEEE, pp 67–74. https://doi.org/10.1109/fg.2018.00020
Chen C, Li X, Yang L, Lin X, Zhang L, Wong K-Y K (2021) Progressive semantic-aware style transformation for blind face restoration. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 11896–11905. https://doi.org/10.1109/cvpr46437.2021.01172
Chen H, Wang Y, Guo T, Xu C, Deng Y, Liu Z, Ma S, Xu C, Xu C, Gao W (2021) Pre-trained image processing transformer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 12299–12310. https://doi.org/10.1109/cvpr46437.2021.01212
Dai Q, Li J, Yi Q, Fang F, Zhang G (2021) Feedback network for mutually boosted stereo image super-resolution and disparity estimation. arXiv:2106.00985. https://doi.org/10.1145/3474085.3475356
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S et al (2020) An image is worth 16x16 words: transformers for image recognition at scale. In: International conference on learning representations
Efros A A, Freeman W T (2001) Image quilting for texture synthesis and transfer. In: Proceedings of the 28th annual conference on Computer graphics and interactive techniques, pp 341–346. https://doi.org/10.1145/383259.383296
Fu C, Wu X, Hu Y, Huang H, He R (2021) Dvg-face: dual variational generation for heterogeneous face recognition. IEEE Trans Pattern Anal Mach Intell. https://doi.org/10.1109/tpami.2021.3052549
Gatys L A, Ecker A S, Bethge M (2016) Image style transfer using convolutional neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2414–2423. https://doi.org/10.1109/cvpr.2016.265
Guo K, Hu M, Ren S, Li F, Zhang J, Guo H, Kui X (2022) Deep illumination-enhanced face super-resolution network for low-light images. ACM Trans Multimed Comput Commun Applic (TOMM) 18(3):1–19. https://doi.org/10.1145/3495258
Hendrycks D, Gimpel K (2016) Gaussian error linear units (gelus). arXiv:1606.08415
Hore A, Ziou D (2010) Image quality metrics: Psnr vs. ssim. In: 2010 20th International conference on pattern recognition. IEEE, pp 2366–2369. https://doi.org/10.1109/icpr.2010.579
Huang H, He R, Sun Z, Tan T (2017) Wavelet-srnet: a wavelet-based cnn for multi-scale face super resolution. In: Proceedings of the IEEE international conference on computer vision, pp 1689–1697. https://doi.org/10.1109/ICCV.2017.187
Jaderberg M, Simonyan K, Zisserman A, et al. (2015) Spatial transformer networks. Adv Neural Inf Process Syst 28:2017–2025
Kingma D P, Ba J (2014) Adam: a method for stochastic optimization. arXiv:1412.6980
Kwatra V, Essa I, Bobick A, Kwatra N (2005) Texture optimization for example-based synthesis. In: ACM SIGGRAPH 2005 Papers, pp 795–802. https://doi.org/10.1145/1186822.1073263
Li Y, Liu S, Yang J, Yang M-H (2017) Generative face completion. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3911–3919. https://doi.org/10.1109/cvpr.2017.624
Li H, Wang W, Yu C, Zhang S (2021) Swapinpaint: identity-specific face inpainting with identity swapping. IEEE Trans Circuits Syst Video Technol. https://doi.org/10.1109/tcsvt.2021.3130196
Liang J, Cao J, Sun G, Zhang K, Van Gool L, Timofte R (2021) Swinir: image restoration using swin transformer. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 1833–1844. https://doi.org/10.1109/iccvw54120.2021.00210
Lim B, Son S, Kim H, Nah S, Mu Lee K (2017) Enhanced deep residual networks for single image super-resolution. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pp 136–144. https://doi.org/10.1109/cvprw.2017.151
Liu Z, Luo P, Wang X, Tang X (2015) Deep learning face attributes in the wild. In: Proceedings of the IEEE international conference on computer vision, pp 3730–3738. https://doi.org/10.1109/iccv.2015.425
Liu S, Yang J, Huang C, Yang M-H (2015) Multi-objective convolutional learning for face labeling. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3451–3459. https://doi.org/10.1109/cvpr.2015.729897
Liu G, Reda F A, Shih K J, Wang T-C, Tao A, Catanzaro B (2018) Image inpainting for irregular holes using partial convolutions. In: Proceedings of the European conference on computer vision (ECCV), pp 85–100. https://doi.org/10.1007/978-3-030-01252-6_6
Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, Lin S, Guo B (2021) Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 10012–10022. https://doi.org/10.1109/iccv48922.2021.00986
Lu W, Zhao H, Jiang X, Jin X, Wang M, Lyu J, Shi K (2022) Diverse facial inpainting guided by exemplars. arXiv:2202.06358
Ma C, Jiang Z, Rao Y, Lu J, Zhou J (2020) Deep face super-resolution with iterative collaboration between attentive recovery and landmark estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 5569–5578. https://doi.org/10.1109/cvpr42600.2020.00561
Ma X, Zhou X, Huang H, Jia G, Chai Z, Wei X (2022) Contrastive attention network with dense field estimation for face completion. Pattern Recogn 124:108465. https://doi.org/10.1016/j.patcog.2021.108465
Meng Q, Zhao S, Huang Z, Zhou F (2021) Magface: a universal representation for face recognition and quality assessment. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 14225–14234. https://doi.org/10.1109/cvpr46437.2021.01400
Qiu H, Gong D, Li Z, Liu W, Tao D (2021) End2end occluded face recognition by masking corrupted features. IEEE Trans Pattern Anal Mach Intell. https://doi.org/10.1109/tpami.2021.3098962
Telea A (2004) An image inpainting technique based on the fast marching method. J Graph Tools 9(1):23–34. https://doi.org/10.1080/10867651.2004.10487596
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, Kaiser L, Polosukhin I (2017) Attention is all you need. Advances in Neural Information Processing Systems, 30
Wang L, Wang Y, Liang Z, Lin Z, Yang J, An W, Guo Y (2019) Learning parallax attention for stereo image super-resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 12250–12259. https://doi.org/10.1109/cvpr.2019.01253
Wang X, Li Y, Zhang H, Shan Y (2021) Towards real-world blind face restoration with generative facial prior. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 9168–9178. https://doi.org/10.1109/cvpr46437.2021.00905
Wang H, Hu Q, Wu C, Chi J, Yu X, Wu H (2021) Dclnet: dual closed-loop networks for face super-resolution. Knowl-Based Syst 222:106987. https://doi.org/10.1016/j.knosys.2021.106987
Wang J, Chen S, Wu Z, Jiang Y-G (2022) Ft-tdr: frequency-guided transformer and top-down refinement network for blind face inpainting. IEEE Trans Multimedia. https://doi.org/10.1109/tmm.2022.3146774
Wang Y, Hu Y, Zhang J (2022) Panini-net: gan prior based degradation-aware feature interpolation for face restoration. In: Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)
Wang Z, Bovik A C, Sheikh H R, Simoncelli E P (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process 13(4):600–612. https://doi.org/10.1109/tip.2003.819861
Yang Y, Guo X, Ma J, Ma L, Ling H (2019) Lafin: generative landmark guided face inpainting. arXiv:1911.11394. https://doi.org/10.1007/978-3-030-60633-6_2
Yang L, Wang S, Ma S, Gao W, Liu C, Wang P, Ren P (2020) Hifacegan: face renovation via collaborative suppression and replenishment. In: Proceedings of the 28th ACM international conference on multimedia, pp 1551–1560. https://doi.org/10.1145/3394171.3413965
Yang T, Ren P, Xie X, Zhang L (2021) Gan prior embedded network for blind face restoration in the wild. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 672–681. https://doi.org/10.1109/cvpr46437.2021.00073
Yi D, Lei Z, Liao S, Li S Z (2014) Learning face representation from scratch. arXiv:1411.7923
Yu X, Porikli F (2016) Ultra-resolving face images by discriminative generative networks. In: European conference on computer vision. Springer, pp 318–333. https://doi.org/10.1007/978-3-319-46454-1_20
Yu X, Porikli F (2017) Face hallucination with tiny unaligned images by transformative discriminative neural networks. In: Proceedings of the AAAI conference on artificial intelligence, vol 31
Yu X, Fernando B, Ghanem B, Porikli F, Hartley R (2018) Face super-resolution guided by facial component heatmaps. In: Proceedings of the European Conference on Computer Vision (ECCV), pp 217–233. https://doi.org/10.1007/978-3-030-01240-3_14
Yuan L, Chen Y, Wang T, Yu W, Shi Y, Jiang Z-H, Tay FEH, Feng J, Yan S (2021) Tokens-to-token vit: training vision transformers from scratch on imagenet. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 558–567. https://doi.org/10.1109/iccv48922.2021.00060
Zamir S W, Arora A, Khan S, Hayat M, Khan F S, Yang M-H (2021) Restormer: efficient transformer for high-resolution image restoration. arXiv:2111.09881
Zhang S, He R, Sun Z, Tan T (2017) Demeshnet: blind face inpainting for deep meshface verification. IEEE Trans Inf Forensics Secur 13(3):637–647. https://doi.org/10.1109/tifs.2017.2763119
Zhang X, Wang X, Shi C, Yan Z, Li X, Kong B, Lyu S, Zhu B, Lv J, Yin Y, er al (2022) De-gan: domain embedded gan for high quality face image inpainting. Pattern Recogn 124:108415. https://doi.org/10.1016/j.patcog.2021.108415
Zheng S, Lu J, Zhao H, Zhu X, Luo Z, Wang Y, Fu Y, Feng J, Xiang T, Torr PHS et al (2021) Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 6881–6890. https://doi.org/10.1109/cvpr46437.2021.00681
Zhong Y, Deng W, Hu J, Zhao D, Li X, Wen D (2021) Sface: sigmoid-constrained hypersphere loss for robust face recognition. IEEE Trans Image Process 30:2587–2598. https://doi.org/10.1109/tip.2020.3048632
Zhu Z, Huang G, Deng J, Ye Y, Huang J, Chen X, Zhu J, Yang T, Lu J, Du D et al (2021) Webface260m: a benchmark unveiling the power of million-scale deep face recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 10492–10502. https://doi.org/10.1109/cvpr46437.2021.01035
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interests
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wang, H., Chi, J., Wu, C. et al. Progressive local-to-global vision transformer for occluded face hallucination. Multimed Tools Appl 83, 8219–8240 (2024). https://doi.org/10.1007/s11042-023-15028-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-15028-2