
Abstract
Deep-learning based speech enhancement included many applications like improving speech intelligibility and perceptual quality. There are many methods which focus on amplitude spectrum enhancement. In the existing models, computation of the complex layer is huge which leads to a very big challenge to the device. DFT data is complex valued, so computation is difficult since we need to deal with the both real and imaginary parts of the signal at the same time. To reduce the computation, some researchers use the variants of STFT as input, such as amplitude/energy spectrum, Log-Mel spectrum, etc. They all enhance amplitude spectrum without estimating clean phase, this would limit the enhancement performance. In the proposed method DCT is used which is real-valued transformation without information lost and contains implicit phase. This avoids the problem of manually design a complex network to estimate the explicit phase and it will improve the enhancement performance. More research have done on phase spectrum estimation directly and indirectly, but it is not ideal. Recently, complex valued models are proposed like deep complex convolution recurrent network (DCCRN). The computation of the model is very huge. So a Deep Cosine transform convolutional Gated recurrent Unit (DCTCGRU) is proposed to reduce the complexity and improve further performance. GRU can well model the correlation between adjacent frames of noisy speech. The results from the experiment show that DCTCGRU achieves better results in terms of SNR, PESQ and STOI compared with the state-of-the-art algorithms.


Similar content being viewed by others

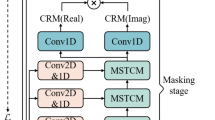

Data availability
The dataset is publicly available.
References
Ahmed N, Natarajan T, Rao KR (1974) Discrete cosine transform. IEEE transactions on Computers 100:90–93
Allen JB, Berkley DA (1979) Image method for efficiently simulating small-room acoustics. J Acoust Soc Am 65:943–950
Chen D, Li X, Li S (2021) A novel convolutional neural network model based on beetle antennae search optimization algorithm for computerized tomography diagnosis. IEEE Trans Neural Netw Learning. 12-24
Choi H-S, Kim J-H, Huh J, Kim A, Ha J-W, Lee K (2018) Phase-aware speech enhancement with deep complex u-net. International Conference on Learning Representations
Delfarah M, Wang D (2017) Features for masking-based monaural speech separation in reverberant conditions. IEEE/ACM Transactions on Audio, Speech, and Language Processing 25:1085–1094
Erdogan H, Hershey JR, Watanabe S, Le Roux J(2015) Phase sensitive and recognition-boosted speech separation using deep recurrent neural networks. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 708–712
Garofolo JS, Lamel LF, Fisher WM, Fiscus JG, Pallett DS (1993) Darpa timit acoustic-phonetic continous speech corpus cd-romnist speech disc 1-1.1, NASA STI/Recon technical report n, 93:27403
Geng C, Wang L (2020) End-to-end speech enhancement based on discrete cosine transform. IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA) 379–383
Hao X, Su X, Wen S, Wang Z, Pan Y, Bao F, Chen W (2020) Masking and inpainting: A two stage speech enhancement approach for low SNR and Non-stationary noise. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) Barcelona , Spain. ICASSP.312-319
Hu G, Wang D (2001) Speech segregation based on pitch tracking and amplitude modulation. IEEE Workshop on the Applications of Signal Processing to Audio and Acoustics (Cat. No. 01TH8575) 79–82
Hu X, Liu Y Xie L (2020) Dccrn: Deep complex convolution recurrent network for phase-aware speech enhancement. Interspeech.2472–2476
Huiyan L, Jin L, Luo X, Liao B, Guo D, Xiao L (2019) RNN for Solving Perturbed Time-Varying Underdetermined Linear System With Double Bound Limits on Residual Errors and State Variables. IEEE Transactions on Industrial Informatics 15:5931–5942
Jansson A, Humphrey E, Montecchio N, Bittner R, Kumar A, Weyde T (2017) Singing voice separation with deep U-NET convolutional networks. Proceedings of the 18th ISMIR Conference, Suzhou, China, 23-27
Khan AT, Li S, Cao X (2022) Human guided cooperative robotic agents in smart home using beetle antennae search. Sci China Inform Sci 21-34
Kolbæk M, Tan Z-H, Jensen J (2018) Monaural speech enhancement using deep neural networks by maximizing a short-time objective intelligibility measure. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 5059–5063
Kumar S; Kumar K (2018) IRSC: Integrated automated Review mining System using Virtual Machines in Cloud environment. Conference on Information and Communication Technology (CICT). 52-58
Kumari S, Singh M, Kumar K (2019) Prediction of Liver Disease Using Grouping of Machine Learning Classifiers, International Conference on Deep Learning, Artificial Intelligence and Robotics, Conference Proceedings of ICDLAIR2019:339–349
Kutner M, Nachtsheim C, Neter J, Li W (2004) Applied linear statistical models. McGraw Hill
Le Roux J, Wisdom S, Erdogan H, Hershey JR (2019) SDR–half-baked or well done? IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 626–630
Lei Y, Zhu H, Zhang J, Shan H (2022) Meta Ordinal Regression Forest for Medical Image Classification With Ordinal Labels. IEEE/CAA J Automatic Sinica 9:3–10
Li Z, Li S, Luo X ( 2021) An overview of calibration technology of industrial robots. IEEE/CAA J Automatica Sinica 8: 23 – 36
Li Z, Li S, Bamasag OO, Alhothali A, Luo X (2022) Diversified regularization enhanced training for effective manipulator calibration. IEEE Trans Neural Netw Learning Syst ( Early Access ). 1 - 13
Liu Q, Wang W, Jackson PJ, Tang Y (2017) A perceptually-weighted deep neural network for monaural speech enhancement in various back-ground noise conditions. 25th European Signal Processing Conference (EUSIPCO),1270–1274
Luo Y, Mesgarani N (2019) Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation. IEEE/ACM trans-actions on audio, speech, and language processing 27:1256–1266
Macartney, Weyde T (2018) Improved speech enhancement with the wave-u-net. arXiv preprint arXiv:1811.11307
Martin-Donas JM, Gomez AM, Gonzalez JA, Peinado AM (2018) A deep learning loss function based on the perceptual evaluation of the speech quality. IEEE Signal processing letters 25:1680–1684
Negi A, Kumar K, Chaudhari NS, Singh N, Chauhan P (2021) Predictive analytics for recognizing human activities using residual network and fine-tuning. Int Conference on Big Data Analytics 296–310
Paliwal K, Wojcicki K, Shannon B (2011) The importance of phase in ´ speech enhancement. speech communication 53:465–494
Pandey A, Wang DL (2021) Dense CNN with Self-Attention for Time-Domain Speech Enhancement. IEEE/ACM Transaction on Audio, Speech and Language Processing. 29-38
Pascual S, Bonafonte A, Serra J (2017) Segan: Speech enhancement generative adversarial network. arXiv preprint arXiv:1703.09452.
Reddy CK, Dubey H, Gopal V, Cutler R, Braun S, Gamper H, Aichner R, Srinivasan S (2020) Icassp 2021 deep noise suppression challenge,” arXiv preprint arXiv:2009.06122
Reddy CK, Beyrami E, Dubey H, Gopal V, Cheng R, Cutler R, Matusevych S, Aichner R, Aazami A, Braun S et al. (2020) The interspeech 2020 deep noise suppression challenge: Datasets, subjective speech quality and testing framework. arXiv preprint arXiv:2001.08662
Ronneberger O, Fischer P, Brox T ( 2015) U-net: Convolutional networks for biomedical image segmentation. International Conference on Medical image computing and computer-assisted intervention. Springer.234–241
Sandhya P, Bandi R, Himabindu DD (2022) Stock Price Prediction using Recurrent Neural Network and LSTM,” 6th International Conference on Computing Methodologies and Communication (ICCMC). 29-35
Scalart P et al (1996) Speech enhancement based on a priori signal to noise estimation. IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings. 2:629–663
Sharma S, Kumar K (2021) ASL-3DCNN: American sign language recognition technique using 3-D convolutional neural networks. Multim Tools Appl 80:26319–26331
Sharma S, Shivhare SN, Singh N, Kumar K (2018) Computationally efficient ANN model for small-scale problems. Conference on Machine Intelligence and Signal Analysis 423–435
Shivakumar PG, Georgiou PG ( 2016) Perception optimized deep denoising autoencoders for speech enhancement. in Interspeech, 3743–3747
Srinivasan S, Roman N, Wang D (2006) Binary and ratio time-frequency masks for robust speech recognition. Speech Communication. 48:1486–1501
Srinivasu PN, Bhoi AK, Jhaveri RH, Reddy GT, Bilal M (2021) Probabilistic Deep Q Network for real-time path planning in censorious robotic procedures using force sensors. J Real-Time Image Process 18:1773–1785
Srinivasu PN, JayaLakshmi G, Jhaveri RH, Praveen SP (2022) Ambient assistive living for monitoring the physical activity of diabetic adults through body area networks. Hindawi Mobile Information Systems 36-47
Tan K, Wang D (2018) A convolutional recurrent neural network for real-time speech enhancement.” in Interspeech. 3229–3233
Tan K, Wang D (2019) Complex spectral mapping with a convolutional recurrent network for monaural speech enhancement. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 6865–6869
Tukey JW (1949) Comparing individual means in the analysis of variance,” Biometrics, pp. 99–114
Varga A, Steeneken HJ (1993) Assessment for automatic speech recognition: Ii. noisex-92: A database and an experiment to study the effect of additive noise on speech recognition systems. Speech communication 12:247–251
Vijayvergia A, Kumar K (2018) STAR: rating of reviewS by exploiting variation in emoTions using trAnsfer leaRning framework,” Conference on Information and Communication Technology (CICT). 26-30
Vijayvergia A, Kumar K (2021) Selective shallow models strength integration for emotion detection using GloVe and LSTM. Multimedia Tools and Applications 80:28349–28363
Wang Y, Narayanan A, Wang D (2014) On training targets for supervised speech separation. IEEE/ACM transactions on audio, speech, and language processing 22:1849–1858
Wang W, Tang C, Wang X, Zheng B (2022) A ViT-Based Multiscale Feature Fusion Approach for Remote Sensing Image Segmentation. IEEE Geoscience and Remote Sensing Letters.19
Huaqing Wang, Tianjiao Lin, Lingli Cui, Bo Ma, Zuoyi Dong, Liuyang Song, (2022) Multitask Learning-Based Self-Attention Encoding Atrous Convolutional Neural Network for Remaining Useful Life Prediction. IEEE Transactions on Instrumentation and Measurement. 71
Williamson DS, Wang Y, Wang D (2015) Complex ratio masking for monaural speech separation. IEEE/ACM transactions on audio, speech, and language processing 24:483–492
Xu Y, Du J, Dai L-R, Lee C-H (2013) An experimental study on speech enhancement based on deep neural networks. IEEE Signal Processing Letters 21:65–68
Yang X, Zhang J, Chen C, Yang D (2022) An Efficient and Lightweight CNN Model With Soft Quantification for Ship Detection in SAR Images. IEEE Transactions on Geoscience and Remote Sensing.60
Zhang OBY, Serdyuk D, Subramanian S, Santos JF, Mehri S, Rostamzadeh N, Bengio Y, Trabelsi C, Pal CJ (2017) Deep complex networks. 1705.09792
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Vanambathina, S.D., Anumola, V., Tejasree, P. et al. Convolutional gated recurrent unit networks based real-time monaural speech enhancement. Multimed Tools Appl 82, 45717–45732 (2023). https://doi.org/10.1007/s11042-023-15639-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-15639-9