
Abstract
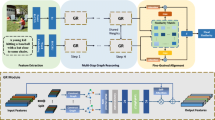
Cross-modal image-text retrieval has gained increasing attention due to its ability to combine computer vision with natural language processing. Previously, image and text features were extracted and concatenated to feed the transformer-based retrieval network. However, these approaches implicitly aligned the image and text modalities since the self-attention mechanism computes attention coefficients for all input features. In this paper, we propose cross-modal Semantic Alignments Module (SAM) to establish an explicit alignment through enhancing an inter-modal relationship. Firstly, visual and textual representations were extracted from an image and text pair. Secondly, we constructed a bipartite graph by representing the image regions and words in the sentence as nodes, and the relationship between them as edges. Then our proposed SAM allows the model to compute attention coefficients based on the edges in the graph. This process helps explicitly align the two modalities. Finally, a binary classifier was used to determine whether the given image-text pair is aligned. We reported extensive experiments on MS-COCO and Flickr30K test sets, showing that SAM could capture the joint representation between the two modalities and could be applied to the existing retrieval networks.





Similar content being viewed by others


Data availability
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
References
Ba J, Kiros JR, Hinton GE (2016) Layer normalization. ArXiv arXiv:1607.06450
Bi B, Li C, Wu C, et al (2020) Palm: pre-training an autoencodingautoregressive language model for context-conditioned generation. In: Conference on empirical methods in natural language processing
Chen S, Jin Q, Wang P et al (2020) Say as you wish: fine-grained control of image caption generation with abstract scene graphs. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2020:9959–9968
Chen T, Tian R, Ding Z (2021) Visual reasoning using graph convolutional networks for predicting pedestrian crossing intention. IEEE/CVF International Conference on Computer Vision Workshops (ICCVW) 2021:3096–3102
Chen YC, Li L, Yu L, et al (2019) Uniter: learning universal image-text representations. ArXiv arXiv:1909.11740
Dai Z, Lai G, Yang Y, et al (2020) Funnel-transformer: filtering out sequential redundancy for efficient language processing. ArXiv arXiv:2006.03236
Devlin J, Chang MW, Lee K, et al (2019) Bert: pre-training of deep bidirectional transformers for language understanding. ArXiv arXiv:1810.04805
Diao H, Zhang Y, Ma L, et al (2021) Similarity reasoning and filtration for image-text matching. ArXiv arXiv:2101.01368
Dong X, Long C, Xu W, et al (2021) Dual graph convolutional networks with transformer and curriculum learning for image captioning. Proceedings of the 29th ACM International Conference on Multimedia
Faghri F, Fleet DJ, Kiros JR, et al (2017) Vse++: improving visual-semantic embeddings with hard negatives. In: British machine vision conference
Frisoni G, Mizutani M, Moro G, et al (2022) Bioreader: a retrieval-enhanced text-to-text transformer for biomedical literature. In: Proceedings of the 2022 conference on empirical methods in natural language processing, pp 5770–5793
Gao H, Xu K, Cao M et al (2021) The deep features and attention mechanism-based method to dish healthcare under social iot systems: an empirical study with a hand-deep local-global net. IEEE Transactions on Computational Social Systems 9(1):336–347
Gao H, Fang D, Xiao J, et al (2022a) Camrl: a joint method of channel attention and multidimensional regression loss for 3d object detection in automated vehicles. IEEE Trans Intell Transp Syst
Gao H, Xiao J, Yin Y, et al (2022b) A mutually supervised graph attention network for few-shot segmentation: the perspective of fully utilizing limited samples. IEEE Transactions on Neural Networks and Learning Systems
Guo D, Xu C, Tao D (2021) Bilinear graph networks for visual question answering. IEEE Transactions on Neural Networks and Learning Systems PP
Guo J, Lu S, Cai H, et al (2018) Long text generation via adversarial training with leaked information. In: Proceedings of the AAAI conference on artificial intelligence
Hamilton WL, Ying Z, Leskovec J (2017) Inductive representation learning on large graphs. In: NIPS
Henderson M, Casanueva I, Mrkvsi’c N, et al (2019) Convert: efficient and accurate conversational representations from transformers. ArXiv arXiv:1911.03688
Ji Z, Chen K, Wang H (2021) Step-wise hierarchical alignment network for image-text matching. ArXiv arXiv:2106.06509
Karpathy A, Fei-Fei L (2015) Deep visual-semantic alignments for generating image descriptions. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3128–3137
Kayhan N, Fekri-Ershad S (2021) Content based image retrieval based on weighted fusion of texture and color features derived from modified local binary patterns and local neighborhood difference patterns. Multimed Tools Appl 80(21–23):32763–32790
Kim J, Yoon S, Kim D, et al (2021a) Structured co-reference graph attention for video-grounded dialogue. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp 1789–1797
Kim W, Son B, Kim I (2021b) Vilt: Vision-and-language transformer without convolution or region supervision. In: International Conference on Machine Learning
Kipf T, Welling M (2017) Semi-supervised classification with graph convolutional networks. ArXiv arXiv:1609.02907
Krishna R, Zhu Y, Groth O et al (2017) Visual genome: connecting language and vision using crowdsourced dense image annotations. Int J Comput Vis 123(1):32–73
Lee KH, Chen X, Hua G, et al (2018) Stacked cross attention for image-text matching. ArXiv arXiv:1803.08024
Li LH, Yatskar M, Yin D, et al (2019) Visualbert: a simple and performant baseline for vision and language. ArXiv arXiv:1908.03557
Li X, Yin X, Li C, et al (2020) Oscar: object-semantics aligned pre-training for vision-language tasks. In: European conference on computer vision
Lin J (2022) A proposed conceptual framework for a representational approach to information retrieval. ACM SIGIR Forum. ACM, New York, pp 1–29
Lin TY, Maire M, Belongie SJ, et al (2014) Microsoft coco: common objects in context. In: European conference on computer vision
Ling H, Kreis K, Li D et al (2021) Editgan: high-precision semantic image editing. Adv Neural Inf Proces Syst 34:16331–16345
Loshchilov I, Hutter F (2017) Decoupled weight decay regularization. In: International conference on learning representations
Lu J, Batra D, Parikh D, et al (2019) Vilbert: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In: Neural information processing systems
Lu J, Goswami V, Rohrbach M et al (2020) 12-in-1: multi-task vision and language representation learning. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2020:10434–10443
Lu X, Zhao T, Lee K (2021) Visualsparta: an embarrassingly simple approach to large-scale text-to-image search with weighted bag-of-words. In: ACL
Maas AL, Hannun AY, Ng AY, et al (2013) Rectifier nonlinearities improve neural network acoustic models. In: Proc. Icml, Atlanta, p 3
Messina N, Amato G, Esuli A et al (2021) Fine-grained visual textual alignment for cross-modal retrieval using transformer encoders. ACM Trans Multimed Comput Commun Appl (TOMM) 17:1–23
Plummer BA, Wang L, Cervantes CM, et al (2015) Flickr30k entities: collecting region-to-phrase correspondences for richer image-to-sentence models. In: Proceedings of the IEEE international conference on computer vision, pp 2641–2649
Ren S, He K, Girshick RB et al (2015) Faster r-cnn: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell 39:1137–1149
Shah R, Bhatti N, Akhtar N et al (2020) Random patterns clothing image retrieval using convolutional neural network. International Conference on Emerging Trends in Smart Technologies (ICETST) 2020:1–6
Song K, Tan X, Qin T, et al (2020) Mpnet: masked and permuted pre-training for language understanding. ArXiv arXiv:2004.09297
Song X, Jing L, Lin D, et al (2022) V2p: vision-to-prompt based multi-modal product summary generation. In: Proceedings of the 45th International ACM SIGIR conference on research and development in information retrieval, pp 992–1001
Su W, Zhu X, Cao Y, et al (2020) Vl-bert: pre-training of generic visual-linguistic representations. ArXiv arXiv:1908.08530
Takase S, Kiyono S (2021) Lessons on parameter sharing across layers in transformers. arXiv preprint arXiv:2104.06022
Tan HH, Bansal M (2019) Lxmert: learning cross-modality encoder representations from transformers. ArXiv arXiv:1908.07490
Toker A, Zhou Q, Maximov M et al (2021) Coming down to earth: satellite-to-street view synthesis for geo-localization. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2021:6484–6493
Vaswani A, Shazeer N, Parmar N, et al (2017) Attention is all you need. Adv Neural Inf Proces Syst 30
Velickovic P, Cucurull G, Casanova A, et al (2017) Graph attention networks. ArXiv arXiv:1710.10903
Wang W, Zheng H, Lin Z (2020) Self-attention and retrieval enhanced neural networks for essay generation. ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 8199–8203
Wang Y, Yang H, Qian X, et al (2019a) Position focused attention network for image-text matching. ArXiv arXiv:1907.09748
Wang Z, Liu X, Li H et al (2019) Camp: cross-modal adaptive message passing for text-image retrieval. IEEE/CVF International Conference on Computer Vision (ICCV) 2019:5763–5772
Yang D, Wu D, Zhang W, et al (2020) Deep semantic-alignment hashing for unsupervised cross-modal retrieval. Proceedings of the 2020 International conference on multimedia retrieval
Yang Z, Dai Z, Yang Y, et al (2019) Xlnet: generalized autoregressive pretraining for language understanding. Adv Neural Inf Proces Syst 32
Ye Y, Ji S (2021) Sparse graph attention networks. IEEE Trans Knowl Data Eng
Yu T, Liu J, Jin Z, et al (2022) Multi-scale multi-modal dictionary bert for effective text-image retrieval in multimedia advertising. In: Proceedings of the 31st ACM International Conference on Information & Knowledge Management, pp 4655–4660
Zhang S, Dinan E, Urbanek J, et al (2018) Personalizing dialogue agents: I have a dog, do you have pets too? In: Annual meeting of the association for computational linguistics
Zhang Y, Zhou W, Wang M et al (2020) Deep relation embedding for cross-modal retrieval. IEEE Trans Image Process 30:617–627
Zheng Z, Zheng L, Garrett M et al (2020) Dual-path convolutional image-text embeddings with instance loss. ACM Trans Multimed Comput Commun Appl (TOMM) 16(2):1–23
Acknowledgements
This research was supported in part by Institute for Information & communications Technology Planning & Evaluation (IITP) through the Korea government (MSIT) under Grant No. 2021-0-01341 (Artificial Intelligence Graduate School Program (Chung-Ang University), Contribution Rate: 33%), the National Research Foundation of Korea (NRF) through the Korea government (MSIT) under Grant No. NRF- 2022R1C1C1008534 (Contribution Rate: 33%), and Culture Technology R &D Program through the Korea Creative Content Agency grant funded by Ministry of Culture, Sports and Tourism in 2021 (Project Name: A Specialist Training of Content R &D based on Virtual Production, Project Number: R2021040044, Contribution Rate: 34%).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Park, P., Jang, S., Cho, Y. et al. SAM: cross-modal semantic alignments module for image-text retrieval. Multimed Tools Appl 83, 12363–12377 (2024). https://doi.org/10.1007/s11042-023-15798-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-15798-9