
Abstract
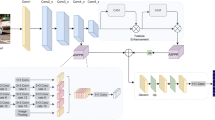
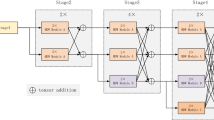
In the high-resolution network (HRNet), the low layer of low resolution part can adopt shallow parallel network structure to maintain the high-resolution features and highlight global features. However, the high-resolution human posture estimation network has the problems of large amount of network parameters, high complex calculation and low recognition precision of similar actions. To solve these problems, we proposed an optimized HRNet based on attention mechanism. Firstly, the dilated convolution (DC) module is introduced into cross-channel sampling to obtain global features by increasing the receptive field of the feature map, which ensures that the feature map can cover all the information of the original image; Secondly, the channel attention Squeeze-and-Excitation (SE) module is introduced in the process of cross-channel feature fusion to learn the correlations, which can recalibrate the features, highlight the information features selectively and suppress the secondary features, improving the recognition precision without changing the parameter quantity and operation complexity; Finally, the experiment results on KTH dataset show that the HRNet with channel attention mechanism and dilated convolution has better accuracy.









Similar content being viewed by others

Data availability
The datasets generated during and/or analyzed during the current study are available in the [KTH, Coco2017] repository, [http://www.nada.kth.se/cvap/actions/], [http://cocodataset.org/].
References
Peng C (2015) Pose Estimation Using Local Adjustment with Mixtures-of-parts Models. J Fiber Bioeng Informat 8(2):249–258
Bin X, Haiping W, Yichen W (2018) Simple Baselines for Human Pose Estimation and Tracking. Proc Eur Conference Comput Vis:1208-1215
Dalal N, Triggs B (2005) Histograms of oriented gradients for human detection. Proc IEEE Comput Soc Conference Comput Vis Pattern Recog 1:886–893
Sang S, Huang Z, Kang Z (2018) A Human Activity Recognition Method using the Maximum Optical Flow based Feature Bounding Box. Proc Int Conference Machine Learn Compu:1330-1337
Wu Y, Wei L, Duan Y (2021) Deep spatiotemporal LSTM network with temporal pattern feature for 3D human action recognition. Comput Intell 99:11–23
Nazir S, Yousaf MH, Velastin SA (2018) Evaluating a bag-of-visual features approach using spatio-temporal features for action recognition. Comput Electric Eng 72:660–669
Papandreou G, Zhu T, Murphy K (2017) Towards accurate multi-person pose estimation in the wild. Proc Int Conf Comput Vis, 144-158
Huang S-L, Gong M-M, Tao D-C (2017) A coarse-fine network for keypoint localization. Proc Int Conference Comput Vis:244-252
Wang H, Schmid C (2013) Action recognition with improved trajectories. Proc IEEE Int Conf Comput Vis:3551-3558
Huang J, Zhu Z, Guo F, Huang G (2020) The devil is in the details: Delving into unbiased data processing for human pose estimation. Proc Eur Conf Comput Vis :246–256
Liu H, Tu J, Liu M (2017) Two-Stream 3D Convolutional Neural Network for Skeleton-Based Action Recognition. Proc IEEE Conf Comput Vis Pattern Recog:1669–1676
Zhang Z, Hu Y, Chan S et al (2008) Motion context: A new representation for human action recognition. Proceedings of the European Conference on Computer Vision:817–829
Patel CI, Labana D, Pandya S et al (2020) Histogram of oriented gradient-based fusion of features for human action recognition in action video sequences. Sensors 20(24):7299
Nazir S, Yousaf MH, Velastin SA (2018) Evaluating a bag-of-visual features approach using spatio-temporal features for action recognition. Computers & Electrical Engineering 72:660–669
Newell A, Yang K, Deng J (2016) Stacked hourglass networks for human pose estimation. Proceedings of the European conference on computer vision:483–499
Kaiming H, Xiangyu Z, Shaoqing R, et al (2016) Deep residual learning for image recognition. Proc IEEE Conf Comput Vis Pattern Recog:770-778
Sun K, Xiao B, Liu D, et al (2019) Deep High-Resolution Representation Learning for Human Pose Estimation. Proc IEEE Conf Comput Vis Pattern Recog:5693-5703
Abhronil S, Yuting et al (2019) Going Deeper in Spiking Neural Networks: VGG and Residual Architectures. Front Neurosci 13:95
Zhou Z, Siddiquee MMR, Tajbakhsh N, et al (2018) Unet++: A nested u-net architecture for medical image segmentation. Deep Learn Med Image Anal Multimod Learn Clin Decision Support:3-11
Papandreou G, Zhu T, Chen LC, et al (2018) Personlab: Person pose estimation and instance segmentation with a bottom-up part-based geometric embedding model. Proc Eur Conf Comput Vis:269-286
Geng Z, Sun K, Xiao B, et al (2019) Bottom-Up Human Pose Estimation via Disentangled Keypoint Regression. Proc IEEE Data Driven Control Learn Syst Conf:174-187
Yu F, Koltun V (2016) Multi-scale context aggregation by dilated convolutions. Proc Int Conf Learn Represent 11:122
Jin S, Ma X, Han Z et al (2017) Towards multi-person pose tracking: Bottom-up and top-down methods. Proc IEEE Int Conf Comput Vis 2(3):7–18
Pavlakos G, Zhou X, Derpanis KG, Daniilidis K (2017) Coarse-to-fifine volumetric prediction for single-image 3D human pose. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Mehta D, Rhodin D, Casas P (2017) Monocular 3d human pose estimation in the wild using improved cnn supervision. Proc IEEE Int Conf Comput Vis:506-516
Hu J, Shen L, Sun G (2018) Squeeze-and-excitation networks. Proc IEEE conf Comput Vis Pattern Recogn:7132-7141
Martinez J, Hossain R, Little JJ (2017) A simple yet effective baseline for 3d human pose estimation. Proc IEEE Int Conf Comput Vis:218-223
Sun X, Shang J, Liang S, Wei Y (2017) Compositional human pose regression. Proc IEEE Int Conf Comput Vis:2702-2706
Yang W, Ouyang W, Wang X (2018) 3d human pose estimation in the wild by adversarial learning. Proc IEEE Conf Comput Vis Pattern Recog:443-451
Cao Z, Simon T, Wei S E, et al (2017) Realtime multi-person 2d pose estimation using part affinity fields. Proc IEEE Conf Comput Vis Pattern Recog:7291-7299
Xiao S, Bin X, Yichen W (2018) Integral Human Pose Regression. Proc IEEE Eur Conf Comput Vis:1024-1032
Cheng B, Xiao B, Wang J, et al (2020) Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. Proc IEEE/CVF Conf Comput Vis Pattern Recog:5386-5395
Congcong L, Jie Y, Haima Y et al (2021) Improved human action recognition approach based on two-stream convolutional neural network model. Vis Comput 37(6):1327–1341
Geng Z, Sun K, Xiao B, et al (2021) Bottom-up human pose estimation via disentangled keypoint regression. Proc IEEE/CVF Conf Comput Vis Pattern Recog:14676-14686
Yu F, Koltun V (2016) Multi-Scale Context Aggregation by Dilated Convolutions. Proc Int Conf Learn Represent:446-456
Chen LC, Papandreou G, Kokkinos I et al (2017) Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans Pattern Anal Mach Intell 40(4):834–848
Acknowledgements
This work is partially supported by the Natural Science Foundation of Jiangsu Province (No. BK20181340), and the National Natural Science Foundation of China (No. 61305017).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no known competing fnancial interests or personal relationships that could have appeared to infuence the work reported in this paper.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yang, J., Feng, Y. An optimization high-resolution network for human pose recognition based on attention mechanism. Multimed Tools Appl 83, 45535–45552 (2024). https://doi.org/10.1007/s11042-023-16793-w
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-16793-w