
Abstract
Compression artifacts cause negative visual perception and are tough to reduce because of the balance between compressibility and fidelity. Despite extensive research on traditional methods, they take insufficient effect on quality enhancement. Researches concerning the problem turn to concentrate on quality elevation of single frame using CNNs but ignore the continuity, which is called inter-frame correlation that is critical for video enhancement. There are some CNN-based approaches pursuing good effects, however, sacrificing efficiency. Considering the demand for video quality enhancement and the feature of consecutive frames, this paper proposes a bi-frame generative adversarial network. It takes advantage of inter-frame correlation for bi-frame motion compensation, producing accurate compensated frames. Then, a multi-scale convolutional layer with dilated filters, which constrains parameters and overcomes block effects, is proposed to promote efficiency. Subsequently, a multi-layer deep fusion section is employed to avoid gradients vanishing and realize deep compression artifacts reduction. The ability of discrimination is enhanced with the engagement of a devised relativistic average discriminator which optimizes the whole network. As experiment results demonstrated, bi-frame generative adversarial network shows its effectiveness in terms of various indices. It also presents satisfactory visual performance with comparative test speed compared to listed approaches.






Similar content being viewed by others

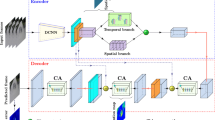
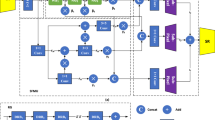
References
Ding DD, Ma Z, Chen D, Chen QS, LIU OE, ZHU FQ (2021) Advances in video compression system using deep neural network: a review and case studies. Proc IEEE 109:1494–1520
List P, Joch A, Lainema J, BJONTEGAARD G, KARCZEWICZ M (2003) Adaptive deblocking filter. IEEE Trans Circuits Syst Video Technol 13:614–619
FU C-M, ALSHINA E, ALSHIN A, HUANG Y-W, CHEN C-Y, TSAI C-Y, HSU C-W, LEI S-M, PARK J-H, HAN W-J (2012) Sample adaptive offset in the HEVC standard. IEEE Trans Circuits Syst Video Technol 22:1755–1764
Foi A, KATKOVNIK V, EGIAZARIAN K (2007) Pointwise shape-adaptive DCT for high-quality denoising and deblocking of grayscale and color images. IEEE Trans Image Process 16:1395–411
He KM, Zhang XY, Ren SQ, Sun J (2016) Deep residual learning for image recognition. Ieee Conf Comput Vis Pattern Recognit (Cvpr) 2016:770–778
Wang J, Sun K, Cheng T, Jiang B, Deng C, Zhao Y, Liu D, Mu Y, Tan M, Wang X, LIU W, XIAO B (2021) Deep high-resolution representation learning for visual recognition. IEEE Trans Pattern Anal Mach Intell 43:3349–3364
Chen K, Lin W, Li J, See J, WANG J, ZOU J (2021) AP-loss for accurate one-stage object detection. IEEE Trans Pattern Anal Mach Intell 43:3782–3798
Liu ST, HUANG D, WANG YH (2018) Receptive field block net for accurate and fast object detection. Comput Vis Eccv 2018 Pt Xi 11215:404–419
Meng Y, Kong D, ZHU Z, ZHAO Y (2019) From night to day: GANs based low quality image enhancement. Neural Process Lett 50:799–814
Almalioglu Y, BENGISU OZYORUKK, GOKCE A, INCETAN K, IREM GOKCELERG, ALI SIMSEKM, ARARAT K, CHEN RJ, DURR NJ, MAHMOOD F, TURAN M (2020) EndoL2H: deep super-resolution for capsule endoscopy. IEEE Trans Med Imaging 39:4297–4309
Liu H, Cao F (2020) Improved dual-scale residual network for image super-resolution. Neural Netw 132:84–95
Lei P, Liu C (2020) Inception residual attention network for remote sensing image super-resolution. Int J Remote Sens 41:9565–9587
Dong C, Deng Y, LOY CC, TANG X (2015) Compression artifacts reduction by a deep convolutional network. IEEE Int Conf Comput Vis (ICCV) 2015:576–584
Kim J, Lee JK, Lee KM (2016) Accurate image super-resolution using very deep convolutional networks. IEEE Conf Comput Vis Pattern Recognit (CVPR) 2016:1646–1654
Shi WZ, Caballero J, Huszar F, Totz J, Aitken AP, Bishop R, RUECKERT D, WANG ZH (2016) Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. Ieee Conf Comput Vis Pattern Recognit (Cvpr) 2016:1874–1883
Dai YY, LIU D, WU F (2017) A convolutional neural network approach for post-processing in HEVC intra coding. Multimedia Model (Mmm 2017) 10132:28–39
Galteri L, Seidenari L, Bertini M, Bimbo AD (2017) Deep generative adversarial compression artifact removal. IEEE Int Conf Comput Vis (ICCV) 2017:4836–4845
Ledig C, Theis L, Huszar F, Caballero J, Cunningham A, Acosta A, Aitken A, Tejani A, Totz J, Wang Z., Shi W (2017) Photo-realistic single image super-resolution using a generative adversarial network. In: IEEE conference on computer vision and pattern recognition (CVPR) 2017, pp 105–114
Zhang K, Zuo W, Chen Y, MENG D, ZHANG L (2017) Beyond a Gaussian denoiser: residual learning of deep CNN for image denoising. IEEE Trans Image Process 26:3142–3155
Kupyn O, Budzan V, Mykhailych M, MISHKIN D, MATAS J (2018) DeblurGAN: blind motion deblurring using conditional adversarial networks. Ieee/Cvf Conf Comput Vis Pattern Recognit (Cvpr) 2018:8183–8192
Sajjadi MSM, Vemulapalli R, Brown M (2018) Frame-recurrent video super-resolution. In: IEEE/CVF conference on computer vision and pattern recognition 2018, pp 6626–6634
Yang R, Xu M, WANG Z, LI T (2018) Multi-frame quality enhancement for compressed video. IEEE/CVF Conf Comput Vis Pattern Recognit 2018:6664–6673
Zhang YL, Li KP, Li K, Wang LC, ZHONG BN, FU Y (2018) Image super-resolution using very deep residual channel attention networks. Comput Vis Eccv 2018 11211:294–310
Wang X, Yu K, Wu S, Gu J, Liu Y, Dong C, Qiao Y, Loy CC (2019) ESRGAN: enhanced super-resolution generative adversarial networks. Comput Vis ECCV 2018 Workshops pp 63–79
Xue T, Chen B, Wu J, WEI D, FREEMAN WT (2019) Video enhancement with task-oriented flow. Int J Comput Vis 127:1106–1125
Yang R, Xu M, Liu T, WANG Z, GUAN Z (2019) Enhancing quality for HEVC compressed videos. IEEE Trans Circuits Syst Video Technol 29:2039–2054
Zhang Z, WANG X, JUNG C (2019) DCSR: dilated convolutions for single image super-resolution. IEEE Trans Image Process 28:1625–1635
Lin W, He X, Han X, Liu D, See J, Zou J, XIONG H, WU F (2020) Partition-aware adaptive switching neural networks for post-processing in HEVC. IEEE Trans Multimedia 22:2749–2763
Goodfellow IJ, Pouget-abadie J, Mirza M, Xu B, Warde-farley D, Ozair S, Courville A, Bengio Y (2014) Generative adversarial nets. Adv Neural Inf Process Syst 27:2672–2680
Ilg E, Mayer N, Saikia T, Keuper M, Dosovitskiy A, Brox T (2017) FlowNet 2.0: evolution of optical flow estimation with deep networks. In: 2017 IEEE conference on computer vision and pattern recognition (CVPR), pp 1647–1655
Chen L, Cui M, Zhang F, HU B, HUANG K (2019) High-speed scene flow on embedded commercial off-the-shelf systems. IEEE Trans Ind Inf 15:1843–1852
Ranjan A, Black MJ (2017) Optical flow estimation using a spatial pyramid network. IEEE Conf Comput Vis Pattern Recognit (CVPR) 2017:2720–2729
Dong C, Loy CC, HE K, TANG X (2016) Image super-resolution using deep convolutional networks. IEEE Trans Pattern Anal Mach Intell 38:295–307
Lan R, Sun L, Liu Z, Lu H, PANG C, LUO X (2021) MADNet: a fast and lightweight network for single-image super resolution. IEEE Trans Cybernet 51:1443–1453
Zhang K, VAN GOOL L, TIMOFTE R (2020) Deep unfolding network for image super-resolution. Ieee/Cvf Conf Comput Vis Pattern Recognit (Cvpr) 2020:3214–3223
Guo Y, Chen J, Wang J, Chen Q, Cao J, Deng Z, XU Y, TAN M (2020) Closed-loop matters: dual regression networks for single image super-resolution. IEEE/CVF Conf Comput Vis Pattern Recognit (CVPR) 2020:5406–5415
Adil M, Mamoon S, Zakir A, MANZOOR MA, LIAN ZC (2020) Multi scale-adaptive super-resolution person re-identification using GAN. Ieee Access 8:177351–177362
Yi P, Wang Z, Jiang K, SHAO Z, MA J (2020) Multi-temporal ultra dense memory network for video super-resolution. IEEE Trans Circuits Syst Video Technol 30:2503–2516
Caballero J, Ledig C, Aitken A, Acosta A, Totz J, WANG Z, SHI W (2017) Real-time video super-resolution with spatio-temporal networks and motion compensation. IEEE Conf Comput Vis Pattern Recognit (CVPR) 2017:2848–2857
Haris M, SHAKHNAROVICH G, UKITA N (2020) Space-time-aware multi-resolution video enhancement. Ieee/Cvf Conf Comput Vis Pattern Recognit (Cvpr) 2020:2856–2865
Chen C, Xiong ZW, Tian XM, ZHA ZJ, WU F (2020) Real-world image denoising with deep boosting. IEEE Trans Pattern Anal Mach Intell 42:3071–3087
Zhang TT, Li YJ, Takahashi S (2021) Underwater image enhancement using improved generative adversarial network. Concurr Comput Pract Exp 33
Meng YY, Kong DQ, ZHU ZF, ZHAO Y (2019) From night to day: gans based low quality image enhancement. Neural Process Lett 50:799–814
Feng H, Guo JD, Xu HX, Ge SS (2021) SharpGAN: dynamic scene deblurring method for smart ship based on receptive field block and generative adversarial networks. Sensors 21
Dhanalakshmi A, Nagarajan G (2020) Convolutional neural network-based deblocking filter for SHVC in H.265. SIViP 14:1635–1645
Yang R, XU M, WANG ZL (2017) Decoder-Side Hevc quality enhancement with scalable convolutional neural network. Ieee Int Conf Multimedia Expo (Icme) 2017:817–822
Jaderberg M, Simonyan K, Zisserman A, Kavukcuoglu K (2015) Spatial transformer networks. Adv Neural Inf Process Syst 28 (Nips 2015) 28
Huang G, Liu Z, Van der Maaten L, Weinberger KQ(2017) Densely connected convolutional networks. In: 30th IEEE conference on computer vision and pattern recognition 2261–2269
Zhao H, Gallo O, FROSTIG I, KAUTZ J (2017) Loss functions for image restoration with neural networks. IEEE Trans Comput Imaging 3:47–57
Wang T, CHEN M, CHAO H (2017) A novel deep learning-based method of improving coding efficiency from the decoder-end for HEVC. Data Compress Conf (DCC) 2017:410–419
Bossen F (2011) Common test conditions and software reference configurations. In: Joint Collaborative Team on Video Coding (JCT-VC) of ITU-T SG16 WP3 and ISO/IEC JTC1/SC29/WG11, 5th meeting
Ma C, YANG C-Y, YANG X, YANG M-H (2017) Learning a no-reference quality metric for single-image super-resolution. Comput Vis Image Underst 158:1–16
Mittal A, SOUNDARARAJAN R, BOVIK AC (2013) Making a “Completely Blind’’ Image Quality Analyzer. IEEE Signal Process Lett 20:209–212
Johnson J, ALAHI A, LI FF (2016) Perceptual losses for real-time style transfer and super-resolution. Comput Vis Eccv 2016 9906:694–711
Acknowledgements
This work is supported by the National Natural Science Foundation of China (Grant Nos. 61871279 and 62081330105) and the Fundamental Research Funds for the Central Universities (Grant No. 2021SCU12061).
Author information
Authors and Affiliations
Contributions
Not applicable
Corresponding author
Ethics declarations
Funding
This work is supported by the National Natural Science Foundation of China (Grant No. 61871279 and Grant No. 62081330105) and the Fundamental Research Funds for the Central Universities (Grant No. 2021SCU12061).
Competing interests
No competing interest.
Availability of data and materials
Not applicable.
Code availability
Not applicable.
Ethics approval
Not applicable.
Consent to participate
Yes, I consent to participate.
Consent for publication
Yes, I consent for publication.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Tang, B., He, X., Wu, X. et al. Sequential Enhancement for Compressed Video Using Deep Convolutional Generative Adversarial Network. Neural Process Lett 54, 5351–5370 (2022). https://doi.org/10.1007/s11063-022-10865-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11063-022-10865-y