
Abstract
Long short-term memory (LSTM) networks have been successfully applied to many fields including finance. However, when the input contains multiple variables, a conventional LSTM does not distinguish the contribution of different variables and cannot make full use of the information they transmit. To meet the need for multi-variable modeling of financial sequences, we present an application of multi-variable LSTM (MV-LSTM) network for stock market prediction in this paper. The network consists of two serial modules: the first module is a recurrent layer with MV-LSTM as its recurrent unit, which is able to encode information from each variable exclusively; the second module employs a variable attention mechanism by introducing a latent variable and enables the model to measure the importance of each variable to the target. With these two modules, the model can deal with multi-variable financial sequences more effectively. Moreover, a statistical arbitrage investment strategy is constructed based on the prediction model. Extensive experiments on the large-scale Chinese stock data show that the MV-LSTM network has a higher prediction accuracy and provides a better statistical arbitrage investment strategy than other methods.











Similar content being viewed by others


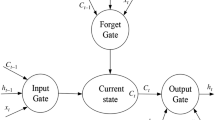
Notes
Vectors are assumed to be in column form in this paper.
References
Avellaneda M, Lee JH (2010) Statistical arbitrage in the US equities market. Quant Financ 10(7):761–782
Gatev E, Goetzmann WN, Rouwenhorst KG (2006) Pairs trading: performance of a relative-value arbitrage rule. Rev Financ Stud 19(3):797–827
Vidyamurthy G (2004) Pairs trading: quantitative methods and analysis, vol 217. Wiley, New York
Huang CF, Hsu CJ, Chen CC, Chang BR, Li CA (2015) An intelligent model for pairs trading using genetic algorithms. Comput Intell Neurosci 2015:939606
Nóbrega JP, Oliveira AL (2014) A combination forecasting model using machine learning and Kalman filter for statistical arbitrage. In: 2014 IEEE International Conference on Systems, Man, and Cybernetics (SMC), pp. 1294–1299. IEEE
Petropoulos A, Chatzis SP, Siakoulis V, Vlachogiannakis N (2017) A stacked generalization system for automated FOREX portfolio trading. Expert Syst Appl 90:290–302
Fischer T, Krauss C (2018) Deep learning with long short-term memory networks for financial market predictions. Eur J Oper Res 270(2):654–669
Guo T, Lin T, Antulov-Fantulin N (2019) Exploring interpretable LSTM neural networks over multi-variable data. In: International conference on machine learning, pp. 2494–2504. PMLR
Cont R (2001) Empirical properties of asset returns: stylized facts and statistical issues. Quant Financ 1:223–236
Chakraborti A, Toke IM, Patriarca M, Abergel F (2011) Econophysics review: I. Empirical facts. Quant Financ 11(7):991–1012
Granger CW (1992) Forecasting stock market prices: lessons for forecasters. Int J Forecast 8(1):3–13
Agrawal J, Chourasia V, Mittra A (2013) State-of-the-art in stock prediction techniques. Int J Adv Res Electr Electr Instrum Eng 2(4):1360–1366
Zhang L, Aggarwal C, Qi GJ (2017) Stock price prediction via discovering multi-frequency trading patterns. In: Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pp. 2141–2149
Ariyo AA, Adewumi AO, Ayo CK (2014) Stock price prediction using the ARIMA model. In: 2014 UKSim-AMSS 16th international conference on computer modelling and simulation, pp. 106–112. IEEE
Alberg D, Shalit H, Yosef R (2008) Estimating stock market volatility using asymmetric GARCH models. Appl Financ Econ 18(15):1201–1208
Pratap A, Raja R, Cao J, Alzabut J, Huang C (2020) Finite-time synchronization criterion of graph theory perspective fractional-order coupled discontinuous neural networks. Adv Diff Equ 2020(1):1–24
Huang C, Liu B, Qian C, Cao J (2021) Stability on positive pseudo almost periodic solutions of HPDCNNs incorporating D operator. Math Comput Simul 190:1150–1163
Wang W (2022) Further results on mean-square exponential input-to-state stability of stochastic delayed Cohen-Grossberg neural networks. Neural Process Lett pp. 1–13
Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z (2016) Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2818–2826
Collobert R, Weston J (2008) A unified architecture for natural language processing: deep neural networks with multitask learning. In: Proceedings of the 25th international conference on machine learning, pp. 160–167
Althelaya KA, El-Alfy ESM, Mohammed S (2018) Evaluation of bidirectional LSTM for short-and long-term stock market prediction. In: 2018 9th international conference on information and communication systems (ICICS), pp. 151–156
Cao J, Li Z, Li J (2019) Financial time series forecasting model based on CEEMDAN and LSTM. Phys A 519:127–139
Chang V, Man X, Xu Q, Hsu CH (2021) Pairs trading on different portfolios based on machine learning. Expert Syst 38(3):e12649
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780
Luong T, Pham H, Manning CD (2015) Effective approaches to attention-based neural machine translation. In: Proceedings of the 2015 conference on empirical methods in natural language processing (EMNLP), pp. 1412–1421
Sak H, Senior A, Beaufays F (2014) Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In: Fifteenth annual conference of the international speech communication association (ISCA), pp. 338–342
Nguyen H, Tran KP, Thomassey S, Hamad M (2021) Forecasting and anomaly detection approaches using LSTM and LSTM autoencoder techniques with the applications in supply chain management. Int J Inf Manage 57:102282
Wang F, Liu X, Deng G, Yu X, Li H, Han Q (2019) Remaining life prediction method for rolling bearing based on the long short-term memory network. Neural Process Lett 50(3):2437–2454
Kumar S, Sharma R, Tsunoda T, Kumarevel T, Sharma A (2021) Forecasting the spread of COVID-19 using LSTM network. BMC Bioinf 22(6):1–9
Choi E, Bahadori MT, Sun J, Kulas J, Schuetz A, Stewart, W (2016) Retain: an interpretable predictive model for healthcare using reverse time attention mechanism. Adv Neural Inf Process Syst (NeurIPS), pp. 3504–3512
Qin Y, Song D, Cheng H, Cheng W, Jiang G, Cottrell GW (2017) A dual-stage attention-based recurrent neural network for time series prediction. In: Proceedings of the 26th international joint conference on artificial intelligence (IJCAI), pp. 2627–2633
Huck N (2009) Pairs selection and outranking: an application to the S &P 100 index. Eur J Oper Res 196(2):819–825
Huck N (2010) Pairs trading and outranking: the multi-step-ahead forecasting case. Eur J Oper Res 207(3):1702–1716
Krauss C, Do XA, Huck N (2017) Deep neural networks, gradient-boosted trees, random forests: statistical arbitrage on the S &P 500. Eur J Oper Res 259(2):689–702
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
Shen G, Tan Q, Zhang H, Zeng P (2018) Deep learning with gated recurrent unit networks for financial sequence predictions. Procedia Comput Sci 131:895–903
Lee SI, Yoo SJ (2018) A new method for portfolio construction using a deep predictive model. In: Proceedings of the 7th international conference on emerging databases, pp. 260–266
Gao Y, Wang R, Zhou E (2021) Stock prediction based on optimized LSTM and GRU models. Scientific Programming 2021
Hu Y (2021) Stock forecast based on optimized LSSVM model. Comput Sci 48(S1):151–157
Cho K, Van Merriënboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, Bengio Y (2014) Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078
Gers FA, Schmidhuber J (2000) Recurrent nets that time and count. In: Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks. Neural Computing: New Challenges and Perspectives for the New Millennium (IJCNN), pp. 189–194
Gers FA, Schmidhuber J, Cummins F (2000) Learning to forget: continual prediction with LSTM. Neural Comput 12(10):2451–2471
Bahdanau D, Cho K, Bengio Y (2015) Neural machine translation by jointly learning to align and translate. In: 3rd international conference on learning representations (ICLR)
Tieleman T, Hinton G (2012) Lecture 6.5-rmsprop: divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw Mach Earn 4(2):26–31
Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R (2014) Dropout: a simple way to prevent neural networks from overfitting. J Mach Learn Res 15(1):1929–1958
Chollet F, et al. (2015) Keras. https://github.com/fchollet/keras
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20(3):273–297
Goodfellow IJ, Warde-Farley D, Mirza M, Courville A, Bengio Y (2013) Maxout networks. In: Proceedings of the 30th international conference on international conference on machine learning (ICML), pp. III–1319
Glorot X, Bengio Y (2010) Understanding the difficulty of training deep feedforward neural networks. In: Proceedings of the thirteenth international conference on artificial intelligence and statistics, pp. 249–256. JMLR Workshop and Conference Proceedings
Kim TK (2015) T test as a parametric statistic. Korean J Anesthesiol 68(6):540
Acknowledgements
This work was supported by the National Natural Science Foundation of China (No. 61976174), the Nature Science Basis Research Program of Shaanxi (No. 2021JQ-055), the Ministry of Education of Humanities and Social Science Project of China (No. 22XJCZH004) and the Scientific Research Project of Shaanxi Provincial Department of Education (No. 22JK0186).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A Evaluation Metrics
Appendix A Evaluation Metrics
Several evaluation metrics used in this paper are defined as follows.
-
(1)
Max drawdown: Max drawdown (MDD) measures the maximum fall in the value of an investment. It is calculated by the difference between the value of the lowest trough and that of the highest peak before the trough, i.e.,
$$\begin{aligned} {\mathrm{MDD}} = \mathop {max}\limits _{0 \le t_1 \le t_2 \le T} \frac{V_{t_1}-V_{t_2}}{V_{t_1}}, \end{aligned}$$where T is the length of trading period, \(V_{t_1}\) and \(V_{t_2}\) are the values of the investment at the time \(t_1\) and \(t_2\), respectively. A low MDD value indicates slight fluctuations in the investment value and, therefore, a low degree of risk, and vice versa.
-
(2)
Sharpe ratio: Sharpe ratio measures the performance of an investment compared to a risk-free asset, after adjusting for its risk. It is defined as the excess return for per unit of risk, i.e.,
$$\begin{aligned} {\mathrm{Sharpe \ ratio}} = \frac{R_p-R_f}{\sigma _p}, \end{aligned}$$where \(R_p\) is the expected return of the investment, \(R_f\) is the risk-free rate, and \(\sigma _p\) is the standard deviation of the investment return. The higher the ratio, the greater the investment return relative to the amount of risk, and thus, the better the investment.
-
(3)
Sortino ratio: Sortino ratio is an improvement of Sharpe ratio. It only considers the downside risk rather than the total risk like Sharpe ratio, since upside risk is beneficial. It is calculated as
$$\begin{aligned} {\mathrm{Sortino\ ratio}} = \frac{R_p-R_f}{\sigma _d}, \end{aligned}$$where \(\sigma _d\) is the standard deviation of the downside risk deviation. Like Sharpe ratio, a higher Sortino ratio indicates a better investment.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Gao, F., Zhang, J., Zhang, C. et al. Long Short-Term Memory Networks with Multiple Variables for Stock Market Prediction. Neural Process Lett 55, 4211–4229 (2023). https://doi.org/10.1007/s11063-022-11037-8
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11063-022-11037-8