
Abstract
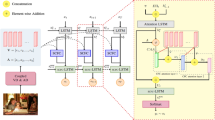
Understanding different semantic concepts, such as objects and their relationships in an image, and integrating them to produce a natural language description is the goal of the image captioning task. Thus, it needs an algorithm to understand the visual content of a given image and translates it into a sequence of output words. In this paper, a local relation network is designed over the objects and image regions which not only discovers the relationship between the object and the image regions but also generates significant context-based features corresponding to every region in the image. Inspired by transformer model, we have employed a multilevel attention comprising of self-attention and guided attention to focus on a given image region and its related image regions, thus enhancing the image representation capability of the proposed method. Finally, a variant of traditional long-short term memory, which uses an attention mechanism, is employed which focuses on relevant contextual information, spatial locations, and deep visual features. With these measures, the proposed model encodes an image in an improved way, which gives the model significant cues and thus leads to improved caption generation. Extensive experiments have been performed on three benchmark datasets: Flickr30k, MSCOCO, and Nocaps. On Flickr30k, the obtained evaluation scores are 31.2 BLEU@4, 23.5 METEOR, 51.5 ROUGE, 65.6 CIDEr and 17.2 SPICE. On MSCOCO, the proposed model has attained 42.4 BLEU@4, 29.4 METEOR, 59.7 ROUGE, 125.7 CIDEr and 23.2 SPICE. The overall CIDEr score on Nocaps dataset achieved by the proposed model is 114.3. The above scores clearly show the superiority of the proposed method over the existing methods.








Similar content being viewed by others


References
Zhu L, Lu X, Cheng Z, Li J, Zhang H (2020) Deep collaborative multi-view hashing for large-scale image search. IEEE Trans Image Process 29:4643–4655
Wu S, Wieland J, Farivar O, Schiller J (2017).Automatic alt-text: computer-generated image descriptions for blind users on a social network service. In: Proceedings of the 2017 ACM conference on computer supported cooperative work and social computing, pp 1180–1192
Das A, Kottur S, Gupta K, Singh A, Yadav D, Moura JM, Batra D (2017) Visual dialog. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 326–335
Beddiar D, Oussalah M, Tapio S (2022) Explainability for medical image captioning. In: 2022 Eleventh international conference on image processing theory, tools and applications (IPTA). IEEE, pp 1–6
Ghataoura D, Ogbonnaya S (2021) Application of image captioning and retrieval to support military decision making. In: 2021 International conference on military communication and information systems (ICMCIS). IEEE, pp 1–8
Castellano G, Digeno V, Sansaro G, Vessio G (2022) Leveraging knowledge graphs and deep learning for automatic art analysis. Knowl-Based Syst 248:108859
Lu Y, Guo C, Dai X, Wang FY (2022) Data-efficient image captioning of fine art paintings via virtual-real semantic alignment training. Neurocomputing 490:163–180
Wang J, Wang W, Wang L, Wang Z, Feng DD, Tan T (2020) Learning visual relationship and context-aware attention for image captioning. Pattern Recogn 98:107075
Li N, Chen Z (2018) Image cationing with visual-semantic LSTM. In: IJCAI, pp 793–799
Li X, Jiang S (2019) Know more say less: image captioning based on scene graphs. IEEE Trans Multim 21(8):2117–2130
Wang Y, Xu N, Liu AA, Li W, Zhang Y (2021) High-order interaction learning for image captioning. IEEE Trans Circuits Syst Video Technol 32(7):4417–4430
Sharma H, Jalal AS (2021) Image captioning improved visual question answering. Multim Tools Appl 81:1–22
Liu AA, Zhai Y, Xu N, Nie W, Li W, Zhang Y (2021) Region-aware image captioning via interaction learning. IEEE Trans Circuits Syst Video Technol 32(6):3685–3696
Chen X, Ma L, Jiang W, Yao J, Liu W (2018) Regularizing rnns for caption generation by reconstructing the past with the present. In: Proceedings of the IEEE Conference on computer vision and pattern recognition, pp 7995–8003
Xu K, Ba J, Kiros R, Cho K, Courville A, Salakhudinov R, Zemel R, Bengio Y (2015) Show, attend and tell: Neural image caption generation with visual attention. In: International conference on machine learning. PMLR, pp 2048–2057
You Q, Jin H, Wang Z, Fang C, Luo J (2016) Image captioning with semantic attention. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4651–4659
Zhou L, Xu C, Koch P, Corso JJ (2017) Watch what you just said: Image captioning with text-conditional attention. In: Proceedings of the on thematic workshops of ACM multimedia, pp 305–313
Anderson P, He X, Buehler C, Teney D, Johnson M, Gould S, Zhang L (2018) Bottom-up and top-down attention for image captioning and visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 6077–6086
Chen L, Zhang H, Xiao J, Nie L, Shao J, Liu W, Chua TS (2017). SCA-CNN: spatial and channel-wise attention in convolutional networks for image captioning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5659–5667
Karpathy A, Fei-Fei L (2015) Deep visual-semantic alignments for generating image descriptions. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3128–3137
Wu J, Hu H (2017) Cascade recurrent neural network for image caption generation. Electron Lett 53(25):1642–1643
He X, Shi B, Bai X, Xia GS, Zhang Z, Dong W (2019) Image caption generation with part of speech guidance. Pattern Recogn Lett 119:229–237
Donahue J, Anne Hendricks L, Guadarrama S, Rohrbach M, Venugopalan S, Saenko K, Darrell T (2015) Long-term recurrent convolutional networks for visual recognition and description. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2625–2634
Kinghorn P, Zhang L, Shao L (2019) A hierarchical and regional deep learning architecture for image description generation. Pattern Recogn Lett 119:77–85
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556
Vinyals O, Toshev A, Bengio S, Erhan D (2016) Show and tell: lessons learned from the 2015 mscoco image captioning challenge. IEEE Trans Pattern Anal Mach Intell 39(4):652–663
Yang X, Xu C (2019) Image captioning by asking questions. ACM Trans Multim Comput Commun Appl (TOMM) 15(2s):1–19
Jia X, Gavves E, Fernando B, Tuytelaars T (2015) Guiding the long-short term memory model for image caption generation. In: Proceedings of the IEEE international conference on computer vision, pp 2407–2415
Gupta N, Jalal AS (2020) Integration of textual cues for fine-grained image captioning using deep CNN and LSTM. Neural Comput Appl 32(24):17899–17908
Kalimuthu M, Mogadala A, Mosbach M, Klakow D (2021) Fusion models for improved image captioning. In: International conference on pattern recognition. Springer, Cham, pp 381–395
Sharma H, Jalal AS (2020) Incorporating external knowledge for image captioning using CNN and LSTM. Mod Phys Lett B 34(28):2050315
Sharma H, Jalal AS (2021) A survey of methods, datasets and evaluation metrics for visual question answering. Image Vis Comput 116:104327
Sharma H, Jalal AS (2022) A framework for visual question answering with the integration of scene-text using PHOCs and fisher vectors. Expert Syst Appl 190:116159
Sharma H, Jalal AS (2021) Visual question answering model based on graph neural network and contextual attention. Image Vis Comput 110:104165
Xiao F, Xue W, Shen Y, Gao X (2022) A new attention-based LSTM for image captioning. Neural Process Lett 54:1–15
Li G, Zhu L, Liu P, Yang Y (2019) Entangled transformer for image captioning. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 8928–8937
Lu J, Xiong C, Parikh D, Socher R (2017) Knowing when to look: adaptive attention via a visual sentinel for image captioning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 375–383
Ye S, Han J, Liu N (2018) Attentive linear transformation for image captioning. IEEE Trans Image Process 27(11):5514–5524
Yang L, Hu H, Xing S, Lu X (2020) Constrained lstm and residual attention for image captioning. ACM Trans Multim Comput Commun Appl TOMM 16(3):1–18
Jiang W, Wang W, Hu H (2021) Bi-directional co-attention network for image captioning. ACM Trans Multim Comput Commun Appl TOMM 17(4):1–20
Yan C, Hao Y, Li L, Yin J, Liu A, Mao Z, Chen Z, Gao X (2021) Task-adaptive attention for image captioning. IEEE Trans Circuits Syst Video Technol 32(1):43–51
Barraco M, Cornia M, Cascianelli S, Baraldi L, Cucchiara R (2022) The unreasonable effectiveness of CLIP features for image captioning: an experimental analysis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 4662–4670
Fang Z, Wang J, Hu X, Liang L, Gan Z, Wang L, Yang Y, Liu Z (2022) Injecting semantic concepts into end-to-end image captioning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 18009–18019
Scarselli F, Gori M, Tsoi AC, Hagenbuchner M, Monfardini G (2008) The graph neural network model. IEEE Trans Neural Netw 20(1):61–80
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I (2017) Attention is all you need. Adv Neural Inf Process Syst 30
Zhang H, Xiao Z, Wang J, Li F, Szczerbicki E (2019) A novel IoT-perceptive human activity recognition (HAR) approach using multihead convolutional attention. IEEE Internet Things J 7(2):1072–1080
Ren S, He K, Girshick R, Sun J (2015) Faster r-cnn: towards real-time object detection with region proposal networks. Adv Neural Inf Process Syst, 28
Zellers R, Yatskar M, Thomson S, Choi Y (2018) Neural motifs: Scene graph parsing with global context. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5831–5840
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778
Xiao Z, Xu X, Xing H, Luo S, Dai P, Zhan D (2021) RTFN: a robust temporal feature network for time series classification. Inf Sci 571:65–86
Jiang S, Yang S (2017) A strength Pareto evolutionary algorithm based on reference direction for multiobjective and many-objective optimization. IEEE Trans Evol Comput 21(3):329–346
Young P, Lai A, Hodosh M, Hockenmaier J (2014) From image descriptions to visual denotations: new similarity metrics for semantic inference over event descriptions. Trans Assoc Comput Linguist 2:67–78
Lin TY, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick CL (2014) Microsoft coco: common objects in context. In: European conference on computer vision. Springer, Cham, pp 740–755
Agrawal H, Desai K, Wang Y, Chen X, Jain R, Johnson M, Batra D, Parikh D, Lee S, Anderson P (2019) Nocaps: Novel object captioning at scale. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 8948–8957
Krasin I, Duerig T, Alldrin N, Ferrari V, Abu-El-Haija S, Kuznetsova A, Rom H, Uijlings J, Popov S, Veit A, Belongie S, Murphy K (2017) Openimages: A public dataset for large-scale multi-label and multi-class image classification, vol 2, no 3, p 18. https://github.com/openimages
Papineni K, Roukos S, Ward T, Zhu WJ (2002) Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pp 311–318
Banerjee S, Lavie A (2005) METEOR: an automatic metric for MT evaluation with improved correlation with human judgments. In: Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pp 65–72
Lin CY (2004) Rouge: a package for automatic evaluation of summaries. In: Text summarization branches out, pp 74–81
Vedantam R, Lawrence Zitnick C, Parikh D (2015) Cider: consensus-based image description evaluation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4566–4575
Anderson P, Fernando B, Johnson M, Gould S (2016) Spice: semantic propositional image caption evaluation. In: European conference on computer vision. Springer, Cham, pp 382–398
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. Adv Neural Inf Process Syst 25:84–90
Krishna R, Zhu Y, Groth O, Johnson J, Hata K, Kravitz J, Chen S, Kalantidis Y, Li LJ, Shamma DA, Bernstein MS, Fei-Fei L (2017) Visual genome: connecting language and vision using crowdsourced dense image annotations. Int J Comput Vis 123(1):32–73
Kingma DP, Ba J (2014) Adam: a method for stochastic optimization. arXiv:1412.6980
Paszke A, Gross S, Chintala S, Chanan G, Yang E, DeVito Z, Lin Z, Desmaison A, Antiga L, Lerer A (2017) Automatic differentiation in pytorch
Hossain MZ, Sohel F, Shiratuddin MF, Laga H (2019) A comprehensive survey of deep learning for image captioning. ACM Comput Surv (CsUR) 51(6):1–36
Zhong Y, Wang L, Chen J, Yu D, Li Y (2020). Comprehensive image captioning via scene graph decomposition. In: European conference on computer vision. Springer, Cham, pp 211–229
Sharma H, Jalal AS (2022) An improved attention and hybrid optimization technique for visual question answering. Neural Process Lett 54(1):709–730
Li X, Yin X, Li C, Zhang P, Hu X, Zhang L, Wang L, Hu H, Dong L, Wei F, Choi Y, Gao J (2020) Oscar: object-semantics aligned pre-training for vision-language tasks. In: European conference on computer vision. Springer, Cham, pp 121–137
Zhang P, Li X, Hu X, Yang J, Zhang L, Wang L, Choi Y, Gao J (2021) Vinvl: revisiting visual representations in vision-language models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 5579–5588
Wang Z, Yu J, Yu AW, Dai Z, Tsvetkov Y, Cao Y (2021) Simvlm: simple visual language model pretraining with weak supervision. arXiv:2108.10904
Hu X, Yin X, Lin K, Zhang L, Gao J, Wang L, Liu Z (2021) Vivo: visual vocabulary pre-training for novel object captioning. In Proceedings of the AAAI conference on artificial intelligence, vol 35, no 2, pp 1575–1583
Cornia M, Stefanini M, Baraldi L, Cucchiara R (2020) Meshed-memory transformer for image captioning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 10578–10587
Anderson P, Fernando B, Johnson M, Gould S (2016) Guided open vocabulary image captioning with constrained beam search. arXiv:1612.00576
Zhou L, Palangi H, Zhang L, Hu H, Corso J, Gao J (2020) Unified vision-language pre-training for image captioning and vqa. In: Proceedings of the AAAI conference on artificial intelligence, vol 34, no 07, pp 13041–13049
Mokady R, Hertz A, Bermano AH (2021) Clipcap: clip prefix for image captioning. arXiv:2111.09734
Kotsiantis SB (2013) Decision trees: a recent overview. Artif Intell Rev 39(4):261–283
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Sharma, H., Srivastava, S. A Framework for Image Captioning Based on Relation Network and Multilevel Attention Mechanism. Neural Process Lett 55, 5693–5715 (2023). https://doi.org/10.1007/s11063-022-11106-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11063-022-11106-y