
Abstract
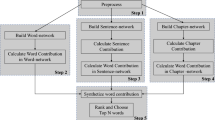
Text keywords are defined as meaningful and important words in a document, which provide a precise overview of its content and reflect the author’s writing intention. Keyword extraction methods have received a lot of attentions, among which is the network-based method. However, existing network-based keyword extraction methods only consider the connections between words in a document, while ignoring the impact of sentences. Since a sentence is made of many words, while words affect one another in a sentence, neglecting the influence of sentences will result in the loss of information. In this paper, we introduce a word network whose nodes represent words in a document, and define that any keyword extraction method based on a word network is called as a Word-net method. Then, we propose a new network model which considers the influence of sentences, and a new word-sentence method based on the new model. Experimental results demonstrate that our method outperforms the Word-net method, the classical term frequency-inverse document frequency (TF-IDF) method, most frequent method and TextRank method. The precision, recall, and F-measure of our result are respectively 7.95, 8.27 and 6.54% higher than the Word-net result, and the average precision of our result is 17.56% higher than the TF-IDF result. A two-way analysis of variance is employed to validate the empirical analysis, which indicates that keyword extraction methods and keyword numbers have statistically significant effects on the evaluation of metric values.









Similar content being viewed by others


References
Abilhoa, W. D., & Castro, L. N. D. (2014). A keyword extraction method from twitter messages represented as graphs. Applied Mathematics and Computation, 240(4), 308–325.
Beliga, S., & Martinčićipšić, S. (2014). Node selectivity as a measure for graph-based keyword extraction in Croatian news. Veterinary Microbiology, 152(3–4), 235–246.
Beliga, S., Meštrović, A., & Martinčić-Ipšić, S. (2015). An overview of graph-based keyword extraction methods and approaches. Journal of Information and Organizational Sciences, 39(1), 1–20.
Brin, S., & Page, L. (1998). The anatomy of a large-scale hypertextual web search engine. Computer Networks, 30, 107–117.
Cancho, R. F. I., & Solé, R. V. (2001). The small world of human language. Proceedings Biological Sciences, 268(1482), 2261.
Carretero-Campos, C., Bernaola-Galván, P., Coronado, A. V., et al. (2013). Improving statistical keyword detection in short texts: Entropic and clustering approaches. Physica A: Statistical Mechanics and Its Applications, 392(6), 1481–1492.
Chen, G., & Xiao, L. (2016). Selecting publication keywords for domain analysis in bibliometrics: A comparison of three methods. Journal of Informetrics, 10(1), 212–223.
Chen, Q., Jiang, Z., & Bian, J. (2014). Chinese keyword extraction using semantically weighted network. In Sixth international conference on intelligent human–machine systems and cybernetics. IEEE Computer Society (pp. 83–86).
Frank, E., Paynter, G. W., Witten, I. H., Gutwin, C., & Nevill-Manning, C. G. (1999). Domain-specific keyphrase extraction. In ACM CIKM international conference on information and knowledge management (Vol. 2, pp. 283–284). Bremen, Germany.
Hasan, K. S., & Ng, V. (2011). Automatic keyphrase extraction: A survey of the state of the art. Meeting of the Association for Computational Linguistics, 2011, 1262–1273.
Hong, B., & Zhen, D. (2012). An extended keyword extraction method. Physics Procedia, 24(24), 1120–1127.
Hu, K., Wu, H., Qi, K., et al. (2017). A domain keyword analysis approach extending term frequency-keyword active index with google Word2Vec model. Scientometrics, 1, 1–38.
Kleinberg, J. M. (1999). Authoritative sources in a hyperlinked environment. Journal of the ACM, 46(5), 604–632.
Kuhn, T., Perc, M., & Helbing, D. (2014). Inheritance patterns in citation networks reveal scientific memes. Social Science Electronic Publishing, 4(4), 041036.
Lahiri, S., Choudhury, S. R., & Caragea, C. (2014). Keyword and keyphrase extraction using centrality measures on collocation networks. Computer Science, 26(1), 1–16.
Lin, G. (2014). A supervised keyphrase extraction method based on the logistic regression model for social question answering sites. Journal of Information and Computational Science, 11(10), 3571–3583.
Lv, L., Chen, D., Ren, X. L., Zhang, Q. M., Zhang, Y. C., & Zhou, T. (2016). Vital nodes identification in complex networks. Physics Reports, 650, 1–63.
Lynn, H. M., Lee, E., Chang, C., Kim, P., Lynn, H. M., Lee, E., et al. (2017). Swiftrank: an unsupervised statistical approach of keyword and salient sentence extraction for individual documents. Procedia Computer Science, 113, 472–477.
Mihalcea, R., & Tarau, P. (2004). TextRank: Bringing order into texts. In Conference on empirical methods in natural language processing (pp. 404–411).
Onan, A., Korukoğlu, V., & Bulut, H. (2016). Ensemble of keyword extraction methods and classifiers in text classification. Expert Systems with Applications, 15(57), 232–247.
Perc, M. (2010). Growth and structure of Slovenia’s scientific collaboration network. Journal of Informetrics, 4, 475–482.
Perc, M. (2013). Self-organization of progress across the century of physics. Scientific Reports, 3(1720), 1720.
Perc, M. (2014). The Matthew effect in empirical data. Journal of the Royal Society, Interface, 11(98), 20140378.
Rose, S., Engel, D., Cramer, N., et al. (2010). Automatic keyword extraction from individual documents. Text Mining: Applications and theory (pp. 1–20). New York: Wiley.
Rossi, R. G., Marcacini, R. M., & Rezende, S. O. (2014). Analysis of domain independent statistical keyword extraction methods for incremental clustering. Learning and Nonlinear Models, 12(1), 17–37.
Salton, Gerard, & Buckley, C. (1988). Term-weighting approaches in automatic text retrieval. Information Processing and Management, 24(5), 513–523.
Siddiqi, S., & Sharan, A. (2015). Keyword and keyphrase extraction techniques: A literature review. International Journal of Computer Applications, 109(2), 18–23.
Sonawane, S. S., & Kulkarni, P. A. (2014). Graph based representation and analysis of text document: A survey of techniques. International Journal of Computer Applications, 96(19), 1–8.
Su, X., Deng, S., & Shen, S. (2014). The design and application value of the Chinese social science citation index. Scientometrics, 98(3), 1567–1582.
Walker, S. K. (2011). Connected: The surprising power of our social networks and how they shape our lives. Journal of Family Theory and Review, 3(3), 220–224.
Wan, X., & Xiao, J. (2008). Single document keyphrase extraction using neighborhood knowledge. In National conference on artificial intelligence (pp. 855–860). AAAI Press.
Wang, X., Wang, L., Li, J., et al. (2012a). Exploring simultaneous keyword and key sentence extraction, improve graph-based ranking using Wikipedia. In ACM international conference on information and knowledge management. ACM (pp. 2619–2622).
Wang, Z. Y., Li, G., Li, C. Y., & Li, A. (2012b). Research on the semantic-based co-word analysis. Scientometrics, 90(3), 855–875.
Witten, I. H., Paynter, G. W., Frank, E., Gutwin, C., & Nevill-Manning, C. G. (1999). KEA: practical automatic keyphrase extraction. In ACM conference on digital libraries. ACM (pp. 254–255).
Yang, Z., Lei, J., Fan, K., et al. (2013). Keyword extraction by entropy difference between the intrinsic and extrinsic mode. Physica A: Statistical Mechanics and Its Applications, 392(19), 4523–4531.
Zanin, M., & Lillo, F. (2013). Modelling the air transport with complex networks: A short review. European Physical Journal Special Topics, 215(1), 5–21.
Zanin, M., Papo, D., Sousa, P. A., et al. (2016). Combining complex networks and data mining: Why and how. Physics Reports, 635, 1–44.
Zhao, P., Cai, Q. S., Wang, Q. Y., et al. (2007). Automatic keyword extraction of Chinese document algorithm based on complex network features. Pattern Recognition and Artificial Intelligence, 20(6), 827–831.
Zhang, K., Xu, H., Tang, J., & Li, J. (2006). Keyword extraction using support vector machine. In International conference on advances in web-age information management (Vol. 47, pp. 85–96). Springer-Verlag.
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Grant No. U1434209), the National Key Research and Development Program of China (Grant No.2017YFB1201105) and the Research Foundation of State Key Laboratory of Railway Traffic Control and Safety (Grant No. RCS2018ZZ003).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Yang, L., Li, K. & Huang, H. A new network model for extracting text keywords. Scientometrics 116, 339–361 (2018). https://doi.org/10.1007/s11192-018-2743-5
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-018-2743-5