
Abstract
Citation function analysis is crucial to understanding how cited literature contributes to the overall discourse and meaning conveyed in scientific publications. Citation functions serve diverse roles that must be accurately identified and categorized. Still, the field of citation function analysis faces challenges due to limited labeled data and the complexity of defining and categorizing citation functions, which require expertise and a deep understanding of scientific literature. This limitation results in imprecise identification and categorization of citation functions, emphasizing the need for further advancements to improve the accuracy and reliability of citation function analysis. This paper proposes GAN-CITE, a novel framework employing semi-supervised learning techniques to address these limitations. Its primary objective is to efficiently leverage available unlabeled data by combining generative adversarial networks (GANs) and the language model to incorporate substantial data representations from unlabeled data sources. Our study demonstrates that GAN-CITE outperforms both supervised and semi-supervised state-of-the-art models in limited data settings, namely 10%, 20%, and 30% of the total labeled data. We also examine its performance in insufficient and imbalanced labeled data situations, as well as the potential of unlabeled data utilization. These findings highlight the success of generative adversarial networks in enhancing citation function classification and their applications in digital libraries that require precise citation function categorization, such as trend analysis and impact quantification, under limited annotated data.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
A scientific paper is a formal document that presents original research, experiments, findings, and analysis within a specific scientific field. It is important to recognize that scientific papers are connected to other documents through two essential elements: references and citations. References serve as acknowledgments or mentions given by one document to another, while citations are the acknowledgments received by a document from others (Narin, 1976). In the realm of scientific publication, citations not only provide valuable insights into the author’s rationale for referencing a particular article (Jan, 2009) but also support the arguments and contributions made by authors throughout a scientific paper. In addition, citation characteristics are defined as the text surrounding a citation mark, which refers to relevant scientific literature (Bornmann & Daniel, 2008). This contextual information offers a valuable opportunity to understand the significant contributions of the cited publication within a scientific paper, as it contains rich semantic information (Abu-Jbara & Radev, 2012). In recent years, numerous researchers have explored the promising field of citation analysis from various perspectives, including areas such as citation sentiment (Yousif et al., 2019), citation recommendation (Färber & Jatowt, 2020), citation function (Teufel et al., 2006), and citation summarization (Qazvinian et al., 2010). These research efforts advance the analysis and applicability of citations in scientific discourse.
Citation function classification is an important task within the field of citation context analysis. It requires determining the significance of cited literature within the citing literature, as well as elucidating the diverse roles and purposes that different citations serve within scientific publications (Moravcsik & Murugesan, 1975). The multifaceted nature of citation functions is influenced by the specific functions for which citations are employed. For instance, one notable hypothesis posits that the structured narrative of scientific papers, comprising sections such as Introduction, Methodology, Results, and Discussion, is reflected in the utilization of citations within these sections. It is considered that citation functions contribute to framing the intended argumentative moves and persuading readers regarding the claims put forth in each section (Jurgens et al., 2018). Another avenue of research focuses on citation intent, which delves into the reasons why authors include particular citations in their work. Understanding citation intent can have significant implications for enhancing research experience, facilitating information retrieval, enabling summarization techniques, and studying the evolution of scientific fields (Cohan et al., 2019).
Additionally, certain studies investigate the practical applications of algorithms in scholarly work, examining how algorithms are utilized or extended in specific ways. An application of this line of work is to identify influential algorithms that significantly impact subsequent algorithmic innovations (Tuarob et al., 2020). These diverse aspects underscore the various ways in which citations are employed to convey meaning and contribute to the broader discourse within scientific papers. Through citation function classification, researchers aim to gain insights and categorize these distinct aspects, shedding light on the nuanced roles that citations play in scholarly communication.
Data scarcity remains a major obstacle in citation function analysis. New citation function definitions and schemes constantly emerge. While training predictive models for these schemes requires massive and accurate labeled data, annotating high-quality examples requires significant time and resources. Further compounding the challenge, the complexity of defining and categorizing citation functions demands expertise and a deep understanding of scientific literature. Consequently, the annotation process heavily relies on experts or researchers with extensive knowledge in reading and interpreting the scientific intent within citation contexts. This limited availability of labeled data hinders the practical applicability of analysis findings. Insufficient data translates into insufficient precision in identifying and categorizing citation usage in scientific papers. Ultimately, inadequate annotated data restricts the broader implications drawn from citation function analysis, hindering the field’s overall progress. Addressing this data scarcity limitation is crucial to enhancing the accuracy and reliability of citation function analysis, ultimately unlocking its full potential in scientific literature.
To address this limitation, this study takes advantage of the considerable amount of unlabeled data accessible within the academic corpus by utilizing it as an additional dataset to guide the model’s learning. One crucial approach that incorporates unlabeled data as an integral part of the training process is known as semi-supervised learning. Semi-supervised learning techniques encompass machine learning methodologies that combine labeled and unlabeled data as essential characteristics during model training (Zhu, 2005). For instance, a widely recognized baseline method for semi-supervised learning is self-training, a technique that is used to learn a classifier iteratively by assigning pseudo-labels to the set of unlabeled training samples with a margin greater than a certain threshold. The pseudo-labeled examples are then used to enrich the labeled training data and to train a new classifier in conjunction with the labeled training set. Self-training leverages the model’s predictions to generate additional labeled data and improve its performance on the target task (Amini et al., 2022). Another approach involves utilizing generative models to learn the joint distribution of the input features and the corresponding labels. These models learn to generate realistic samples from the data distribution, which can be used to augment the labeled dataset. By leveraging the generative model to produce additional labeled data, the model can learn more effectively and improve its performance on the target task (Kingma et al., 2014). Numerous other techniques exist within the realm of semi-supervised learning, each offering unique advantages in addressing the challenges posed by limited labeled data.
Furthermore, numerous studies have underscored the significance of employing semi-supervised learning techniques in various citation analysis tasks. For instance, in the context of citation identification, where the goal is to identify significant citations, the semi-supervised self-training technique has successfully been applied to overcome the challenge of the limited availability of manually annotated data (An et al., 2022). Similarly, in the domain of citation screening, which aims to streamline the process in clinical and public health reviews, a semi-supervised active learning method has been utilized to improve classification performance (Kontonatsios et al., 2017). These noteworthy findings emphasize the value of integrating semi-supervised learning approaches to improve predictive models for citation analysis, offering promising avenues for further advancements in the field.
In contrast to these previous works, our research introduces GAN-CITE, a novel framework specifically designed for automatic classification tasks in citation function analysis under conditions of limited annotated data. Unlike traditional approaches that primarily rely on self-training or simple augmentation methods, GAN-CITE leverages generative adversarial networks (GANs) not only to generate synthetic examples but also to learn more comprehensive data distributions from both labeled and unlabeled data. This process enables the model to create detailed vector representations, thereby enhancing the clarity of decision boundaries in classification tasks. The framework begins with the data collection process, where citation contexts are gathered from databases such as Semantic Scholar (Lo et al., 2020) and CiteSeerX (Wu et al., 2018). These databases serve as sources for both labeled and unlabeled data. Notably, the unlabeled data plays a crucial role in the subsequent training process. To leverage the potential of unlabeled data, a GAN-BERT-based model is employed, representing the state-of-the-art generative model for semi-supervised learning in natural language processing (Croce et al., 2020). This model has demonstrated remarkable success in addressing various challenges posed by limited labeled data in the medical domain. Examples include sentiment analysis of drug reviews (Colón-Ruiz, 2021), classifying patients with implants based on medical histories (Danielsson et al., 2022), and representing patient data from electronic health records in the context of few-shot learning (Poulain et al., 2022).
The primary objective of this framework is to indicate the efficiency of integrating unlabeled data, in conjunction with advanced semi-supervised learning methods, to improve the performance of the classification task in citation functions analysis, particularly when working with small labeled datasets. To the best of our knowledge, we are the first to pioneer utilizing GAN-BERT to tackle the issue of limited annotated data in digital libraries and scientometrics.
This paper contributes to the field of citation function analysis by presenting several key contributions:
-
We found that one of the causes of unacceptable prediction accuracy in citation function classification was the lack of labeled citation contexts and investigated the use of abundantly available unlabeled citation contexts to tackle this challenging problem. An unlabeled citation context is a citation context (text surrounding a citation marker within a scholarly document) that remains unannotated into its corresponding citation function because labeling this kind of data can be resource-consuming and requires specialized knowledge. Using semi-supervised learning methods, we showed that these unlabeled contexts can be utilized to improve the classification task, thereby minimizing the need for extensive manual annotation.
-
We proposed GAN-CITE, a novel framework specifically designed to overcome the limitations of labeled data scarcity in automatic citation function classification. GAN-CITE leverages SciBERT (Beltagy et al., 2019), a pre-trained language model for scientific text, as its backbone classifier. The framework integrates various interconnected modules for data acquisition, pre-processing, model training with GAN-BERT, and systematic evaluation of different configurations. For research purposes, we provide the source code at github.com/krittintey/gan-cite.
-
We conducted comprehensive empirical evaluations on several citation function datasets. We employed the fine-tuned SciBERT and SPECTER models as the supervised learning baselines, as well as self-training and label propagation as the semi-supervised learning baselines. Furthermore, we explored various configurations of the best-performing models to identify the optimal setup for real-world applications.
Background and related work
The relevant literature is divided into two parts to effectively address the research objective, which revolves around comprehending the potential enhancement of citation function analysis in small annotated datasets by utilizing unlabeled data. Firstly, we look into the literature pertaining to citation functions analysis, describing the existing body of knowledge in this domain. Subsequently, we explore prior studies that have employed generative adversarial networks (GANs) and semi-supervised learning techniques for citation function analysis.
Citation function analysis
Citation analysis encompasses a broad field within bibliometrics that investigates the citations made to and from scholarly documents. This area employs diverse techniques, including citation counts, to examine scholarly influence and patterns. Unlike traditional database searches based on author or subject, citation searching traces the instances where works such as articles, books, and conference proceedings have been referenced by other authors. One of the most prominent topics within this extensive domain is citation function analysis, which involves identifying and analyzing the purpose or role of a citation within a scholarly article. By examining citation functions, researchers can gain insights into how authors utilize existing research to bolster their own arguments and comprehend the interconnectedness of various fields of study through shared references.
Citation function analysis entails classifying citation roles based on their contexts within the scientific literature, employing various supervised learning methods. Several studies have contributed to this field by providing novel definitions of citation roles and introducing new classification methodologies. Zhao et al. (2019) introduced a novel task focused on understanding online resource citations and proposed a multi-task model to classify citation roles within their manually labeled dataset, SciRes, which includes six categories: Use, Product, Introduce, Extend, Compare, and Other. Their model achieved a macro-averaged F1-score of 0.715. Similarly, Cohan et al. (2019) developed the SciCite dataset to provide a more comprehensive representation of citation intents across different domains compared to existing datasets. The SciCite dataset categorizes citations into three primary intents: Background, Method, and Result comparison. They proposed a multi-task model incorporating structural information from scientific papers, with the BiLSTM-Attn using ELMo, achieving a macro-averaged F1-score of 0.84.
Focusing specifically on algorithms in scientific literature, Tuarob et al. (2020) proposed an automated method for analyzing algorithm usage through citation contexts. They introduced two schemes, UTILIZATION and USAGE, to classify algorithm functions. The proposed approach utilizes heterogeneous ensemble methods and achieves average F1 scores of 0.502 and 0.639 for positive classes in the fine-grained USAGE and binary UTILIZATION schemes, respectively. While their novelty lies in using citation contexts to identify how previously proposed algorithms are used in the citing papers, the classification accuracy must be improved before utilizing the proposed predictive models on a larger scale. Zhang et al. (2022) highlighted the significance of native information features in neural text representation models for citation function classification. They created the NI-Cite dataset with labeled citations incorporating five key features (Citation Context, Section Name, Title, DOI, Web URL) and assessed performance using advanced text representation models. Recently, Jiang and Chen (2023) addressed challenges in citation analysis by developing advanced deep-learning models using SciBERT and creating a robust dataset. Their research achieved state-of-the-art results while emphasizing the importance of context in citation function classification and the potential benefits of ensemble methods for enhancing performance. Lastly, Ma et al. (2025) presented a novel approach to citation recommendation by integrating argumentative zoning of citing sentences to enhance the relevance of recommended citations in scientific literature. Their study constructed a labeled corpus from PubMed by annotating citing sentences based on rhetorical functions and employed a multi-task learning model that simultaneously conducts citation recommendation and query classification. The results indicated that considering argumentative information improved citation recommendation system performance while underscoring the importance of understanding citation intent and leveraging argumentative features in natural language processing tasks.
The above-reviewed studies investigated the citation function analysis in various aspects. While several studies showed promising evaluation results on their corresponding datasets, proposed approaches in this direction have faced some limitations. First, many studies, particularly those that attempt to present novel definitions of citation functions, face a scarcity of labeled data. This limitation makes it challenging to achieve a balanced distribution of annotated contexts across different categories, as illustrated in Table 1. Also, the diverse formats and writing styles followed by different venues and authors in scientific literature further compound this issue, exacerbating the dataset’s imbalance and leading to sub-optimal classification performance. These issues inherently prevent the proposed approaches from being adopted in practical analyses.
Traditional methods for tackling the limited labeled data problem involve time-consuming and resource-intensive manual annotation of additional data. Alternatively, some studies have explored various approaches, such as the joint semantic representation model proposed by Qi et al. (2023), which integrates pre-trained language models and heterogeneous features of citation intent texts. This model considers the correlation between citation intents, citation sections, and citation-worthiness classification tasks. It builds a multi-task citation classification framework with a soft parameter-sharing constraint and constructs independent models for multiple tasks to improve citation intent classification performance. However, in this paper, we present an alternative approach that utilizes unlabeled citation contexts, which can be easily extracted from a vast pool of scientific literature. Additionally, incorporating unlabeled data using semi-supervised learning methods offers a promising solution to enhance classification performance by enabling the model to discover patterns unseen in the annotated data while efficiently and scalably exploiting the abundance of unlabeled data.
Generative adversarial networks in semi-supervised learning
Generative adversarial networks, introduced by Goodfellow et al. (2014), are a pioneering approach to generative modeling within the field of machine learning. A GAN consists of two neural networks, a generator and a discriminator, which engage in an adversarial training process. The generator aims to produce synthetic data that closely resembles real data, while the discriminator attempts to distinguish between real and generated samples. This adversarial dynamic drives both networks to improve iteratively: the generator learns to create increasingly realistic data. At the same time, the discriminator becomes more adept at detecting subtle differences between real and fake samples. The training process continues until an equilibrium is reached, at which point the generated samples are indistinguishable from real data. GANs have demonstrated remarkable success in various domains, such as image synthesis, style transfer, and data augmentation. Their ability to learn complex data distributions without explicit probability density estimation has made them a cornerstone of modern generative modeling, with applications spanning computer vision, natural language processing, time series forecasting, etc. (Aggarwal et al., 2021; Vuletić et al., 2024).
Generative adversarial networks (GANs) have emerged as a powerful tool in semi-supervised learning, offering innovative solutions to challenges such as limited labeled data and class imbalance. Salimans et al. (2016) pioneered the integration of GANs into semi-supervised learning, demonstrating significant improvements in classification accuracy with minimal labeled data. Their approach leverages the discriminator’s ability to learn meaningful feature representations from both labeled and unlabeled samples. The impact of this approach extends beyond computer vision: in the field of natural language processing (NLP), Croce et al. (2020) have adapted the concept to improve general text classification tasks with limited labeled examples by synergistically combining the power of the pre-trained language model BERT (Devlin et al., 2019) and the Semi-Supervised Generative Adversarial Network (SS-GAN) framework and achieved good performance in various sentence classification tasks with as few as 50–100 labeled examples, outperforming traditional BERT models in these low-resource scenarios.
Semi-supervised learning in citation content analysis
Due to the common challenge of limited labeled data in training accurate models in citation analysis tasks, the application of semi-supervised learning is of significant importance in this field. Semi-supervised learning techniques offer a valuable approach to leveraging the abundance of unlabeled data to improve the performance of citation analysis models. Specifically, such techniques have been extensively employed in various citation analysis tasks, including identifying and screening relevant citations.
Kontonatsios et al. (2017) proposed a new semi-supervised active learning method to improve citation screening in clinical and public health reviews. The method uses both labeled and unlabeled citations to enhance classification performance during the early stages of active learning. The authors found that a low-dimensional spectral embedded feature space was more effective in addressing the high terminological variation in public health reviews compared to the traditional bag-of-words representation. The experiments conducted across two clinical and four public health reviews showed that their method outperformed two existing state-of-the-art active learning methods when only a limited number of labeled instances were available for training. Setio and Tsuchiya (2022) proposed a semiautomatic approach to generate a large dataset of citation functions. This method involves training machine learning models on manually labeled data and then utilizing these models to label unlabeled instances. The approach consists of two development stages. The authors develop two classification tasks during the first stage: filtering and fine-grained classification. The filtering task aims to eliminate nonessential labels, while the fine-grained task categorizes the details of the essential labels. The experimental results have demonstrated that BERT and SciBERT, when applied with active learning (AL) on less than half of the training data, yielded higher accuracies than other methods in the classification tasks. Jiang et al. (2022) discussed the evolution of citation function classification, starting from rule-based approaches to more sophisticated deep learning models. Early studies focused on manual rule creation and feature engineering, while recent advancements leverage deep learning techniques like SciBERT for improved performance. The authors emphasized the importance of contextualized citation modeling and the need to encode citations within their surrounding text for proper classification. By combining multiple datasets and designing deep learning models based on SciBERT, the researchers achieved impressive results, particularly in capturing minority classes like modifications of cited work. Recently, An et al. (2022) discussed a semi-supervised self-training technique for identifying important citations. They pointed out that while several methods have been proposed for this task, only a small amount of data has been manually labeled. Therefore, they employed the semi-supervised self-training technique to leverage unlabeled data and improve learning performance. Their study highlighted the statistics on labeled and unlabeled data, experimented with Support Vector Machine (SVM) and Random Forest (RF) models, and proposed a framework for important citation identification. The authors concluded that the semi-supervised self-training method was preferable for identifying important citations due to its flexibility in threshold setting and model selection. Adopting their idea, we also experimented with the self-training method as a semi-supervised learning baseline in our research. Moreover, Zhang et al. (2023) introduced a two-stage HybridDA model that combines GPT-2 data argumentation and retrieval to generate high-quality annotated citation function data. Their model aims to tackle both the issues of data imbalance and data sparsity. They conduct experiments in both imbalance settings and low-resource settings, using their proposed approach. The results showed that their model achieved competitive performance compared to other baseline models in both scenarios.
Despite the widespread application of semi-supervised learning in various citation analysis tasks, our study reveals persistent challenges related to small labeled datasets and imbalanced data within the citation function analysis domain. Several studies have demonstrated the advantages of using GANs in semi-supervised learning to improve feature representation and mitigate the effects of imbalanced data without the need for extensive pre-processing stages prior to training. Surprisingly, no existing studies have utilized GANs in semi-supervised learning to address these issues in the citation analysis domain. Therefore, we propose a GAN-based novel framework that employs semi-supervised learning methods to enhance classification performance in scenarios involving limited labeled data and to mitigate the adverse effects of imbalanced data. By leveraging the untapped potential of unlabeled data, our approach aims to alleviate the limitations associated with small labeled and imbalanced datasets. This methodology paves the way for more effective and accurate approaches to training predictive models for citation function analysis.
Methodology
This section introduces the proposed method and provides detailed case studies on citation function analysis, elucidating the rationale behind selecting the GAN-BERT-based model within our proposed framework. We begin by describing our data preparation and preprocessing steps, which are crucial for ensuring the quality and consistency of our input data. Subsequently, we detail our classification model selection process, outlining the criteria and considerations that led to our final model architecture. We then provide a comprehensive evaluation strategy, designed to rigorously assess the performance and robustness of our approach. Furthermore, each module of the framework is extensively examined and discussed, offering a comprehensive understanding of the entire process.
Classification model selection
To thoroughly evaluate the performance of our method in the citation function classification task, this research involves the preparation of candidate classification models categorized into two types of learning approaches. The first approach, supervised learning, relies solely on labeled data for model training. In this study, we employ two state-of-the-art baseline models for supervised learning:
-
1.
Fine-tuned SciBERT (FT-SciBERT): A pre-trained language model specifically crafted for scientific literature and further refined through fine-tuning (Beltagy et al., 2019).
-
2.
SPECTER: A pre-trained language model trained on document-level relatedness signals, particularly the citation graph, to capture inter-document relationships (Cohan et al., 2020).
While large language models (LLMs) exhibit impressive capabilities across various tasks, they were not included as state-of-the-art baselines in this study due to their generalization limitations in specialized applications like citation function classification. LLMs often require extensive fine-tuning on domain-specific data to perform well. Without this customization, they may fail to capture the specific nuances of citation contexts. Consequently, we opted for FT-SciBERT and SPECTER, which are better suited to the unique requirements of our task.
The second approach, semi-supervised learning, leverages both labeled and unlabeled data during the training process. For this category, we implemented three models:
-
1.
Self-Training with SciBERT: This serves as a baseline model for semi-supervised learning. It iteratively uses SciBERT to classify unlabeled data, adds high-confidence predictions to the labeled dataset, and retrains the model. This process continues until a stopping criterion is met, allowing the model to leverage unlabeled data to improve its performance (Amini et al., 2022).
-
2.
Label Propagation with SciBERT: As another baseline method, this approach first trains a label propagation algorithm on the labeled data. It then uses this algorithm to assign labels to the unlabeled data. Finally, all labeled data (original and newly labeled) are used to fine-tune SciBERT, effectively utilizing the entire dataset (Zhu & Ghahramani, 2002).
-
3.
GAN-CITE: This is our proposed semi-supervised learning method that integrates the GAN architecture with SciBERT for training citation function classification models.
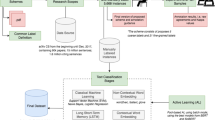
Our proposed method, the GAN-CITE semi-supervised framework, illustrated in Fig. 1, is designed for training citation function classification models. Leveraging the principles of semi-supervised learning, the GAN-BERT-based model (Croce et al., 2020), which combines techniques from GANs (Creswell et al., 2017) and the BERT-based model (Devlin et al., 2019), is employed to train the classification model using both the labeled and unlabeled data. In the context of citation function analysis, the proposed framework utilizes the SciBERT (Beltagy et al., 2019), a pre-trained language model specialized for scientific documents, as part of the BERT-based model for better understanding of scientific literature. In addition, both the Generator and Discriminator use multi-layer dense networks to support embedding from SciBERT. This model has been specifically selected for its ability to effectively handle the challenges posed by limited labeled data. Finally, the trained model is thoroughly evaluated to assess its performance and suitability for further applications. The evaluation stage serves as a critical checkpoint to ensure that the model exhibits sufficient performance levels, warranting its application in subsequent stages or research endeavors.

High-level methodology of the proposed GAN-CITE framework
Within a formal setting from GAN-BERT (Croce et al., 2020), the framework entails the collaboration of the discriminator (D) and generator (G) in the pursuit of training a semi-supervised classifier. In addition, this framework leverages the specialized capabilities of SciBERT and is tailored to the scientific literature domain. Initially, \(p_{\rm m}(\hat{y} = y|x; y \in (1,..., k))\) is defined as the probability assigned by model m to an input example x, previously embedded via SciBERT, belonging to one of the k target classes. Additionally, \(p_{\rm m}(\hat{y} = y|x; y = k + 1)\) denotes the probability of x representing synthetic data. Furthermore, \(P_{\rm D}\) and \(P_{\rm G}\) represent the distributions of genuine and generated data, respectively. The loss function of the discriminator is defined as follows:
\(L_{D_{sup}}\) measures the discrepancy resulting from misassigning an authentic instance to an inappropriate category within the initial k classes. Conversely, \(L_{D_{\rm unsup}}\) assesses the discrepancy arising from misinterpreting an unlabeled genuine example as synthetic and from overlooking the authenticity of a generated instance.
For the generator, the loss function is defined as:
\(L_{\text{G}_{\rm unsup}}\) penalizes the generator when the discriminator accurately identifies synthetic examples. In \(L_{\text{G}_{\rm feature}}\), f(x) represents the activation within an intermediary layer of the discriminator. \(L_{\text{G}_{\rm feature}}\) quantifies the statistical disparity between the internal representations of authentic data and those of generated data.
In the SciBERT framework, labeled and unlabeled documents are first processed by extracting the representation of each document from the output at the token [CLS]. While training, SciBERT is updated using the discriminator loss \(L_{\rm D}\) (as shown in Eq. 1) with both labeled and unlabeled documents. In the GAN-CITE framework, unlabeled documents are utilized to train the discriminator to distinguish real and fake data and to facilitate backpropagation, allowing the language model to learn data distributions from both labeled and unlabeled data. This process aids in generating comprehensive vector representations and enhancing the clarity of decision boundaries in classification tasks.
For classification, in the context of this research, let X and Y be the sets of input data and target variables, respectively. X represents the collection of citation contexts from the scientific literature. Y corresponds to the set of citation functions, which are categorized based on the target aspects, as exemplified in Table 1. To improve the performance of the classification task using semi-supervised learning, the mathematical equation governing the process can be formulated as follows:
In this equation, P(Y|X) is the probability distribution across citation functions Y with respect to the input data X. The softmax function generates output probabilities, applied element-wise to the output vector, establishing the probability distribution across citation functions. These probabilities indicate the degree of confidence regarding each citation function’s association with categories defined within Y, considering the input data X and the contextualized representation derived from SciBERT. Here, W represents the weight matrix of the classifier, \(h_{\rm SciBERT}\) signifies the output representation from SciBERT corresponding to input X, and b denotes the bias vector.
The proposed classification model aims to improve the ability to capture the contextual relevance of generated scientific text data, potentially leading to better citation function classification performance than the baseline models. By comparing the performance of the newly developed models with the baseline models, the efficacy and potential advantages of the model in addressing the challenges of citation function analysis can be validated.
Experiment and results analysis
Evaluating the proposed framework in a real-case study is crucial to assessing its effectiveness and practicality. This section begins by presenting the datasets’ statistics, specifically focusing on the algorithm citation function analysis conducted in this research. The characteristics of both the labeled and unlabeled data are then briefly discussed, providing insights into their composition and relevance for validating the classification models. Furthermore, a comprehensive analysis is conducted to evaluate the best classification model. Various factors are considered, including the sizes of labeled and unlabeled data, to understand their impact on the performance of the classification models. All the experiments were conducted on a Linux machine with a 32-core CPU (64 threads), 256 GB of RAM, and an RTX 3090 graphic card.
Case studies
For our experiments, we utilized both labeled and unlabeled datasets. The labeled datasets include the ACL-ARC dataset (Jurgens et al., 2018), the SciCite dataset (Cohan et al., 2019), and an algorithm citation function dataset (Tuarob et al., 2020), which serve as representative examples of various downstream applications in citation function analysis. Specifically, we chose these specific datasets for several reasons.
First, each dataset encompasses a diverse range of citation functions and contexts, allowing for a comprehensive evaluation of our classification methods across different scenarios. The ACL-ARC dataset is particularly valuable due to its focus on annotation quality within computational linguistics, while the SciCite dataset provides insights into the structural aspects of citations in scientific literature. Additionally, the algorithmic citations functions dataset offers targeted examples related to algorithm citations, ensuring that our experiments include specific patterns relevant to our framework.
Furthermore, these datasets are widely recognized within the research community, enabling us to benchmark our results against established standards and facilitate comparability with previous studies. Their varied characteristics also help to test the robustness of our proposed method across distinct citation types and formats, ultimately contributing to a more thorough assessment of its effectiveness in citation function classification tasks.
Dataset preprocessing and statistics
The classification of citation functions poses significant challenges, even for experts, due to the similarities among certain classes that lead to common classification errors. This indicates that traditional automatic citation function classification methods still lack the necessary capabilities to fully comprehend the patterns of citation usage associated with specific functions. To address this issue, our proposed method integrates generative and text-understanding models while leveraging large volumes of unlabeled data. The generative model facilitates learning the characteristics of citation contexts, whereas the embedding model captures unique features to accurately differentiate these characteristics, thereby enhancing classification accuracy. Consequently, the innovation of our approach lies in tackling the insufficient data problem in citation function analysis, distinguishing our work from conventional automatic citation function classification tasks.
To prepare the unlabeled citation contexts for experimentation, we applied data pre-processing techniques to scientific literature retrieved from several scholarly corpora, including the ACL Anthology Reference Corpus (Bird et al., 2008), Semantic Scholar corpus (Lo et al., 2020), and CiteseerX repository (Wu et al., 2018). This process involves removing contexts containing excessive meaningless special symbols and manually filtering out noisy citation contexts that are difficult to read or interpret due to inaccuracies during extraction from scientific documents. Algorithm 1 outlines the pseudo-code for extracting citation contexts from scientific documents. The input P is a PDF file processed to extract its textual content, denoted as T, with any special symbols removed. The text is then segmented into a sequence of sentences S. The algorithm iterates through these sentences, where n denotes the total number of sentences, and checks whether each contains a citation marker. If a sentence includes a citation marker, the algorithm constructs the citation context by concatenating the previous, current, and subsequent sentences. In cases where a sentence containing a citation is either the first or last in the document, previous or subsequent sentences are represented by \(\epsilon\), indicating an empty string. Leading and trailing whitespaces are removed from each constructed citation context, denoted as c, before appending it to the output list. The algorithm concludes by returning the complete list of citation contexts denoted as \(\mathcal {C}.\)

Extracting citation contexts from a PDF document
Table 2 illustrates class distribution across each dataset. To complement these labeled datasets, unlabeled data were prepared by randomly selecting samples from their original sources. For instance, unlabeled data for the ACL-ARC dataset were obtained from the ACL Anthology Reference Corpus (Bird et al., 2008). Unlabeled data for SciCite were sourced from Semantic Scholar corpus (Lo et al., 2020) while the data for algorithmic citations were collected from CiteseerX repository (Wu et al., 2018). Figure 2 depicts the distribution of publication years for selected documents used to sample unlabeled citation contexts; this range extends from 1940 to 2013, with most documents published between 1995 and 2000.
Additionally, Table 3 provides an overview of properties of unlabeled datasets for each category within this study, including size metrics such as average sentence counts and average word counts. These unlabeled datasets were carefully chosen to ensure diverse representation across various temporal spans, document types, fields of study, and publication venues. By integrating such rich and varied datasets into our research framework, we aim to capture both intricacies and nuances inherent in citation functions within scholarly discourse.

Distribution of publication years of the documents in our unlabeled dataset
Classification model evaluation
In the context of citation function analysis, where each citation must first be classified according to its function, the evaluation of classification models employs standard metrics such as precision, recall, and F1 score. These metrics provide a comprehensive assessment of the model’s performance by measuring its ability to correctly classify instances of different citation functions. This analysis aims to identify the reasons and advantages contributing to the best model’s superiority over the baseline models. Factors such as model architecture, utilization of labeled and unlabeled data, and specific techniques employed within the model are scrutinized. By examining these aspects, the research aims to uncover the strengths and distinguishing features of the best mode and demonstrateg why it outperforms the baseline models.
Experimental results of classification model selection
This section focuses on identifying the best-performing model under realistic constraints of limited labeled data. We employed subsets of our labeled data to simulate real-world scenarios where acquiring large annotated datasets can be challenging. Specifically, we used randomly sampled datasets containing 10%, 20%, and 30% of the total data, reflecting typical data availability in practical settings. This approach aligns with the evaluation protocol used for GAN-BERT (Croce et al., 2020). Each model was trained on reduced datasets and evaluated using class performance metrics. To ensure robustness and minimize potential biases, we randomly divided the labeled data into three sets. For each set, the data was partitioned into training, validation, and testing subsets in a ratio of 6:2:2. Evaluation of the model was conducted within each set. Finally, we averaged the evaluation metrics across all sets to obtain reliable performance assessments.
The model configurations are as follows: FT-SciBERT employed four epochs, a batch size of 32, and a learning rate of 1e−5. The SPECTER model utilized identical settings to FT-SciBERT, maintaining consistency with four epochs, a batch size of 32, and a learning rate of 1e−5. The Self-Training model was trained for three epochs, a batch size of 32, and a learning rate of 5e−5. Finally, the proposed GAN-CITE model was trained for ten epochs, with a batch size of 32 and a learning rate of 2e−5.
Tables 4 and 5 summarize the classification performance of all candidate models under various small labeled data settings across different citation function datasets. The results demonstrate that GAN-CITE consistently outperforms other classification models in terms of F1 score across most settings. When compared to the baseline model, FT-SciBERT, GAN-CITE exhibits improvements in F1 scores, summarized as follows:
-
1.
For the algorithm citation function dataset in the UTILIZATION scheme:
-
0.80%, 6.54%, and 4.85% increase for 10%, 20%, and 30% labeled data settings, respectively.
-
-
2.
For the algorithm citation function dataset in the USAGE scheme:
-
23.01%, 15.97%, and 11.41% increase for 10%, 20%, and 30% labeled data settings, respectively.
-
-
3.
For the ACL-ARC dataset:
-
82.99%, 2.19%, and 32.53% increase for 10%, 20%, and 30% labeled data settings, respectively.
-
-
4.
For the SciCite dataset:
-
1.18% and 0.48% increase for 20% and 30% labeled data settings, respectively.
-
Additionally, we have calculated the average F1 scores across all labeled data for a direct comparison of model performance. These results underscore the effectiveness of the GAN-CITE model, particularly in scenarios with limited labeled data. The model’s performance improvements are most pronounced in the ACL-ARC and algorithm citation function datasets, especially in the USAGE scheme, suggesting its robustness across different citation function classification tasks.
Furthermore, Table 6 showcases an additional experiment comparing GAN-CITE’s performance against traditional imbalanced data handling techniques, including upsampling and downsampling. This experiment aimed to demonstrate GAN-CITE’s ability to mitigate class imbalance without relying on these methods. Interestingly, the results reveal that when using 20% and 30% of the data, the original imbalanced dataset with GAN-CITE outperforms settings that employ traditional balancing techniques.
Such an outcome could be due to several factors. Traditional sampling methods that equalize class sizes (upsampling/downsampling) can distort the original data distribution. Such deviation creates a mismatch between the training data (artificially balanced) and the unlabeled data (which likely maintains the original imbalance). This misalignment might lead to suboptimal performance. In contrast, GAN-CITE leverages the original, imbalanced data, potentially allowing it to learn from the true underlying distribution. This, combined with its semi-supervised learning and generative capabilities, might contribute to more robust and generalizable performance.
These findings highlight GAN-CITE’s potential for tackling two challenges simultaneously: limited labeled data and class imbalance. This suggests that the model’s architecture can address class imbalance issues inherently, potentially through its ability to generate synthetic examples or learn more robust representations from limited data.
Impact of the sizes of labeled data classification performance
The previous experiment involved using 10%, 20%, and 30% of the total labeled data while varying the classification models. The best model, GAN-CITE, was selected based on its highest F1 score compared to the baseline models. In addition, the algorithm citation function dataset was chosen as the case study because it encompasses two classification schemes, binary class and multi-class, which are essential for these analyses. The experiment protocol in this section was inspired by Croce et al. (2020), who varied the labeled data settings from one to 50 (i.e., \(l\in \{1, 2, 5, 10, 20, 30, 40, 50\}\)) percents to assess the model’s performance at different levels of labeled data’s availability. The experiment protocol was the same as in the previous section to ensure the consistency of the classification results.
Figure 3 presents the results of applying the classification models to the varied settings of labeled data for both the UTILIZATION and USAGE schemes. The figure illustrates that GAN-CITE consistently outperforms most of the settings for both schemes. The trends of the results, represented by the logarithmic functions on the results line, demonstrate the superior performance of GAN-CITE. However, it is worth noting that there is a slight deviation where self-training performs comparatively better for the first range of labeled data in the USAGE scheme. This performance difference could suggest that specific characteristics in the labeled data settings enable self-training to create more accurate pseudo-labels.

Visualization of F1 scores from the classification models with varying settings of labeled data in the UTILIZATION and USAGE schemes. Log denotes the corresponding logarithmic trend line
Additionally, Fig. 4 presents a quantitative comparison of model performance by contrasting GAN-CITE, the top-performing model with FT-SciBERT, the best baseline model for supervised learning, and the Self-Training, the best baseline model for semi-supervised learning. This model selection for comparison was based on the average F1 scores obtained from Table 5 and Table 4. The performance gap was calculated as the absolute difference between the F1 scores of the two models, scaled to a range of 0% to 100%. The figure demonstrates a decreasing trend represented by the linear functions on the performance gap as more labeled data is used. The experimental results demonstrate that GAN-CITE outperforms the baseline FT-SciBERT regarding F1 scores when labeled data is limited, indicating its suitability for scenarios with scarce labeled data. As the amount of labeled data increases, both GAN-CITE and FT-SciBERT converge in their F1 scores, reducing the gap between them. Unlike Self-Training, the gap between GAN-CITE’s F1 scores and its own scores remains consistent across different data quantities, showcasing GAN-CITE’s robustness. In the context of Self-Training, the reason for its subpar performance to FT-SciBERT and GAN-CITE, even when trained with SciBERT, can be attributed to its inability to learn sufficiently from a limited amount of labeled data to accurately pseudo-label the unlabeled data. This contamination in the auxiliary training data during subsequent rounds hinders the overall performance of the self-training approach. Consequently, GAN-CITE can be inferred as the more adept and preferable approach compared to baseline techniques, particularly in contexts characterized by sparse labeling.

Visualization of performance gap from supervised learning baseline (FT-SciBERT) and best model (GAN-CITE) and performance gap from semi-supervised learning baseline (Self-Training) and best model (GAN-CITE) with varying labeled data amounts. Linear denotes the corresponding linear trend line
Overall, the results indicate that GAN-CITE performs well across the selected range of labeled data settings and can improve classification performance even in scenarios where the availability of annotated data is constrained, confirming its effectiveness in classifying citation functions.
Impact of the sizes of unlabeled data on classification performance
While the scarcity of labeled data is a well-recognized challenge in machine learning, the impact of unlabeled data quantity on semi-supervised learning performance remains an open question. To investigate this phenomenon, we analyzed the influence of unlabeled data volume on our GAN-CITE model. We varied the amount of unlabeled data (U) across three settings: U = 100, 1000, and 10,000, to explore the relationship between unlabeled data size and model performance. By maintaining consistent experimental parameters as in the previous section, we isolated the effect of unlabeled data volume on the model’s ability to learn from limited labeled information.
Figure 5 illustrates the performance of GAN-CITE under different settings of unlabeled and labeled data. The algorithm citation function dataset was used in this experiment. For instance, in the UTILIZATION scheme, GAN-CITE, using 100 unlabeled samples, performed best in the 1% labeled data setting. Similarly, GAN-CITE using 1,000 unlabeled samples outperformed other models in the 2% and 5% labeled data settings, while GAN-CITE using 10,000 unlabeled samples yielded the best results in the 10% to 50% labeled data settings. The results for the USAGE scheme are similar, with a slight difference. GAN-CITE using 1,000 unlabeled samples performed best in the 2%, 5%, and 10% labeled data settings, while GAN-CITE with 10,000 unlabeled samples achieved the highest performance in the 20% to 50% labeled data settings.

Visualization of F1 scores from GAN-CITE with the varying settings of unlabeled data in the UTILIZATION and USAGE schemes. Log denotes the corresponding logarithmic trend line
In summary, GAN-CITE’s performance could be improved by carefully considering the sizes of labeled and unlabeled data or even the proportion between them. This finding suggests that a generative model, like GAN-CITE, needs to learn the distribution from labeled and unlabeled data to generate more accurate and representative fake data. Understanding the nature of generative models and optimizing the configuration of labeled and unlabeled data can lead to better results using this framework.
Discussion
Theoretical implications
Our research significantly advances the understanding of citation function analysis by highlighting the untapped potential of abundant available unlabeled citation contexts. These extensive text segments, which typically remain unused due to the labor-intensive process of manual annotation, can be effectively utilized through semi-supervised learning methods. By demonstrating how these unmarked contexts can enrich classification tasks, this study encourages a reevaluation of current methodologies in citation analysis. Additionally, introducing GAN-CITE as an innovative framework addresses the critical challenge posed by limited labeled data in automated classification systems. This framework not only incorporates a powerful pre-trained language model tailored for scientific literature but also integrates a cohesive set of modules designed for various stages of data handling and evaluation. As such, this work lays foundational groundwork for future investigations into optimizing machine learning frameworks within academic writing and reference analysis.
Practical implications
From a practical standpoint, the findings of this study provide valuable insights for researchers and practitioners involved in citation function classification. Organizations can streamline their processes by employing semi-supervised approaches to leverage unlabeled data and reduce their reliance on extensive manual annotation efforts. The proposed GAN-CITE framework offers researchers a robust tool that enhances automatic classification capabilities while ensuring adaptability across various datasets related to citation functions. Furthermore, the results generated from our framework serve as foundational elements for citation function analysis, enabling researchers to conduct more in-depth investigations into aspects such as the intentions behind authors citing specific papers and the evolution of widely recognized works that serve as reference points for subsequent research. Ultimately, this advancement improves efficiency in analyzing scholarly references and facilitates the progression of citation function analysis to new levels of understanding.
Limitations
The experimental findings have indicated that integrating a significant volume of unlabeled citation context data from scientific literature improves the classification of citation functions, as demonstrated in our evaluation case studies. However, despite these encouraging results, opportunities remain to refine our proposed framework further. Notably, our research has primarily validated specific semi-supervised learning methods as classifiers. While these techniques have shown promises, it is important to recognize that text classification encompasses a wide array of alternative semi-supervised approaches. Options such as Co-Training, Autoencoder-based methodologies, and Graph Neural Network (GNN)-based strategies could provide additional avenues for enhancing classification performance and should be explored in future investigations. By expanding the scope of semi-supervised techniques considered within this framework, we can potentially unlock further improvements in the accuracy and effectiveness of citation function classification systems.
Conclusion and future directions
This paper proposed GAN-CITE, a GAN-based, semi-supervised framework that utilizes unlabeled data to enhance the automatic classification of citation functions in scenarios where labeled data is limited. GAN-CITE was evaluated on various citation function datasets and demonstrated to outperform supervised and semi-supervised baseline methods when using 10%, 20%, and 30% of the total labeled data. We further examined GAN-CITE’s performance in imbalanced data scenarios, different labeled data settings, and the impact of unlabeled data sizes. These results highlight the potential of GAN-CITE for improving citation function classification under data scarcity. Future research could integrate GAN-CITE with active learning to prioritize unlabeled samples for human annotation, particularly those where the model shows the highest uncertainty. This approach ensures that annotations directly address knowledge gaps, maximizing information gain. Additionally, scientific literature offers several valuable features that could enhance classification efficacy. For example, the relative position of citations within a text can provide context that helps models understand the significance of specific citations and identify patterns indicative of particular functions (Zhang et al., 2021). Additionally, certain cue words can provide lexical insights that enable models to associate citation contexts with designated functions (Tuarob et al., 2020). Furthermore, global information from citation behavior in networks, analyzed through graph embedding techniques, can help clarify the prevalent purposes for which papers are cited (Pornprasit et al., 2022). Integrating these features is expected to enrich classification models’ information and lead to more robust and accurate results.
References
Abu-Jbara, A., & Radev, D. (2012). Reference scope identification in citing sentences. In Proceedings of the 2012 conference of the North American Chapter of the Association for Computational Linguistics: Human language technologies (pp. 80–90). Montréal, Canada. Association for Computational Linguistics.
Aggarwal, A., Mittal, M., & Battineni, G. (2021). Generative adversarial network: An overview of theory and applications. International Journal of Information Management Data Insights, 1(1), 100004.
Amini, M.-R., Feofanov, V., Pauletto, L., Devijver, E., & Maximov, Y. (2022). Self-training: A survey. arXiv:2202.12040
An, X., Sun, X., & Xu, S. (2022). Important citations identification with semi-supervised classification model. Scientometrics, 11, 6533–6555.
Beltagy, I., Lo, K., & Cohan, A. (2019). Scibert: A pretrained language model for scientific text. In Conference on empirical methods in natural language processing.
Bird, S., Dale, R., Dorr, B., Gibson, B. R., Joseph, M. T., Kan, M.-Y., Lee, D., Powley, B., Radev, D. R., & Tan, Y. F. (2008). The ACL anthology reference corpus: A reference dataset for bibliographic research in computational linguistics. In International conference on language resources and evaluation.
Bornmann, L., & Daniel, H.-D. (2008). What do citation counts measure? A review of studies on citing behavior. Journal of Documentation, 64, 45–80.
Cohan, A., Ammar, W., van Zuylen, M., & Cady, F. (2019) Structural scaffolds for citation intent classification in scientific publications. In North American chapter of the Association for Computational Linguistics
Cohan, A., Feldman, S., Beltagy, I., Downey, D., & Weld, D. S. (2020). Specter: Document-level representation learning using citation-informed transformers. arXiv:2004.07180
Colón-Ruiz, C. (2021). Semi-supervised generative adversarial network for sentiment analysis of drug reviews. TechRxiv. https://doi.org/10.36227/techrxiv.17075054
Creswell, A., White, T., Dumoulin, V., Arulkumaran, K., Sengupta, B., & Bharath, A. A. (2017). Generative adversarial networks: An overview. IEEE Signal Processing Magazine, 35, 53–65.
Croce, D., Castellucci, G., & Basili, R. (2020). Gan-Bert: Generative adversarial learning for robust text classification with a bunch of labeled examples. In Annual meeting of the Association for Computational Linguistics.
Danielsson, B., Santini, M., Lundberg, P. W., Al-Abasse, Y., Jönsson, A., Eneling, E., & Stridsman, M. (2022). Classifying implant-bearing patients via their medical histories: A pre-study on Swedish EMRS with semi-supervised GANBERT. In International conference on language resources and evaluation.
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805
Färber, M., & Jatowt, A. (2020). Citation recommendation: Approaches and datasets. International Journal on Digital Libraries, 21, 375–405.
Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A. C., & Bengio, Y. (2014). Generative adversarial nets. In Neural information processing systems.
Jan, R. (2009). Citation analysis of library trends. Webology, 6, 03.
Jiang, X., & Chen, J. (2023). Contextualised segment-wise citation function classification. Scientometrics, 128, 5117–5158.
Jiang, X., Cai, C., Fan, W., Liu, T., & Chen, J. (2022). Contextualised modelling for effective citation function classification. Proceedings of the 2022 6th international conference on natural language processing and information retrieval.
Jurgens, D., Kumar, S., Hoover, R., McFarland, D. A., & Jurafsky, D. (2018). Measuring the evolution of a scientific field through citation frames. Transactions of the Association for Computational Linguistics, 6, 391–406.
Kingma, D. P., Mohamed, S., Jimenez Rezende, D., & Welling, M. (2014). Semi-supervised learning with deep generative models. In Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, & K. Q. Weinberger (Eds.), Advances in neural information processing systems (Vol. 27). Curran Associates.
Kontonatsios, G., Brockmeier, A. J., Przybyła, P., McNaught, J., Mu, T., Goulermas, J. Y., & Ananiadou, S. (2017). A semi-supervised approach using label propagation to support citation screening. Journal of Biomedical Informatics, 72, 67–76.
Lo, K., Wang, L. L, Neumann, M., Kinney, R., & Weld, D. (2020). S2ORC: The semantic scholar open research corpus. In Proceedings of the 58th annual meeting of the Association for Computational Linguistics (pp. 4969–4983). Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.acl-main.447
Ma, S., Zhang, C., Zhang, H., & Gao, Z. (2025). Citation recommendation based on argumentative zoning of user queries. Journal of Informetrics, 19(1), 101607. https://doi.org/10.1016/j.joi.2024.101607
Moravcsik, M. J., & Murugesan, P. (1975). Some results on the function and quality of citations. Social Studies of Science, 5, 86–92.
Narin, F. (1976). Evaluative bibliometrics: The use of publication and citation analysis in the evaluation of scientific activity. Computer Horizons.
Pornprasit, C., Liu, X., Kiattipadungkul, P., Kertkeidkachorn, N., Kim, K.-S., Noraset, T., Hassan, S.-U., & Tuarob, S. (2022). Enhancing citation recommendation using citation network embedding. Scientometrics, 127, 1–32.
Poulain, R., Gupta, M., & Beheshti, R. (2022). Few-shot learning with semi-supervised transformers for electronic health records. In Proceedings of the 7th machine learning for healthcare conference.
Qazvinian, V., Radev, D. R., & Özgür, A. (2010). Citation summarization through keyphrase extraction. In international conference on computational linguistics.
Qi, R., Wei, J., Shao, Z., Li, Z., Chen, H., Sun, Y., & Li, S. (2023). Multi-task learning model for citation intent classification in scientific publications. Scientometrics, 128, 6335–6355.
Rachman, G. H., Khodra, M. L., & Widyantoro, D. H. (2019). Classification of citation sentence for filtering scientific references. In 2019 4th international conference on information technology, information systems and electrical engineering (ICITISEE) (pp. 347–352).
Salimans, T., Goodfellow, I. J., Zaremba, W., Cheung, V., Radford, A., & Chen, X. (2016). Improved techniques for training GANS. arXiv:1606.03498
Setio, B., & Tsuchiya, M. (2022). SDCF: Semi-automatically structured dataset of citation functions. Scientometrics, 127, 4569–4608.
Su, X., Prasad, A., Kan, M.-Y., & Sugiyama, K. (2018). Neural multi-task learning for citation function and provenance. 2019 ACM/IEEE joint conference on digital libraries (JCDL) (pp. 394–395).
Teufel, S., Siddharthan, A., & Tidhar, D. (2006). Automatic classification of citation function. In D. Jurafsky & E. Gaussier (Eds.), Proceedings of the 2006 conference on empirical methods in natural language processing (pp. 103–110). Sydney, Australia. Association for Computational Linguistics.
Tuarob, S., Kang, S., Wettayakorn, P., Pornprasit, C., Sachati, T., Hassan, S.-U., & Haddawy, P. (2020). Automatic classification of algorithm citation functions in scientific literature. IEEE Transactions on Knowledge and Data Engineering, 32, 1881–1896.
Vuletić, M., Prenzel, F., & Cucuringu, M. (2024). FIN-GAN: Forecasting and classifying financial time series via generative adversarial networks. Quantitative Finance, 24(2), 175–199.
Wu, J., Kandimalla, B., Rohatgi, S., Sefid, A., Mao, J., & Giles, C. L. (2018). CiteSeerX-2018: A cleansed multidisciplinary scholarly big dataset. In 2018 IEEE international conference on big data (Big Data) (pp. 5465–5467). IEEE.
Yousif, A., Niu, Z., Tarus, J. K., & Ahmad, A. (2019). A survey on sentiment analysis of scientific citations. Artificial Intelligence Review, 52, 1805–1838.
Zhang, Y., Wang, Y., Sheng, Q. Z., Mahmood, A., Emma Zhang, W., & Zhao, R. (2021). TDM-CFC: Towards document-level multi-label citation function classification. In W. Zhang, L. Zou, Z. Maamar, & L. Chen (Eds.), Web information systems engineering–WISE 2021 (pp. 363–376). Springer.
Zhang, Y., Zhao, R., Wang, Y., Chen, H., Mahmood, A., Zaib, M., Zhang, W. E., & Sheng, Q. Z. (2022). Towards employing native information in citation function classification. Scientometrics, 127, 1–21.
Zhang, Y., Wang, Y., Sheng, Q. Z., Mahmood, A., Zhang, W. E., & Zhao, R. (2023). Hybrid data augmentation for citation function classification. In 2023 International joint conference on neural networks (IJCNN) (pp. 1–8). https://doi.org/10.1109/IJCNN54540.2023.10191695
Zhao, H., Luo, Z., Feng, C., Zheng, A., & Liu, X. (2019). A context-based framework for modeling the role and function of on-line resource citations in scientific literature. In Conference on empirical methods in natural language processing.
Zhu, X. (2005). Semi-supervised learning literature survey. Technical Report 1530, Computer Science, University of Wisconsin-Madison.
Zhu, X., & Ghahramani, Z. (2002). Learning from labeled and unlabeled data with label propagation. Technical report, Carnegie Mellon University.
Acknowledgements
This research was partially supported by the Office of Higher Education Commission (OHEC) Thailand and the Thailand Research Fund (TRF) through grant MRG6080252.
Funding
Open access funding provided by Mahidol University.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chatrinan, K., Noraset, T. & Tuarob, S. GAN-CITE: leveraging semi-supervised generative adversarial networks for citation function classification with limited data. Scientometrics 130, 679–703 (2025). https://doi.org/10.1007/s11192-025-05233-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-025-05233-1