
Abstract
Computer benchmarking is a common method for measuring the parameters of a computational model. It helps to measure the parameters of any computer. With the emergence of multicore computers, the evaluation of computers was brought under consideration. Since these types of computers can be viewed and considered as parallel computers, the evaluation methods for parallel computers may be appropriate for multicore computers. However, because multicore architectures seriously focus on cache hierarchy, there is a need for new and different benchmarks to evaluate them correctly.
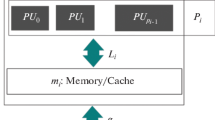
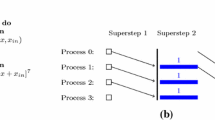
To this end, this paper presents a method for measuring the parameters of one of the most famous multicore computational models, namely Multi-Bulk Synchronous Parallel (Multi-BSP). This method measures the hardware latency parameters of multicore computers, namely communication latency (g i ) and synchronization latency (L i ) for all levels of the cache memory hierarchy in a bottom-up manner. By determining the parameters, the performance of algorithms on multicore architectures can be evaluated as a sequence.



Similar content being viewed by others

References
Aggarwal A, Vitter JS (1988) The input/output complexity of sorting and related problems. Commun ACM 31:1116–1127. doi:10.1145/48529.48535
Alpern B, Carter L, Feig E, Selker T (1994) The uniform memory hierarchy model of computation. Algorithmica 12:72–109. doi:10.1007/BF01185206
Arge L, Goodrich MT, Nelson M, Sitchinava N (2008) Fundamental parallel algorithms for private-cache chip multiprocessors. In: Proceedings of the twentieth annual symposium on parallelism in algorithms and architectures, SPAA ’08. ACM, New York, pp 197–206. http://doi.acm.org/10.1145/1378533.1378573
Arge L, Goodrich MT, Sitchinava N, Nelson M (2008) Fundamental parallel algorithms for privatecache chip multiprocessors. In: 20th ACM symposium on parallelism in algorithm and architectures (SPAA). ACM, New York, pp 197–206
Bailey D, Barszcz E, Barton J, Browning D, Carter R, Dagum L, Fatoohi R, Frederickson P, Lasinski T, Schreiber R, Simon H, Venkatakrishnan V, Weeratunga S (1991) The nas parallel benchmarks summary and preliminary results. In: Supercomputing, 1991. Proceedings of the 1991 ACM/IEEE conference on supercomputing, pp 158–165
Bisseling RH (2004) Parallel scientific computation: a structured approach using BSP and MPI. Oxford University Press, Oxford
Blelloch GE, Chowdhury RA, Gibbons PB, Ramachandran V, Chen S, Kozuch M (2008) Provably good multicore cache performance for divide-and-conquer algorithms. In: Proceedings of the nineteenth annual ACM-SIAM symposium on discrete algorithms, SODA ’08. Society for Industrial and Applied Mathematics, Philadelphia, pp 501–510. http://portal.acm.org/citation.cfm?id=1347082.1347137
Blelloch GE, Fineman JT, Gibbons PB, Simhadri HV (2011) Scheduling irregular parallel computations on hierarchical caches. In: Proceedings of the 23rd ACM symposium on parallelism in algorithms and architectures, SPAA ’11. ACM, New York, pp 355–366. http://doi.acm.org/10.1145/1989493.1989553
Butenhof DR Programming with POSIX threads. Addison-Wesley
Che S, Boyer M, Meng J, Tarjan D, Sheaffer J, Lee SH, Skadron K (2009) Servet: a benchmark suite for autotuning on multicore clusters. In: Proceedings of international symposium on workload characterization, IISWC2009, pp 44–54
Chowdhury R, Silvestri F, Blakeley B, Ramachandran V (2010) Oblivious algorithms for multicores and network of processors. In: IEEE international symposium on parallel distributed processing (IPDPS), pp 1–12
Culler DE, Karp RM, Patterson D, Sahay A, Santos EE, Schauser KE, Subramonian R, von Eicken T (1996) Logp: a practical model of parallel computation. Commun ACM 39:78–85. http://doi.acm.org/10.1145/240455.240477
Fortune S, Wyllie J (1978) Parallelism in random access machines. In: Proceedings of the tenth annual ACM symposium on theory of computing, STOC ’78. ACM, New York, pp 114–118. http://doi.acm.org/10.1145/800133.804339
Frigo M, Leiserson CE, Prokop H, Ramachandran S (1999) Cache-oblivious algorithms. In: Annual IEEE symposium on foundations of computer science, p 285
Gal-On S, Levy M (2008) Measuring multicore performance. Computer 41:99–102
Gerbessiotis AV, Lee SY (2004) Remote memory access: a case for portable, efficient and library independent parallel programming. Sci Program 12(3):169–183. http://dl.acm.org/citation.cfm?id=1240140.1240144
Gonzalez-Dominguez J, Taboada G, Fraguela B, Martin M, Tourio J (2010) Servet: a benchmark suite for autotuning on multicore clusters. In: Proceedings of international symposium on parallel and distributed processing, IPDPS2010, pp 1–9
Hill JMD, Donaldson SR, Skillicorn DB (1997) Stability of communication performance in practice: From the cray t3e to networks of workstations. Technical Report PRG-TR-33-97, Programming Research Group, Oxford University Computing Laboratory
Hill JMD, Skillicorn DB (1998) Practical barrier synchronisation. In: 6th EuroMicro workshop on parallel and distributed processing (PDP’98). IEEE Computer Society Press, Los Alamitos, pp 438–444
Hill JM, McColl B, Stefanescu DC, Goudreau MW, Lang K, Rao SB, Suel T, Tsantilas T, Bisseling RH (1998) Bsplib: the bsp programming library. Parallel Comput 24(14):1947–1980. http://www.sciencedirect.com/science/article/pii/S0167819198000933
Kayi A, Yao Y, El-Ghazawi T, Newby G (2007) Experimental evaluation of emerging multi-core architectures. In: Proceedings of 21th international parallel and distributed processing symposium, IPDPS2007
Linux-operating-systems. http://linux.die.net
Mellor-Crummey JM, Scott ML (1991) Algorithms for scalable synchronization on shared-memory multiprocessors. ACM Trans Comput Syst 9(1):21–65. http://doi.acm.org/10.1145/103727.103729
Ramachandran V (1997) Qsm: a general purpose shared-memory model for parallel computation. In: Ramesh S, Sivakumar G (eds) Foundations of software technology and theoretical computer science. Lecture notes in computer science, vol 1346. Springer, Berlin, pp 1–5. doi:10.1007/BFb0058018
Sampson J, González R, Collard JF, Jouppi NP, Schlansker M (2005) Fast synchronization for chip multiprocessors. SIGARCH Comput Archit News 33(4):64–69. http://doi.acm.org/10.1145/1105734.1105743
Savage J (1995) Extending the hong-kung model to memory hierarchies. In: Du DZ, Li M (eds) Computing and combinatorics. Lecture notes in computer science, vol 959. Springer, Berlin, pp 270–281. doi:10.1007/BFb0030842
Savage JE, Zubair M (2008) A unified model for multicore architectures. In: Proceedings of the 1st international forum on next-generation multicore/manycore technologies, IFMT ’08. ACM, New York, pp 9:1–9:12. http://doi.acm.org/10.1145/1463768.1463780
Singh JP, Weber WD, Gupta A (1992) Splash: Stanford parallel applications for shared-memory. SIGARCH Comput Archit News 20(1):5–44. http://doi.acm.org/10.1145/130823.130824
S.P.E.C.S. benchmarks http://www.spec.org/
Valiant LG (1990) A bridging model for parallel computation. Commun ACM 33:103–111. http://doi.acm.org/10.1145/79173.79181
Valiant LG (2011) A bridging model for multi-core computing. J Comput Syst Sci 77(1):154–166. http://www.sciencedirect.com/science/article/B6WJ0-508X3P4-5/2/92a9dec04839a9e93887ca26e0d9b3f2, celebrating Karp’s Kyoto Prize
Yang TF, Lin CH, Yang CL (2010) Cache-aware task scheduling on multi-core architecture. In: 2010 international symposium on VLSI design automation and test (VLSI-DAT), pp 139–142. doi:10.1109/VDAT.2010.5496710
Yotov K, Roeder T, Pingali K, Gunnels J, Gustavson F (2007) An experimental comparison of cache-oblivious and cache-conscious programs. In: Proceedings of the nineteenth annual ACM symposium on parallel algorithms and architectures, SPAA ’07. ACM, New York, pp 93–104. http://doi.acm.org/10.1145/1248377.1248394
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Savadi, A., Deldari, H. Measurement of the latency parameters of the Multi-BSP model: a multicore benchmarking approach. J Supercomput 67, 565–584 (2014). https://doi.org/10.1007/s11227-013-1018-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-013-1018-4