
Abstract
Simulation is often used in order to evaluate the behavior and the performance of computing systems. Specifically, in the field of high-performance interconnection networks for HPC clusters the simulation has been extensively considered to verify and validate network operation models and to evaluate their performance. Nevertheless, experiments conducted to evaluate network performance using simulation tools should be fed with realistic network traffic from real benchmarks and/or applications. This approach has grown in popularity because it allows to evaluate the simulation model under realistic traffic situations. In this paper, we propose a family of tools for modeling realistic workloads which capture the behavior of MPI applications into self-related traces called VEF traces. The main novelty of this approach is that it replays the MPI collective operations with their corresponding messages, offering an MPI message-based task simulation framework. The proposed framework neither provides a network simulator nor depends on any specific simulation platform. Besides, this framework allows us to use the generated traces by any third-party network simulator working at message level.









Similar content being viewed by others


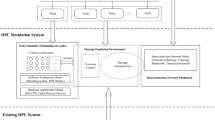
Notes
Or several nodes for the case of parallel simulators.
An MPI function can result in just one message injected in the network or several messages in the case of collective operations.
VEF is an acronym formed by the original programmer names: Villar, Escudero and Francisco.
Note that VEF traces do not support comments. The comments in the right side have been included here in order to facilitate the interpretation of the content of the trace.
Note that Wait() models blocking receives and iRecv() models non-blocking receives, regardless the MPI function that generates the iRecv() or the Wait() record.
Commonly, it is a NIC or a processing node, depending on the simulator implementation.
References
Anderson T, Owicki S, Saxe J, Thacker C (1993) High-speed switch scheduling for local-area networks. ACM Trans Comput Syst 11:319–352
Andújar FJ, Villar JA, Sánchez JL, Alfaro FJ, Duato J (2015) N-dimensional twin torus topology. IEEE Trans Comput 64(10):2847–2861
Andújar FJ, Villar JA, Sánchez JL, Alfaro FJ, Escudero-Sahuquillo J (2015) VEF traces: a framework for modelling MPI traffic in interconnection network simulators. The 1st IEEE International Workshop on High-Performance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB 2015), co-located with 2015 IEEE International Conference on Cluster Computing (CLUSTER 2015), Chicago, IL, USA, pp 841–848
Birke R, Rodriguez G, Minkenberg C (2012) Towards massively parallel simulations of massively parallel high-performance computing systems. In: Proceedings of the 5th International Conference on Simulation Tools and Techniques, Brussels, Belgium, pp 291–298
Casanova H, Desprez F, Markomanolis GS, Suter F (2015) Simulation of MPI applications with time-independent traces. Concurr Comput Pract Exp 27(5):1145–1168
DIMEMAS (2015) Dimemas: predict parallel performance using a single cpu machine. https://www.bsc.es/computer-sciences/performance-tools/dimemas. Accessed May 2016
Duato J, Yalamanchili S, Ni L (2003) Interconnection networks. An engineering approach. Morgan Kaufmann Publishers Inc, San Francisco, CA, USA
EXTRAE (2015) Homepage of the library Extrae. http://www.bsc.es/computer-sciences/extrae. Accessed May 2016
Gabriel E et al (2004) Open MPI: goals, concept, and design of a next generation MPI implementation. In: Proceedings of the 11th European PVM/MPI Users’ Group Meeting. Budapest, Hungary, pp 97–104
GALGO (2015) GALGO—Albacete Research Institute of Informatics Supercomputer Center. http://www.i3a.uclm.es/galgo. Accessed May 2016
GRAPH500 (2015) Homepage of Graph500. http://www.graph500.org/. Accessed May 2016
Janssen CL, Adalsteinsson H, Cranford S, Kenny JP, Pinar A, Evensky DA, Mayo J (2010) A simulator for large-scale parallel computer architectures. J Distrib Syst Technol 1(2):57–73
Karol M, Hluchyj M (1998) Queuing in high-performance packet-switching. IEEE J Sel Areas 1:1587–1597
Karrels E, Lusk E (1994) Performance analysis of MPI program. In: Proceedings of the workshop on Environments and Tools for Parallel Scientific Computing, pp 195–200
Miguel-Alonso J, Navaridas J, Ridruejo F (2008) Interconnection network simulation using traces of mpi applications. Tech. Rep. EHU-KAT-IK-01-08, Department of Computer Architecture and Technology, The Universiy of the Basque Country, Spain
Miguel-Alonso J, Navaridas J, Ridruejo F (2009) Interconnection network simulation using traces of MPI applications. Int J Parallel Program 37(2):153–174
Nagel WE, Arnold A, Weber M, Hoppe HC, Solchenbach K (1996) Vampir: visualization and analysis of mpi resources. Supercomputer 12:69–80
Núñez A, Fernández J, García J, Carretero J (2008) New techniques for simulating high performance MPI applications on large storage networks. In: Proceedings of the IEEE International Conference on Cluster Computing, Tsukuba, Japan, pp 444–452
Penoff B, Wagner A, Tüxen M, Rüngeler I (2009) MPI-NeTSim: a network simulation module for MPI. In: Proceedings of the 15th International Conference on Parallel and Distributed Systems. IEEE Computer Society, Washington, DC, USA, pp 464–471
Pillet V, Labarta J, Cortes T, Girona S (1995) Paraver: a tool to visualize and analyze parallel code. Tech. Rep. RR-95/03, Departament D’arquitectura De Computadors. Universitat Politècnica de Catalunya, Spain
Riesen R (2006) A hybrid MPI simulator. In: Proceedings of the IEEE International Conference on Cluster Computing, Barcelona, Spain, pp 1–9
Shende SS, Malony AD (2006) The Tau parallel performance system. Int J High Perform Comput Appl 20(2):287–311
Snir M, Otto S, Huss-Lederman S, Walker D, Dongarra J (1998) MPI-the complete reference, vol 1. The MPI Core, 2nd edn. MIT Press, Cambridge
SST (2015) The structural simulation toolkit. http://sst-simulator.org. Accessed May 2016
Tikir M, Laurenzano M, Carrington L, Snavely A (2009) PSINS: an open source event tracer and execution simulator for MPI applications. In: Euro-Par 2009 Parallel Processing, Lecture Notes in Computer Science, vol 5704. Springer, Berlin Heidelberg, pp 135–148
Triviño F, Andújar F, Alfaro F, Sánchez J, Ros A (2011) Self-related traces: an alternative to full-system simulation for NoCs. In: Proceedings of the International Conference on High Performance Computing and Simulation, Istanbul, Turkey, pp 819–824
VEF (2015) VEF traces homepage. http://www.i3a.info/VEFtraces. Accessed May 2016
Villar JA, Andújar FJ, Sánchez JL, Alfaro FJ, Gámez JA, Duato J (2013) Obtaining the optimal configuration of high-radix combined switches. J Parallel Distrib Comput 73(9):1239–1250. doi:10.1016/j.jpdc.2013.04.009
Yebenes P, Escudero-Sahuquillo J, Requena CG, García PJ, Quiles FJ, Duato J (2013) BBQ: a straightforward queuing scheme to reduce HoL-blocking in high-performance hybrid networks. In: Proceedings of the 19th International Conference Euro-Par Parallel Processing, Aachen, Germany, pp 699–712
Zheng G, Kakulapati G, Kale L (2004) BigSim: a parallel simulator for performance prediction of extremely large parallel machines. In: Proceedings of the 18th International Parallel and Distributed Processing Symposium, Santa Fe, New Mexico, USA, p 78
Acknowledgments
This work has been jointly supported by the MINECO and European Commission (FEDER funds) under the project TIN2015-66972-C5-2-R, and by Junta de Comunidades de Castilla-La Mancha under the Project PEII-2014-028-P. Francisco J. Andújar is also funded by the Spanish Ministry of Science and Innovation MICINN under FPU grant AP2010-4680 and Jesus Escudero-Sahuquillo has been funded by the Spanish MINECO under the postdoctoral grant FPDI-2013-18787 until November 2015 and, from that date, he has been funded by the University of Castilla-La Mancha (UCLM) and the European Commission (FSE funds), with a contract for accessing the Spanish System of Science, Technology and Innovation, for the implementation of the UCLM research program (UCLM resolution date: 31/07/2014).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Andújar, F.J., Villar, J.A., Alfaro, F.J. et al. An open-source family of tools to reproduce MPI-based workloads in interconnection network simulators. J Supercomput 72, 4601–4628 (2016). https://doi.org/10.1007/s11227-016-1757-0
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-016-1757-0