
Abstract
The industry trends for processors are toward integrating an increasing number of cores into a single chip. Researchers have to deal with frequent data migration across network-on-chip and the increasing on-chip traffic. The innovation from flat to hierarchy is probably a natural design methodology for scalable systems (Martin et al. in Commun ACM, 55(7):78–89, 2012. doi:10.1145/2209249.2209269). Unfortunately, the alternative of hierarchical directory protocol inevitably leads to on-chip traffic overhead, protocol complexity and access latency. In this paper, we target hierarchical cache coherence protocol to overcome the potentially high cost of maintaining cache coherence in current multicore processors. We propose a novel vertical caching protocol combined with grouped coherence, in which the coherence domain expand on demand. More specifically, its design philosophy is to provide a ‘best-effort’ single-copy delivery which allows the shared data only in the first common shared level. Compared to the previous hierarchical protocol, our proposal is able to achieve the performance improvement of 9.9% in the 16-core system and 13.4% in the 64-core system as well as an on-chip traffic reduction of about 10.8% in the 16-core system and 15.9% in the 64-core system, respectively.















Similar content being viewed by others
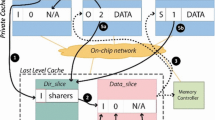
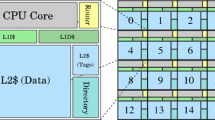

Notes
Note that the cluster referred to in this article is a recursive definition, namely, a bigger cluster probably includes several sub-cluster.
References
Acacio ME, Gonzalez J, Garcia JM, Duato J (2004) An architecture for high-performance scalable shared-memory multiprocessors exploiting on-chip integration. IEEE Trans Parallel Distrib Syst 15(8):755–768. doi:10.1109/TPDS.2004.27
Balasubramonian R, Jouppi NP, Muralimanohar N (2011) Multi-core cache hierarchies. Morgan Claypool. doi:10.2200/S00365ED1V01Y201105CAC017
Beckmann BM, Marty MR, Wood DA (2006) Asr: adaptive selective replication for cmp caches. In: 2006 39th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO’06), pp 443–454. doi:10.1109/MICRO.2006.10
Binkert N, Beckmann B, Black G, Reinhardt SK, Saidi A, Basu A, Hestness J, Hower DR, Krishna T, Sardashti S, Sen R, Sewell K, Shoaib M, Vaish N, Hill MD, Wood DA (2011) The gem5 simulator. SIGARCH Comput Archit News 39(2):1–7. doi:10.1145/2024716.2024718
Chang J, Sohi GS (2006) Cooperative caching for chip multiprocessors. In: 33rd International Symposium on Computer Architecture (ISCA’06), pp 264–276. doi:10.1109/ISCA.2006.17
Chishti Z, Powell MD, Vijaykumar TN (2005) Optimizing replication, communication, and capacity allocation in cmps. In: 32nd International Symposium on Computer Architecture (ISCA’05), pp 357–368. doi:10.1109/ISCA.2005.39
Della Vecchia G, Sanges C (1988) A recursively scalable network VLSI implementation. Fut Gener Comput Syst 4(3):235–243
Demetriades S, Cho S (2014) Stash directory: a scalable directory for many-core coherence. In: 2014 IEEE 20th International Symposium on High Performance Computer Architecture (HPCA), pp 177–188. doi:10.1109/HPCA.2014.6835928
Fu Y, Nguyen TM, Wentzlaff D (2015) Coherence domain restriction on large scale systems. In: Proceedings of the 48th International Symposium on Microarchitecture, MICRO-48. ACM, New York, NY, USA, pp 686–698. doi:10.1145/2830772.2830832
Guo SL, Wang HX, Xue YB, Li CM, Wang DS (2010) Hierarchical cache directory for cmp. J Comput Sci Technol 25(2):246–256. doi:10.1007/s11390-010-9321-5
Jerger NE, Peh LS, Lipasti M (2008) Virtual circuit tree multicasting: a case for on-chip hardware multicast support. In: 2008 International Symposium on Computer Architecture, pp 229–240. doi:10.1109/ISCA.2008.12
Kim C, Burger D, Keckler SW (2002) An adaptive, non-uniform cache structure for wire-delay dominated on-chip caches. SIGARCH Comput Archit News 30(5):211–222. doi:10.1145/635506.605420
Lotfi-Kamran P, Grot B, Ferdman M, Volos S, Kocberber O, Picorel J, Adileh A, Jevdjic D, Idgunji S, Ozer E, Falsafi B (2012) Scale-out processors. In: 2012 39th Annual International Symposium on Computer Architecture (ISCA), pp 500–511. doi:10.1109/ISCA.2012.6237043
Martin MMK, Hill MD, Sorin DJ (2012) Why on-chip cache coherence is here to stay. Commun ACM 55(7):78–89. doi:10.1145/2209249.2209269
Nilsson H, Stenstrom P (1992) The scalable tree protocol-a cache coherence approach for large-scale multiprocessors. In: [1992] Proceedings of the Fourth IEEE Symposium on Parallel and Distributed Processing, pp 498–506. doi:10.1109/SPDP.1992.242703
Pugsley SH, Spjut JB, Nellans DW, Balasubramonian R (2010) Swel: Hardware cache coherence protocols to map shared data onto shared caches. In: Proceedings of the 19th International Conference on Parallel Architectures and Compilation Techniques, PACT ’10. ACM, New York, NY, USA, pp 465–476. doi:10.1145/1854273.1854331
Rashid KHU, Shi F, Ji W, Jing Y, Wang Y, Liu C, Deng N, Li J (2010) Computationally efficient locality-aware interconnection topology for multi-processor system-on-chip(mp-soc). Chin Sci Bull 55(29):3363–3371
Ros A, Davari M, Kaxiras S (2015) Hierarchical private/shared classification: the key to simple and efficient coherence for clustered cache hierarchies. In: 2015 IEEE 21st International Symposium on High Performance Computer Architecture (HPCA), pp 186–197. doi:10.1109/HPCA.2015.7056032
Sodani A, Gramunt R, Corbal J, Kim HS, Vinod K, Chinthamani S, Hutsell S, Agarwal R, Liu YC (2016) Knights landing: second-generation intel xeon phi product. IEEE Micro 36(2):34–46. doi:10.1109/MM.2016.25
Wang YC, Juan ST (2015) Hamiltonicity of the basic wk-recursive pyramid with and without faulty nodes. Theor Comput Sci 562(C):542–556
Wentzlaff D, Griffin P, Hoffmann H, Bao L, Edwards B, Ramey C, Mattina M, Miao CC, Brown JF III, Agarwal A (2007) On-chip interconnection architecture of the tile processor. IEEE Micro 27(5):15–31. doi:10.1109/MM.2007.4378780
Wilson AW Jr. (1987) Hierarchical cache/bus architecture for shared memory multiprocessors. In: Proceedings of the 14th Annual International Symposium on Computer Architecture, ISCA ’87. ACM, New York, NY, USA, pp 244–252. doi:10.1145/30350.30378
Woo SC, Ohara M, Torrie E, Singh JP, Gupta A (1995) The splash-2 programs: characterization and methodological considerations. ISCA ’95. ACM, New York, NY, USA, pp 24–36. doi:10.1145/223982.223990
Yan S, Zhou X, Gao Y, Chen H, Luo S, Zhang P, Cherukuri N, Ronen R, Saha B (2009) Terascale chip multiprocessor memory hierarchy and programming model. In: 2009 International Conference on High Performance Computing (HiPC), pp 150–159. doi:10.1109/HIPC.2009.5433215
Zhang M, Asanovic K (2005) Victim replication: maximizing capacity while hiding wire delay in tiled chip multiprocessors. In: 32nd International Symposium on Computer Architecture (ISCA’05), pp 336–345. doi:10.1109/ISCA.2005.53
Zhao H, Shriraman A, Kumar S, Dwarkadas S (2013) Protozoa: adaptive granularity cache coherence. In: Proceedings of the 40th Annual International Symposium on Computer Architecture, ISCA ’13. ACM, New York, NY, USA, pp 547–558. doi:10.1145/2485922.2485969
Zuo W, Feng S, Qi Z, Weixing J, Jiaxin L, Ning D, Licheng X, Yuan T, Baojun Q (2009) Group-caching for noc based multicore cache coherent systems. In: 2009 Design, Automation Test in Europe Conference Exhibition, pp 755–760. doi:10.1109/DATE.2009.5090765
Acknowledgements
We would like to thank the anonymous reviewers for their helpful suggestions.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Hu, S., Shi, F., Ji, W. et al. Exploring grouped coherence for clustered hierarchical cache. J Supercomput 73, 4137–4157 (2017). https://doi.org/10.1007/s11227-017-2024-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-017-2024-8