
Abstract
Parallel programming can be difficult and error prone, in particular if low-level optimizations are required in order to reach high performance in complex environments such as multi-core clusters using MPI and OpenMP. One approach to overcome these issues is based on algorithmic skeletons. These are predefined patterns which are implemented in parallel and can be composed by application programmers without taking care of low-level programming aspects. Support for algorithmic skeletons is typically provided as a library. However, optimizations are hard to implement in this setting and programming might still be tedious because of required boiler plate code. Thus, we propose a domain-specific language for algorithmic skeletons that performs optimizations and generates low-level C++ code. Our experimental results on four benchmarks show that the models are significantly shorter and that the execution time and speedup of the generated code often outperform equivalent library implementations using the Muenster Skeleton Library.

Similar content being viewed by others
Notes
The model-driven software development community prefers the notion DSL model rather than DSL program.
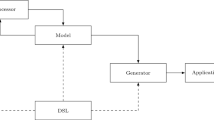
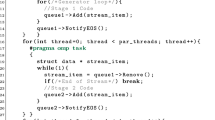
Due to the lack of space, only the overall structure and the main concepts of the language are presented here and an excerpt of the DSL is given in Listing 2. The full DSL specification can be found in our code repository [25].
The Xtext representation of the full DSL is available in our code repository [25].
References
Chapman B, Jost G, van der Pas R (2008) Using OpenMP: portable shared memory parallel programming. Scientific and engineering computation. MIT Press, Cambridge
Gropp W, Lusk E, Skjellum A (2014) Using MPI: portable parallel programming with the message-passing interface. Scientific and engineering computation, 3rd edn. MIT Press, Cambridge
Nickolls J, Buck I, Garland M, Skadron K (2008) Scalable parallel programming with CUDA. Queue 6(2):40–53
Stone JE, Gohara D, Shi G (2010) OpenCL: a parallel programming standard for heterogeneous computing systems. Comput Sci Eng 12(3):66–73
Cole M (1991) Algorithmic skeletons: structured management of parallel computation. MIT Press, Cambridge
Ernsting S, Kuchen H (2012) Algorithmic skeletons for multi-core, multi-GPU systems and clusters. Int J High Perform Comput Netw 7(2):129–138
Ernsting S, Kuchen H (2017) Data parallel algorithmic skeletons with accelerator support. Int J Parallel Program 45(2):283–299
Aldinucci M, Danelutto M, Meneghin M, Torquati M, Kilpatrick P (2010) Efficient streaming applications on multi-core with FastFlow: the biosequence alignment test-bed. In: Chapman B, Desprez F, Joubert GR, Lichnewsky A, Peters F, Priol T (eds) Parallel computing: from multicores and GPU’s to petascale, advances in parallel computing, vol 19. IOS Press, Amsterdam
Benoit A, Cole M, Gilmore S, Hillston J (2005) Flexible skeletal programming with eSkel. In: Cunha JC, Medeiros PD, (eds) Proceedings of the 11th International Euro-Par Conference on Parallel Processing (Euro-Par ’05), Lecture Notes in Computer Science, vol 3648. Springer, pp 761–770
Ernstsson A, Li L, Kessler C (2017) SkePU 2: Flexible and type-safe skeleton programming for heterogeneous parallel systems. Int J Parallel Program 46(1):62–80
Matsuzaki K, Emoto K (2010) Implementing fusion-equipped parallel skeletons by expression templates. In: Morazán MT, Scholz S (eds) Implementation and application of functional languages. Springer, Berlin, pp 72–89
Veldhuizen T (1995) Expression templates. C++ Rep 7(5):26–31
Stahl T, Völter M (2006) Model-driven software development. Wiley, Chichester
Mernik M, Heering J, Sloane AM (2005) When and how to develop domain-specific languages. ACM Comput Surv 37(4):316–344
Almorsy M, Grundy J (2015) Supporting scientists in re-engineering sequential programs to parallel using model-driven engineering. In: 2015 IEEE/ACM 1st International Workshop on Software Engineering for High Performance Computing in Science, pp 1–8. IEEE
Anderson TA, Liu H, Kuper L, Totoni E, Vitek J, Shpeisman T (2017) Parallelizing Julia with a non-invasive DSL. In: Müller P (ed) 31st European Conference on Object-Oriented Programming (ECOOP ’17), Leibniz International Proceedings in Informatics (LIPIcs), Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik, vol 74. Dagstuhl, Germany, pp 4:1–4:29, 2017
Griebler D, Danelutto M, Torquati M, Fernandes LG (2017) SPar: a DSL for high-level and productive stream parallelism. Parallel Process Lett 27(01):1740005
Sujeeth AK, Brown KJ, Lee H, Rompf T, Chafi H, Odersky M, Olukotun K (2014) Delite: a compiler architecture for performance-oriented embedded domain-specific languages. ACM Trans Embed Comput Syst (TECS) 13(4s):134
Danelutto M, Torquati M, Kilpatrick P, (2016) A DSL based toolchain for design space exploration in structured parallel programming, Procedia Computer Science, vol 80, pp 1519–1530. In: International Conference on Computational Science 2016, ICCS 2016, San Diego, California, USA, 6–8 June 2016
Chamberlain BL, Callahan D, Zima HP (2007) Parallel programmability and the chapel language. Int J High Perform Comput Appl 21(3):291–312
Standard ISO (2015) Programming languages–technical specification for C++ extensions for parallelism, standard ISO/IEC TS 19570:2015. International Organization for Standardization, Geneva
Nugteren C, Corporaal H (2015) Bones: an automatic skeleton-based C-to-CUDA compiler for GPUs. ACM Trans Archit Code Optim (TACO) 11(4):35
Steuwer M, Fensch C, Lindley S, Dubach C (2015) Generating performance portable code using rewrite rules: from high-level functional expressions to high-performance OpenCL code. In: Proceedings of the 20th ACM SIGPLAN International Conference on Functional Programming, ICFP ’15. ACM, New York pp 205–217
Bettini L (2013) Implementing domain-specific languages with Xtext and Xtend. Community experience distilled. Packt Publishing, Birmingham
Wrede F, Rieger C (2018) Musket material repository. https://github.com/wwu-pi/musket-material. Accessed 26 Mar 2019
Eclipse foundation (2019) The eclipse foundation. Xtext documentation. https://eclipse.org/Xtext/documentation/. Accessed 26 Mar 2019
Kuchen H (2004) Optimizing sequences of skeleton calls. In: Lengauer C, Batory D, Consel C, Odersky M (eds) Domain-specific program generation. Lecture notes in computer science, vol 3016. Springer, Berlin, pp 254–274
Yoo AB, Jette MA, Grondona M (2003) SLURM: simple linux utility for resource management. In: Feitelson D, Rudolph L, Schwiegelshohn U (eds) Job scheduling strategies for parallel processing. Springer, Berlin, pp 44–60
Nethercote N, Seward J (2007) Valgrind: a framework for heavyweight dynamic binary instrumentation. In: Proceedings of the 28th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI ’07, ACM, New York, NY, USA, pp 89–100
Bastos-Filho CJA, de Lima Neto FB, Lins AJCC, Nascimento AIS, Lima MP (2008) A novel search algorithm based on fish school behavior. In: Proceedings of the IEEE International Conference on Systems, Man and Cybernetics (SMC ’08). IEEE, pp 2646–2651
Wrede F, Menezes B, Kuchen H (2018) Fish school search with algorithmic skeletons. Int J Parallel Program 47(2):234–252
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Wrede, F., Rieger, C. & Kuchen, H. Generation of high-performance code based on a domain-specific language for algorithmic skeletons. J Supercomput 76, 5098–5116 (2020). https://doi.org/10.1007/s11227-019-02825-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-019-02825-6