
Abstract
With the success of deep learning (DL) methods in diverse application domains, several deep learning software frameworks have been proposed to facilitate the usage of these methods. By knowing the frameworks which are employed in big data analysis, the analysis process will be more efficient in terms of time and accuracy. Thus, benchmarking DL software frameworks is in high demand. This paper presents a comparative study of deep learning frameworks, namely Caffe and TensorFlow on performance metrics: runtime performance and accuracy. This study is performed with several datasets, such as LeNet MNIST classification model, CIFAR-10 image recognition datasets and message passing interface (MPI) parallel matrix-vector multiplication. We evaluate the performance of the above frameworks when employed on machines of Intel Xeon Phi 7210. In this study, the use of vectorization, OpenMP parallel processing, and MPI are examined to improve the performance of deep learning frameworks. The experimental results show the accuracy comparison between the number of iterations of the test in the training model and the training time on the different machines before and after optimization. In addition, an experiment on two multi-nodes of Xeon Phi is performed. The experimental results also show the optimization of Xeon Phi is beneficial to the Caffe and TensorFlow frameworks.

















Similar content being viewed by others


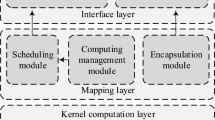
References
Ben-Nun T, Besta M, Huber S, Ziogas AN, Peter D, Hoefler T (2019) A modular benchmarking infrastructure for high-performance and reproducible deep learning. In: 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, pp 66–77
Blackford LS, Petitet A, Pozo R, Remington K, Whaley RC, Demmel J, Dongarra J, Duff I, Hammarling S, Henry G et al (2002) An updated set of basic linear algebra subprograms (blas). ACM Trans Math Softw 28(2):135–151
Bottleson J, Kim S, Andrews J, Bindu P, Murthy DN, Jin J (2016) Clcaffe: Opencl accelerated caffe for convolutional neural networks. In: Proceedings—2016 IEEE 30th International Parallel and Distributed Processing Symposium, IPDPS 2016, pp 50–57. www.scopus.com
Bottou L, Cortes C, Denker JS, Drucker H, Guyon I, Jackel LD, LeCun Y, Muller UA, Sackinger E, Simard P et al (1994) Comparison of classifier methods: a case study in handwritten digit recognition. In: Pattern Recognition, 1994. Vol 2-Conference B: Computer Vision & Image Processing. Proceedings of the 12th IAPR International. Conference on, vol 2. IEEE, pp. 77–82
Cifar10 (2017). https://www.cs.toronto.edu/~kriz/cifar.html
Coates A, Ng A, Lee H (2011) An analysis of single-layer networks in unsupervised feature learning. In: Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, pp 215–223
Dahl GE, Sainath TN, Hinton GE (2013) Improving deep neural networks for lvcsr using rectified linear units and dropout. In: 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, pp 8609–8613
Deng L, Liu Y (2018) Deep learning in natural language processing. Springer, Berlin
Docker (2019). https://www.docker.com/
Gold S, Rangarajan A et al (1996) Softmax to softassign: neural network algorithms for combinatorial optimization. J Artif Neural Netw 2(4):381–399
Gropp W, Lusk E, Doss N, Skjellum A (1996) A high-performance, portable implementation of the mpi message passing interface standard. Parallel Comput 22(6):789–828
Gropp W, Lusk E, Skjellum A (1999) Using MPI: portable parallel programming with the message-passing interface, vol 1. MIT Press, Cambridge
Gropp W, Lusk E, Thakur R (1999) Using MPI-2: advanced features of the message-passing interface. MIT Press, Cambridge
Grupp A, Kozlov V, Campos I, David M, Gomes J, García Á L (2019) Benchmarking deep learning infrastructures by means of tensorflow and containers. In: International Conference on High Performance Computing. Springer, pp 478–489
Hacker SK (2018) Mastering docker: a quick-start beginner’s guide. CreateSpace Independent Publishing Platform. https://dl.acm.org/doi/book/10.5555/3235203
Han J, Zhang D, Cheng G, Liu N, Xu D (2018) Advanced deep-learning techniques for salient and category-specific object detection: a survey. IEEE Signal Process Mag 35(1):84–100
Han S, Pool J, Tran J, Dally W (2015) Learning both weights and connections for efficient neural network. In: Advances in Neural Information Processing Systems, pp 1135–1143
Hegde G, Ramasamy N, Kapre N et al (2016) Caffepresso: an optimized library for deep learning on embedded accelerator-based platforms. In: 2016 International Conference on Compliers, Architectures, and Sythesis of Embedded Systems (CASES). IEEE, pp 1–10
Jia Y, Shelhamer E, Donahue J, Karayev S, Long J, Girshick R, Guadarrama S, Darrell T (2014) Caffe: convolutional architecture for fast feature embedding. In: MM 2014—Proceedings of the 2014 ACM Conference on Multimedia, pp 675–678. www.scopus.com
Kim Y (2014) Convolutional neural networks for sentence classification. arXiv preprint arXiv:1408.5882
Kristiani E, Yang CT, Wang YT, Huang CY, Ko PC (2018) Container-based virtualization for real-time data streaming processing on the edge computing architecture. In: International Wireless Internet Conference. Springer, pp 203–211
Krizhevsky A, Hinton G (2010) Convolutional deep belief networks on cifar-10. Unpublished manuscript 40
Kurth T, Smorkalov M, Mendygral P, Sridharan S, Mathuriya A (2018) Tensorflow at scale: performance and productivity analysis of distributed training with horovod, mlsl, and cray pe ml. Concurrency and Computation: Practice and Experience, p e4989
Liu W, Wang Z, Liu X, Zeng N, Liu Y, Alsaadi FE (2017) A survey of deep neural network architectures and their applications. Neurocomputing 234:11–26
Liu L, Ouyang W, Wang X, Fieguth P, Chen J, Liu X, Pietikäinen M (2020) Deep learning for generic object detection: a survey. Int J Comput Vis 128(2):261–318
Liu L, Wu Y, Wei W, Cao W, Sahin S, Zhang Q (2018) Benchmarking deep learning frameworks: design considerations, metrics and beyond. In: 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS). IEEE, pp 1258–1269
Luong NC, Hoang DT, Gong S, Niyato D, Wang P, Liang YC, Kim DI (2019) Applications of deep reinforcement learning in communications and networking: a survey. IEEE Commun Surv Tutor 21(4):3133–3174
Nair V, Hinton GE (2010) Rectified linear units improve restricted Boltzmann machines. In: Proceedings of the 27th International Conference on Machine Learning (ICML-10), pp 807–814
Nassif AB, Shahin I, Attili I, Azzeh M, Shaalan K (2019) Speech recognition using deep neural networks: a systematic review. IEEE Access 7:19143–19165
Nath R, Tomov S, Dongarra J (2010) Accelerating GPU kernels for dense linear algebra. In: VECPAR. Springer, pp 83–92
Openmpi (2017). https://www.open-mpi.org/
Panda DK, Awan AA, Subramoni H (2019) High performance distributed deep learning: a beginner’s guide. In: PPoPP, pp 452–454
Purushotham S, Meng C, Che Z, Liu Y (2018) Benchmarking deep learning models on large healthcare datasets. J Biomed Inform 83:112–134
Rosales C (2014) Porting to the intel xeon phi: opportunities and challenges. In: Proceedings—2013 Extreme Scaling Workshop, XSW 2013, pp 1–7. www.scopus.com
Roska T, Hamori J, Labos E, Lotz K, Orzó L, Takacs J, Venetianer PL, Vidnyanszky Z, Zarándy Á (1993) The use of cnn models in the subcortical visual pathway. IEEE Trans Circuits Syst I Fundam Theory Appl 40(3):182–195
Soheil B, Naveen R, Lukas S, et al (2016) Comparative study of deep learning software frameworks. arXiv preprint arXiv:1511.06435
Tanno R, Yanai K (2016) Caffe2c: a framework for easy implementation of cnn-based mobile applications. In: ACM International Conference Proceeding Series, vol 28-November-2016, pp 159–164. www.scopus.com
Tarasov V, Rupprecht L, Skourtis D, Li W, Rangaswami R, Zhao M (2019) Evaluating docker storage performance: from workloads to graph drivers. Cluster Computing pp 1–14
Tensorflow description (2019). https://www.tensorflow.org/
Tokic M, Palm G (2011) Value-difference based exploration: adaptive control between epsilon-greedy and softmax. KI 2011: Advances in Artificial Intelligence, pp 335–346
Venkateswaran S, Sarkar S (2019) Fitness-aware containerization service leveraging machine learning. IEEE Trans Serv Comput. https://doi.org/10.1109/TSC.2019.2898666
Voulodimos A, Doulamis N, Doulamis A, Protopapadakis E (2018) Deep learning for computer vision: a brief review. Comput Intell Neurosci. https://doi.org/10.1155/2018/7068349
Wang H, Zhang L, Han J, Weinan E (2018) Deepmd-kit: a deep learning package for many-body potential energy representation and molecular dynamics. Comput Phys Commun 228:178–184
Xbyak (2017). https://github.com/herumi/xbyak
Yang CT, Liu JC, Chan YW, Kristiani E, Kuo CF (2018) On construction of a caffe deep learning framework based on intel xeon phi. In: International Conference on P2P, Parallel, Grid, Cloud and Internet Computing. Springer, pp 96–106
Yang CT, Huang CL, Lin CF (2011) Hybrid CUDA, OpenMP, and MPI parallel programming on multicore GPU clusters. Comput Phys Commun 182(1):266–269
Zarándy Á, Orzó L, Grawes E, Werblin F (1999) CNN-based models for color vision and visual illusions. IEEE Trans Circuits Syst I Fundam Theory Appl 46(2):229–238
Zhang Z, Geiger J, Pohjalainen J, Mousa AED, Jin W, Schuller B (2018) Deep learning for environmentally robust speech recognition: an overview of recent developments. ACM TIST 9(5):1–28
Zhao ZQ, Zheng P, Xu St, Wu X (2019) Object detection with deep learning: a review. IEEE Trans Neural Netw Learn Syst 30(11):3212–3232
Acknowledgements
This work was supported by the Ministry of Science and Technology, Taiwan (R.O.C.), under Grant Number 108-2221-E-029-010-.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Yang, CT., Liu, JC., Chan, YW. et al. Performance benchmarking of deep learning framework on Intel Xeon Phi. J Supercomput 77, 2486–2510 (2021). https://doi.org/10.1007/s11227-020-03362-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-020-03362-3