
Abstract
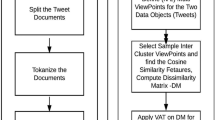
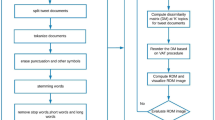
Visual methods were used for pre-cluster assessment and useful cluster partitions. Existing visual methods, such as visual assessment tendency (VAT), spectral VAT (SpecVAT), cosine-based VAT (cVAT), and multi-viewpoints cosine-based similarity VAT (MVS-VAT), effectively assess the knowledge about the number of clusters or cluster tendency. Tweets data partitioning is underlying the problem of social data clustering. Cosine-based visual methods succeeded widely in text data clustering. Thus, cVAT and MVS-VAT are the best suited methods for the derivation of social data clusters. However, MVS-VAT is facing the problem of scalability issues in terms of computational time and memory allocation. Therefore, this paper presents the sampling-based MVS-VAT computing technique to overcome the scalability problem in social data clustering to select sample inter-cluster viewpoints. Standard health keywords and benchmarked TREC2017 and TREC2018 health keywords are taken to extract health tweets in the experiment for illustrating the performance comparison between existing and proposed visual methods.










Similar content being viewed by others

References
Lin YS, Jiang JY, Lee SJ (2014) A similarity measure for text classification and clustering. IEEE Trans Knowledge Data Eng (2014)
Rui X, Wunsch D (2005) Survey of clustering algorithms. IEEE Trans Neural Netw 16(3):645–678
Rajendra Prasad K, Suleman Basha M (2016) Improving the performance of speech clustering method. In: IEEE 10th International Conference on Intelligent Systems and Control (ISCO).
Wu X, Kumar V, Quinlan JR et al (2008) Top 10 algorithms in data mining, knowledge information system, vol 14. Springer, Heidelberg, pp 1–37.
Sik-Lanyi et al (2019) Accessibility testing of European health-related websites. Arab J Sci Eng 44:9171–9190
Ramathilagam S, Devi R, Kannan SR (2013) Extended fuzzy c-means: an analyzing data clustering problems. Cluster Comput
Feng Yi, Bo Jiang, Jianjun Wu (2020) Topic modeling for short texts via word embedding and document correlation. IEEE Access 8:30692–30705
Lee D, Seung H (2000) Algorithms for non-negative matrix factorization. Advances in neural information processing systems 13, NIPS 2000. Denver, CO, USA, pp 556–562
Blei DM, Ng AY, Jordan MI (2003) Latent Dirichlet allocation. J Mach Learn Res 3:993–1022
Deerwester S, Dumais ST, Furnas GW, Landauer TK, Harshman R (1990) Indexing by latent semantic analysis. J Am Soc Inf Sci 41(6):391–407
T Hofmann (1999) Probabilistic latent semantic indexing. SIGIR. ACM, New York, pp 50–57
Xu G, Meng Y, Chen Z, Qiu X, Wang C, Yao H (2019) Research on topic detection and tracking for online news texts. IEEE Access 7:58407–58418
Bezdek JC, Hathaway RJ (2002) VAT: a tool for visual assessment of (cluster) tendency. In: Proceedings of the 2002 International Joint Conference on Neural Networks. IJCNN'02, 2002, pp 2225–2230
Bezdek, James Leckie (2008) SpecVAT: enhanced visual cluster analysis. IEEE Int Conf Data Mining, ICDM
Rajendra Prasad K, Mohammed M, Noorullah RM (2019) Visual topic models for healthcare data clustering. Evolutionary Intelligence.
Rajendra Prasad K, Mohammed M, Noorullah RM (2019) Hybrid topic cluster models for social healthcare data. Int J Adv Comput Sci Appl 10(11):490–506.
Ali Seyed Shirkhorshidi, Saeed Aghabozorgi, Teh Ying Wah (2015) A comparison study on similarity and dissimilarity measures in clustering continuous data. PLoS 10(12):1–20
Suleman Basha M, Mouleeswaran SK, Rajendra Prasad K (2019) Cluster tendency methods for visualizing the data partitions. Int J Innovative Technol Explor Eng.
Vijeya Kaveri V, Maheswari V (2019) A framework for recommending health-related topics based on topic modeling in conversational data (Twitter). Cluster Computing.
Asghar MZ et al (2018) RIFT: a rule induction framework for twitter sentiment analysis. Arab J Sci Eng 43:857–877
Kumar D, Bezdek JC, Palaniswami M, Rajasegarar S, Leckie C, Havens TC (2016) A hybrid approach to clustering in big data. IEEE Trans Cybern 46(10):2372–2385
Kumar D, Palaniswami M, Rajasegarar S, Leckie C, Bezdek JC, Havens TC (2013) clusiVAT: A mixed visual/numerical clustering algorithm for big data. 2013 IEEE International Conference on Big Data, Silicon Valley, CA, 2013, pp 112–117.
Wuhan (2018) TF-IDF based feature words extraction and topic modeling for short text. In: ICMSS2018.
Wallach, Hanna M (2006) Topic modeling: beyond bag-of-words, ACM International Conference Proceeding Series, 2006
Alessia Amelio, Clara Pizzuti (2015) Is normalized mutual information a fair measure for comparing community detection methods?. IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, 2015.
Bodjanova S (2006) Crisp partitions Induced by a fuzzy set. In: Batagelj V, Bock HH, Ferligoj A., Žiberna A (eds) Data science and classification. Studies in classification, data analysis, and knowledge organization. Springer, Berlin (2006)
Pattanodom et al. (2016) Clustering data with the presence of missing values by ensemble approach. In: Second Asian Conference on Defense Technology.
Bhatnagar V, Majhi R, Jena PR (2018) Comparative performance evaluation of clustering algorithms for grouping manufacturing firms. Arab J Sci Eng 43:4071–4083
Acknowledgment
This work is supported by the Science & Engineering Research Board (SERB), Department of Science and Technology, Government of India for the Research Grant of DST Project Number ECR/2016/001556.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Basha, M.S., Mouleeswaran, S.K. & Prasad, K.R. Sampling-based visual assessment computing techniques for an efficient social data clustering. J Supercomput 77, 8013–8037 (2021). https://doi.org/10.1007/s11227-021-03618-6
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-021-03618-6