
Abstract
CNNs have achieved remarkable image classification and object detection results over the past few years. Due to the locality of the convolution operation, although CNNs can extract rich features of the object itself, they can hardly obtain global context in images. It means the CNN-based network is not a good candidate for detecting objects by utilizing the information of the nearby objects, especially when the partially obscured object is hard to detect. ViTs can get a rich context and dramatically improve the prediction in complex scenes with multi-head self-attention. However, it suffers from long inference time and huge parameters, which leads ViT-based detection network that is hardly be deployed in the real-time detection system. In this paper, firstly, we design a novel plug-and-play attention module called mix attention (MA). MA combines channel, spatial and global contextual attention together. It enhances the feature representation of individuals and the correlation between multiple individuals. Secondly, we propose a backbone network based on mix attention called MANet. MANet-Base achieves the state-of-the-art performances on ImageNet and CIFAR. Last but not least, we propose a lightweight object detection network called CAT-YOLO, where we make a trade-off between precision and speed. It achieves the AP of 25.7% on COCO 2017 test-dev with only 9.17 million parameters, making it possible to deploy models containing ViT on hardware and ensure real-time detection. CAT-YOLO could better detect obscured objects than other state-of-the-art lightweight models.













Similar content being viewed by others
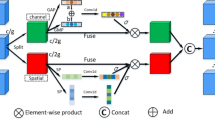
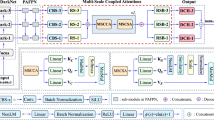

Data availability
The datasets used and/or analyzed during the current study are available from their official websites and corresponding author on a reasonable request.
References
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 770–778
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. preprint arXiv:1409.1556
Tan M, Le Q (2019) Efficientnet: Rethinking model scaling for convolutional neural networks. In: International Conference on Machine Learning, PMLR, pp 6105–6114
Ren S, He K, Girshick R, Sun J (2015) Faster r-cnn: towards real-time object detection with region proposal networks. Advances in neural information processing systems. 28
Redmon J, Farhadi A (2018) Yolov3: an incremental improvement. Preprint arXiv:1804.02767
Bochkovskiy A, Wang C-Y, Liao H-YM (2020) Yolov4: optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934
Jocher G (2021) YOLOv5. https://github.com/ultralytics/yolov5
Ge Z, Liu S, Wang F, Li Z, Sun J (2021) Yolox: exceeding yolo series in 2021. Preprint arXiv:2107.08430
Shao R, Shi Z, Yi J, Chen P-Y, Hsieh C-J (2021) On the adversarial robustness of visual transformers. arXiv e-prints, 2103
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, et al (2020) An image is worth 16x16 words: transformers for image recognition at scale. Preprint arXiv:2010.11929
Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, Lin S, Guo B (2021) Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp 10012–10022
Chu X, Tian Z, Wang Y, Zhang B, Ren H, Wei X, Xia H, Shen,C (2021) Twins: revisiting the design of spatial attention in vision transformers. Advances in Neural Information Processing Systems, 34
Touvron H, Cord M, Douze M, Massa F, Sablayrolles, A, Jégou H (2021) Training data-efficient image transformers & distillation through attention. In: International Conference on Machine Learning, PMLR, pp 10347–10357
Yuan K, Guo S, Liu Z, Zhou A, Yu F, Wu W (2021) Incorporating convolution designs into visual transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp 579–588
Han K, Xiao A, Wu E, Guo J, Xu C, Wang Y (2021) Transformer in transformer. Advances in Neural Information Processing Systems, 34
Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S (2020) End-to-end object detection with transformers. In: European Conference on Computer Vision, Springer, pp 213–229
Fang Y, Liao B, Wang X, Fang J, Qi J, Wu R, Niu J, Liu W (2021) You only look at one sequence: rethinking transformer in vision through object detection. Advances in Neural Information Processing Systems, 34
Zhu X, Su W, Lu L, Li B, Wang X, Dai J (2020) Deformable detr: deformable transformers for end-to-end object detection. Preprint arXiv:2010.04159
Hu J, Shen L, Sun G (2018) Squeeze-and-excitation networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 7132–7141
Li X, Wang W, Hu X, Yang J (2019) Selective kernel networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 510–519
Woo S, Park J, Lee J-Y, Kweon IS (2018) Cbam: Convolutional block attention module. In: Proceedings of the European Conference on Computer Vision (ECCV), pp 3–19
Ramchoun H, Ghanou Y, Ettaouil M, Janati Idrissi MA (2016) Multilayer perceptron: architecture optimization and training
Saeed F, Paul A, Rho S (2020) Faster r-cnn based fault detection in industrial images. In: International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Springer, pp 280–287
Rathore MM, Paul A, Rho S, Khan M, Vimal S, Shah SA (2021) Smart traffic control: identifying driving-violations using fog devices with vehicular cameras in smart cities. Sustain Cities Soc 71:102986
Nawaz H, Maqsood M, Afzal S, Aadil F, Mehmood I, Rho S (2021) A deep feature-based real-time system for alzheimer disease stage detection. Multimed Tools Appl 80(28):35789–35807
Robinson YH, Vimal S, Julie EG, Lakshmi Narayanan K, Rho S (2021) 3-dimensional manifold and machine learning based localization algorithm for wireless sensor networks. Wireless Personal Communications, 1–19
Fan S, Wang R, Wu Z, Rho S, Liu S, Xiong J, Fu S, Jiang F (2021) High-speed tracking based on multi-cf filters and attention mechanism. SIViP 15(4):663–671
Girshick R, Donahue J, Darrell T, Malik J (2014) Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 580–587
Girshick R (2015) Fast r-cnn. In: Proceedings of the IEEE International Conference on Computer Vision, pp 1440–1448
Redmon J, Divvala S, Girshick R, Farhadi A (2016) You only look once: Unified, real-time object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 779–788
Redmon J, Farhadi A (2017) Yolo9000: better, faster, stronger. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 7263–7271
Liu S, Qi L, Qin H, Shi J, Jia J (2018) Path aggregation network for instance segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 8759–8768
Zhang H, Cisse M, Dauphin YN, Lopez-Paz D (2017) mixup: Beyond empirical risk minimization. Preprint arXiv:1710.09412
Yun S, Han D, Oh SJ, Chun S, Choe J, Yoo Y (2019) Cutmix: Regularization strategy to train strong classifiers with localizable features. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp 6023–6032
Zheng Z, Wang P, Liu W, Li J, Ye R, Ren D (2020) Distance-iou loss: Faster and better learning for bounding box regression. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol 34, pp 12993–13000
Müller R, Kornblith S, Hinton GE (2019) When does label smoothing help? Advances in neural information processing systems, 32
Tan Z, Wang J, Sun X, Lin M, Li H, et al (2021) Giraffedet: A heavy-neck paradigm for object detection. In: International Conference on Learning Representations
Dai J, Qi H, Xiong Y, Li Y, Zhang G, Hu H, Wei Y (2017) Deformable convolutional networks. In: Proceedings of the IEEE International Conference on Computer Vision, pp 764–773
Paul S, Chen P-Y (2021) Vision transformers are robust learners. Preprint<error l="301" c="bad csname" />arXiv:2105.075812(3)
Naseer MM, Ranasinghe K, Khan SH, Hayat M, Shahbaz Khan F, Yang M-H (2021) Intriguing properties of vision transformers. Advances in Neural Information Processing Systems, 34
Srinivas A, Lin T-Y, Parmar N, Shlens J, Abbeel P, Vaswani A (2021) Bottleneck transformers for visual recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 16519–16529
Chen Z, Xie L, Niu J, Liu X, Wei L, Tian Q (2021) Visformer: The vision-friendly transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp 589–598
Wang Q, Wu B, Zhu P, Li P, Zuo W, Hu Q Supplementary material for ‘eca-net: Efficient channel attention for deep convolutional neural networks. Technical report
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser, Ł, Polosukhin I (2017) Attention is all you need. Advances in neural information processing systems, 30
Park N, Kim S (2022) How do vision transformers work? Preprint arXiv:2202.06709
Misra D (2019) Mish: A self regularized non-monotonic activation function. Preprint arXiv:1908.08681
Lin T-Y, Dollár P, Girshick R, He K, Hariharan B, Belongie S (2017) Feature pyramid networks for object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 2117–2125
He K, Zhang X, Ren S, Sun J (2015) Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans Pattern Anal Mach Intell 37(9):1904–1916
Deng J, Dong W, Socher R, Li L-J, Li K, Fei-Fei L (2009) Imagenet: A large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, pp 248–255
Krizhevsky A, Hinton G, et al (2009) Learning multiple layers of features from tiny images
Le Y, Yang X (2015) Tiny imagenet visual recognition challenge. CS 231N 7(7):3
Hassani A, Walton S, Shah N, Abuduweili A, Li J, Shi H (2021) Escaping the big data paradigm with compact transformers. Preprint arXiv:2104.05704
Zagoruyko S, Komodakis N (2016) Wide residual networks. Preprint arXiv:1605.07146
Lin T-Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick CL (2014) Microsoft coco: Common objects in context. In: European Conference on Computer Vision, Springer, pp 740–755
RangiLyu (2021) NanoDet-Plus: Super fast and high accuracy lightweight anchor-free object detection model. https://github.com/RangiLyu/nanodet
Acknowledgements
The authors acknowledge XJTLU-JITRI Academy of Industrial Technology for giving the valuable support of the joint project. The authors also acknowledge Mr. Wenhan Tao for the support of GPU resources.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Guan, R., Man, K.L., Zhao, H. et al. MAN and CAT: mix attention to nn and concatenate attention to YOLO. J Supercomput 79, 2108–2136 (2023). https://doi.org/10.1007/s11227-022-04726-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-022-04726-7