
Abstract
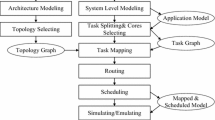
On-chip networks (NoCs) have become a popular choice for designing large multiprocessor architectures. Software-based emulation is often used to perform the design verification. However, if the considered design is sufficiently large, software-based emulation becomes impractically slow. To avoid this limitation, multi-FPGA emulation was introduced, where multiple interconnected FPGAs collectively emulate a single circuit. The number of external FPGA pins is often insufficient for emulating large network-on-chip designs accurately. As a result, the overall emulation frequency has to be severely limited. We propose a method for accelerating multi-FPGA emulation by reducing the amount of data FPGAs need to transmit to each other. To achieve cycle-accurate emulation in the absence of constant transmission latency, synchronous messaging is implemented. The proposed method was tested on a functioning prototype. It is shown that the use of our method for multi-FPGA emulation of large NoC designs can reach several orders.











Similar content being viewed by others


Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.Data availability
The software associated with this article is freely available at https://github.com/alerner-6502/NoC_partitioner/
References
Sodani A, Gramunt R, Corbal J, Kim H-S et al (2016) Knights landing: second-generation Intel Xeon phi product. IEEE Micro 36(2):34–46. https://doi.org/10.1109/MM.2016.25
Sepúlveda J, Marangozova-Martin V, Castrillon J (2017) Architecture, languages, compilation and hardware support for emerging manycore systems (alchemy): preface. Proced Comput Sci 108:1071–1072. https://doi.org/10.1016/j.procs.2017.05.276
Abdallah L, Jan M, Ermont J, Fraboul C (2016) Reducing the Contention Experienced by Real-Time Core-to-I/O Flows over a Tilera-Like Network on Chip. In: 28th Euromicro Conference on Real-Time Systems (ECRTS), pp 86–96. https://doi.org/10.1109/ECRTS.2016.9
Somasundaram K (2020) Design of a virtual channel router architecture for low power on mesh-of-grid topology for network on Chip. Applied Soft Computing and Communication Networks: Proceedings of ACN 2019. Springer, Singapore, pp 63–79. https://doi.org/10.1007/978-981-15-3852-0_5
Rocki K, Van Essendelft D, Sharapov I, Schreiber R et al (2020) Fast stencil-Code computation on a wafer-scale processor. In: SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pp 1–14. https://doi.org/10.1109/SC41405.2020.00062
Ditzel D, Espasa R, Aymerich N, Baum A et al (2021) Accelerating ML Recommendation with over a thousand RISC-V/tensor processors on Esperanto’s ET-SoC-1 Chip. In: IEEE Hot Chips 33 Symposium (HCS), pp 1–23. https://doi.org/10.1109/HCS52781.2021.9566904
Wolkotte PT, Holzenspies PKF, Smit GJM (2007) Fast, accurate and detailed NoC simulations. In: First International Symposium on Networks-on-Chip (NOCS'07), pp 323–332. https://doi.org/10.1109/NOCS.2007.18
Jain A, Kumar A, Shukla AP, Alshazly H et al (2022) Smart communication using 2d and 3d mesh network-on-chip. Intell Autom Soft Comput 34(3):2007–2021. https://doi.org/10.32604/iasc.2022.024770
Romanov A, Ivannikov A (2018) SystemC Language Usage as the Alternative to the HDL and High-level Modeling for NoC Simulation. Int. J. Embed Real Time Commun Syst 9(2):18–31. https://doi.org/10.4018/IJERTCS.2018070102
Jallouli K, Mazouzi M, Diguet J-P, Monemi A, Hasnaoui S (2022) MIMO-OFDM LTE system based on a parallel IFFT/FFT on NOC-based FPGA. Ann Telecommun 77(9–10):689–702. https://doi.org/10.1007/s12243-021-00901-8
Kouadri-Mostefaoui A-M, Senouci B, Petrot F (2007) Scalable multi-FPGA platform for networks-on-chip emulation. In: IEEE International Conf on Application-specific Systems, Architectures and Processors (ASAP), pp 54–60. https://doi.org/10.1109/ASAP.2007.4429958
Dorai A, Sentieys O, Dubois H (2017) Evaluation of NoC on multi-FPGA interconnection using GTX transceiver. In: 24th IEEE International Conference on Electronics, Circuits and Systems (ICECS), pp 170–173. https://doi.org/10.1109/ICECS.2017.8292007
Yangfan L, Peng L, Yingtao J, Mei Y et al (2010) Building a multi-FPGA-based emulation framework to support networks-on-chip design and verification. Int J Electron 97:1241–1262. https://doi.org/10.1080/00207217.2010.512017
Umer F, Bander A (2020) Exploring and optimizing partitioning of large designs for multi-FPGA based prototyping platforms. Computing 102:2361–2383. https://doi.org/10.1007/s00607-020-00834-5
Tang Q, Mehrez H, Tuna M (2012) Design for prototyping of a parameterizable cluster-based multi-core system-on-chip on a multi-FPGA board. In: 23rd IEEE International Symposium on Rapid System Prototyping (RSP), pp 71–77. https://doi.org/10.1109/RSP.2012.6380693
Dreschmann M, Heisswolf J, Geiger M, Becker J, HauBecker M (2015) A framework for multi-FPGA interconnection using multi gigabit transceivers. In: 28th Symposium on Integrated Circuits and Systems Design (SBCCI), pp 1–6. https://doi.org/10.1145/2800986.2800993
Kouadri-Mostefaoui, Abdellah-Medjadji, Senouci B, Petrot F (2008) Large scale on-chip networks: an accurate multi-FPGA emulation platform. In: 11th EUROMICRO Conference on Digital System Design Architectures, Methods and Tools, pp 3–9.https://doi.org/10.1109/DSD.2008.130
Junyan T, Virginie F, Frederic R (2012) From mono-FPGA to multi FPGA emulation platform for NoC performance evaluations. Adv Parallel Comput 22:603–610. https://doi.org/10.3233/978-1-61499-041-3-603
Farooq U, Chotin-Avot R, Azeem M, Ravoson M et al (2016) Inter-FPGA routing environment for performance exploration of multi-FPGA systems. In: International Symposium on Rapid System Prototyping (RSP), pp 1–7. https://doi.org/10.1145/2990299.2990317
Azeem MM, Chotin-Avot R, Farooq U, Ravoson M, Mehrez H (2016) Multiple FPGAs based prototyping and debugging with complete design flow. In: 2016 11th International Design & Test Symposium (IDT), pp 171–176. https://doi.org/10.1109/IDT.2016.7843035
Junyan T, Virginie F, Frederic R (2016) Rapid prototyping of Networks-on-Chip on multi-FPGA platforms. In: MATEC Web of Conferences, pp 12002. https://doi.org/10.1051/matecconf/20165412002
Tang Q (2015) Methodology of multi-FPGA prototyping platform generation. Dissertation, Pierre and Marie Curie Univ
Lezhnev EV, Zunin VV, Amerikanov AA, Romanov AY (2024) Electronic computer-aided design for low-level modeling of networks-on-chip. IEEE Access 12:48750–48763. https://doi.org/10.1109/ACCESS.2024.3382710
Li Y, Zhou P (2023) Fast and accurate noc latency estimation for application-specific traffics via machine learning. IEEE Trans Circuits Syst II Express Briefs 70:3569–3573. https://doi.org/10.1109/TCSII.2023.3258700
Mandal SK, Krishnakumar A, Ayoub R, et al (2020) Performance analysis of priority-aware NoCs with deflection routing under traffic congestion. In: Proceedings of the 39th International Conference on Computer-Aided Design. ACM, New York, NY, USA, pp 1–9. https://doi.org/10.1145/3400302.3415654
Pereira RVM, Seman LO, Berejuck MD et al (2021) MPI hardware framework for many-core based embedded systems. Int J Sens Networks 35:42. https://doi.org/10.1504/IJSNET.2021.112888
Kumar AS, Rao TVKH (2022) Performance assessment of adaptive core mapping for NoC-based architectures. Int J Embed Syst 15:395. https://doi.org/10.1504/IJES.2022.127149
Kumar AS, Rao TVKH (2020) Scalable benchmark synthesis for performance evaluation of NoC core mapping. Microprocess Microsyst 79:103272. https://doi.org/10.1016/j.micpro.2020.103272
Montanana JM, De Andres D, Tirado F (2013) Fault tolerance on NoCs. In: 27th International Conference on Advanced Information Networking and Applications Workshops. pp 138–143. https://doi.org/10.1109/WAINA.2013.221
Benmessaoud Gabis A, Koudil M (2016) NoC routing protocols – objective-based classification. J Syst Archit 66–67:14–32. https://doi.org/10.1016/j.sysarc.2016.04.011
Trik M, Pour Mozaffari S, Bidgoli AM (2021) Providing an adaptive routing along with a hybrid selection strategy to increase efficiency in NoC-based neuromorphic systems. Comput Intell Neurosci 2021:1–8. https://doi.org/10.1155/2021/8338903
Abd El ghany MA, El-Moursy MA, Ismail M (2009) High throughput architecture for high performance NoC. In: 2009 IEEE International Symposium on Circuits and Systems. IEEE, pp 2241–2244. https://doi.org/10.1109/ISCAS.2009.5118244
Funding
This article is an output of a research project implemented as part of the Basic Research Program at the National Research University Higher School of Economics (HSE University).
Author information
Authors and Affiliations
Contributions
Conceptualization was done by A.Y.R., A.L., and A.A.A.; methodology was done by A.Y.R.; validation was done by A.Y.R. and A.L.; writing—original draft preparation was done by A.Y.R. and A.L.; writing—review and editing was done by A.A.A. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Ethical approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Romanov, A.Y., Lerner, A. & Amerikanov, A.A. Cycle-accurate multi-FPGA platform for accelerated emulation of large on-chip networks. J Supercomput 80, 22462–22478 (2024). https://doi.org/10.1007/s11227-024-06306-3
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-024-06306-3