
Abstract
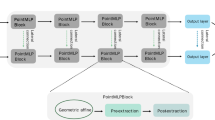
The field of point cloud analysis has made significant advancements due to the propulsion of deep learning. The transformer model has sparked a revolutionary change in point cloud learning tasks. However, its quadratic complexity limits its scalability in processing long sequences and strains on limited computational resources. In this paper, we introduce PointUltra, an innovative hybrid framework based on Mamba that diverges from traditional transformer-based methods. PointUltra employs a linear complexity algorithm, which significantly reduces computational costs while demonstrating robust global modeling capabilities. Specifically, we propose UltraX, a spatially coherent traversal serialization strategy that efficiently converts complex 3D point cloud data into ordered 1D sequences. This processed data allow the Mamba encoder to effectively extract intergroup global features from each point cloud sample, ensuring comprehensive global analysis. Unlike previous Mamba methods, our UltraX serialization strategy overcomes the challenges of random and coordinate-based serialization. This strategy preserves point adjacency and spatial relationships in point clouds. Experimental results also validate the effectiveness of our approach, achieving an accuracy of 92.3% on the ScanObjectNN variant OBJ-BG, 94.2% accuracy on ModelNet40, and an ins.mIoU of 86.8% on the ShapeNetPart dataset, while significantly saving about 25% of FLOPs.









Similar content being viewed by others


Data availability
No datasets were generated or analyzed during the current study.
References
Cheng R, Zeng H, Zhang B, Wang X, Zhao T (2023) FFA-Net: fast feature aggregation network for 3D point cloud segmentation. Mach Vis Appl 34(5):80
Sun L, Li Y, Qin W (2024) PEPillar: a point-enhanced pillar network for efficient 3D object detection in autonomous driving. Vis Comput 1–12
Zhu L, Liao B, Zhang Q, Wang X, Liu W, Wang X (2024) Vision mamba: efficient visual representation learning with bidirectional state space model. Preprint at arXiv:2401.09417
Chatterjee J, Vega MT (2024) 3D-scene-former: 3D scene generation from a single RGB image using transformers. Vis Comput 1–15
Yu X, Tang L, Rao Y, Huang T, Zhou J, Lu J (2022) Point-Bert: pre-training 3d point cloud transformers with masked point modeling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp 19313–19322
Pang Y, Wang W, Tay FE, Liu W, Tian Y, Yuan L (2022) Masked autoencoders for point cloud self-supervised learning. In: European Conference on Computer Vision. Springer, pp 604–621
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Polosukhin I (2017) Attention is all you need. In: Advances in neural information processing systems. vol 30
Yang Y, Xing Z, Zhu L (2024) Vivim: a video vision mamba for medical video object segmentation. Preprint at arXiv:2401.14168
Gu A, Johnson I, Goel K, Saab K, Dao T, Rudra A, Ré C (2021) Combining recurrent, convolutional, and continuous-time models with linear state space layers. Adv Neural Inf Process Syst 34:572–585
He W, Han K, Tang Y, Wang C, Yang Y, Guo T, Wang Y (2024) Densemamba: State space models with dense hidden connection for efficient large language models. Preprint at arXiv:2403.00818
Gu A, Goel K, Re C (2021) Efficiently modeling long sequences with structured state spaces. In: Proceedings of the International Conference on Learning Representations
Wu C, Zheng J, Pfrommer J, Beyerer J (2023) Attention-based point cloud edge sampling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp 5333–5343
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S et al (2021) An image is worth 16x16 words: transformers for image recognition at scale. In: Proceedings of the International Conference on Learning Representations
Liang D, Zhou X, Wang X, Zhu X, Xu W, Zou Z, Ye X, Bai X (2024) Pointmamba: a simple state space model for point cloud analysis. Preprint at arXiv:2402.10739
Qi CR, Su H, Mo K, Guibas LJ (2017) Pointnet: deep learning on point sets for 3d classification and segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp 652–660
Huang T, Zou H, Cui J, Zhang J, Yang X, Li L, Liu Y (2022) Adaptive recurrent forward network for dense point cloud completion. IEEE Trans Multimed 25:5903–5915
Deng X, Zhang W, Ding Q, Zhang X (2023) PointVector: a vector representation in point cloud analysis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp 9455–9465
Huang T, Zhang J, Chen J, Ding Z, Tai Y, Zhang Z, Wang C, Liu Y (2022) 3QNet: 3d point cloud geometry quantization compression network. ACM Trans Graph (TOG) 41(6):1–13
Huang T, Ding Z, Zhang J, Tai Y, Zhang Z, Chen M, Wang C, Liu Y (2023) Learning to measure the point cloud reconstruction loss in a representation space. In: CVPR. p 3
Qi CR, Yi L, Su H, Guibas LJ (2017) Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In: Advances in neural information processing systems. vol 30
Choy C, Gwak J, Savarese S (2019) 4d spatio-temporal convnets: Minkowski convolutional neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp 3075–3084
Li Y, Bu R, Sun M, Wu W, Di X, Chen B (2018) PointCNN: convolution on X-transformed points. Adv Neural Inf Process Syst 31:1–37815
Zhao H, Jiang L, Fu C-W, Jia J (2019) Pointweb: Enhancing local neighborhood features for point cloud processing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5565–5573
Komarichev A, Zhong Z, Hua J (2019) A-CNN: annularly convolutional neural networks on point clouds. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp 7421–7430
Qian G, Li Y, Peng H, Mai J, Hammoud H, Elhoseiny M, Ghanem B (2022) PointNeXt: revisiting PointNet++ with improved training. Adv Neural Inf Process Syst 35:23192–23204
Wu W, Qi Z, Fuxin L (2019) PointConv: deep convolutional networks on 3D point clouds. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp 9621–9630
He Q, Wang Z, Zeng H, Zeng Y, Liu Y (2022) Svga-net: sparse voxel-graph attention network for 3d object detection from point clouds. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol 36, pp 870–878
Landrieu L, Simonovsky M (2018) Large-scale point cloud semantic segmentation with superpoint graphs. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp 4558–4567
Shen Y, Feng C, Yang Y, Tian D (2018) Mining point cloud local structures by kernel correlation and graph pooling. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp 4548–4557
Wang Y, Sun Y, Liu Z, Sarma SE, Bronstein MM, Solomon JM (2019) Dynamic graph CNN for learning on point clouds. ACM Trans Graph (TOG) 38(5):1–12 (1, 3, 7, 8)
Hou Y, Zhu X, Ma Y, Loy CC, Li Y (2022) Point-to-voxel knowledge distillation for lidar semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp 8479–8488
Smith JT, Warrington A, Linderman S (2022) Simplified state space layers for sequence modeling. In: Proceedings of the International Conference on Learning Representations
Guo M-H, Cai J-X, Liu Z-N, Mu T-J, Martin RR, Hu S-M (2021) Pct: point cloud transformer. Comput Vis Media 7:187–199
Yan X, Zheng C, Li Z, Wang S, Cui S (2020) Pointasnl: robust point clouds processing using nonlocal neural networks with adaptive sampling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp 5589–5598
Wang W, Xie E, Li X, Fan D-P, Song K, Liang D, Lu T, Luo P, Shao L (2022) Pvt v2: improved baselines with pyramid vision transformer. Comput Vis Media 8(3):415–424
Wu X, Lao Y, Jiang L, Liu X, Zhao H (2022) Point transformer v2: grouped vector attention and partition-based pooling. Adv Neural Inf Process Syst 35:33330–33342
Park C, Jeong Y, Cho M, Park J (2022) Fast point transformer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp 16949–16958
Fan L, Pang Z, Zhang T, Wang Y-X, Zhao H, Wang F, Wang N, Zhang Z (2022) Embracing single stride 3d object detector with sparse transformer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp 8458–8468
Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, Lin S, Guo B (2021) Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp 10012–10022
Sun P, Tan M, Wang W, Liu C, Xia F, Leng Z, Anguelov D (2022) Swformer: sparse window transformer for 3d object detection in point clouds. In: European Conference on Computer Vision. Springer, pp 426–442
Gu A, Dao T (2023) Mamba: linear-time sequence modeling with selective state spaces. Preprint at arXiv:2312.00752
Zhu L, Liao B, Zhang Q, Wang X, Liu W, Wang X (2024) Vision mamba: efficient visual representation learning with bidirectional state space model. Preprint at arXiv:2401.09417
Wang C, Tsepa O, Ma J, Wang B (2024) Graph-mamba: towards long-range graph sequence modeling with selective state spaces. Preprint at arXiv:2402.00789
Li K, Li X, Wang Y, He Y, Wang Y, Wang L, Qiao Y (2024) Videomamba: state space model for efficient video understanding. Preprint at arXiv:2403.06977
Gu A, Dao T, Ermon S, Rudra A, Ré C (2020) Hippo: recurrent memory with optimal polynomial projections. In: Advances in neural information processing systems
Gu A, Goel K, Ré C (2021) Efficiently modeling long sequences with structured state spaces. Preprint at arXiv:2111.00396
Nguyen E, Goel K, Gu A, Downs G, Shah P, Dao T, Baccus S, Ré C (2022) S4ND: modeling images and videos as multidimensional signals with state spaces. Adv Neural Inf Process Syst 35:2846–2861
Gupta A, Gu A, Berant J (2022) Diagonal state spaces are as effective as structured state spaces. Adv Neural Inf Process Syst 35:22982–22994
Gu A, Goel K, Gupta A, Ré C (2022) On the parameterization and initialization of diagonal state space models. Adv Neural Inf Process Syst 35:35971–35983
Smith JT, Warrington A, Linderman SW (2022) Simplified state space layers for sequence modeling. Preprint at arXiv:2208.04933
Hasani R, Lechner M, Wang T-H, Chahine M, Amini A, Rus D (2022) Liquid structural state-space models. Preprint at arXiv:2209.12951
Behrouz A, Hashemi F (2024) Graph mamba: towards learning on graphs with state space models. Preprint at arXiv:2401.14168
Uy MA, Pham Q-H, Hua B-S, Nguyen T, Yeung S-K (2019) Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp 1588–1597
Wu Z, Song S, Khosla A, Yu F, Zhang L, Tang X, Xiao J (2015) 3d shapenets: a deep representation for volumetric shapes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp 1912–1920
Yi L, Kim VG, Ceylan D, Shen I-C, Yan M, Su H, Lu C, Huang Q, Sheffer A, Guibas L (2016) A scalable active framework for region annotation in 3d shape collections. ACM Trans Graph (ToG) 35(6):1–12
Zhang R, Guo Z, Gao P, Fang R, Zhao B, Wang D, Qiao Y, Li H (2022) Point-M2AE: multi-scale masked autoencoders for hierarchical point cloud pre-training. Adv Neural Inf Process Syst 35:27061–27074
Zhao H, Jiang L, Jia J, Torr PH, Koltun V (2021) Point transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp 16259–16268
Hamdi A, Giancola S, Ghanem B (2021) MVTN: multi-view transformation network for 3d shape recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp 1–11
Ma X, Qin C, You H, Ran H, Fu Y (2022) Rethinking network design and local geometry in point cloud: a simple residual MLP framework. Preprint at arXiv:2202.07123
Z, Wang Z, Chen Z, Wu Y et al (2024) Pointramba: a hybrid transformer-mamba framework for point cloud analysis. Preprint at arXiv:2405.15463
Zhang T, Li X, Yuan H, Ji S, Yan S (2024) Point cloud mamba: point cloud learning via state space model. Preprint at arXiv:2403.00762
Han X, Tang Y, Wang Z, Li X (2024) Mamba3D: enhancing local features for 3d point cloud analysis via state space model. Preprint at arXiv:2404.14966
Liao Y, Xie J, Geiger A (2022) KITTI-360: a novel dataset and benchmarks for urban scene understanding in 2d and 3d. Pattern Anal Mach Intell (PAMI)
Acknowledgements
We thank the anonymous reviewers for their insightful comments.
Funding
This study was partially supported by the Tianshan Talent Training Program in the Autonomous Region, China (Grant Number: 2023TSYCLJ0023).
Author information
Authors and Affiliations
Contributions
Bo Liu was responsible for the entire experimental process and the writing of the manuscript. Xin Fan and Zhezhe Zhu handled data collection and analysis. Jialun Lv. and LongYu developed the software tools used in the study. Shengwei Tian supervised the entire research process and reviewed the manuscript. All authors participated in the manuscript review and gave final approval.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Liu, B., Tian, S., Yu, L. et al. PointUltra: ultra-efficient mamba framework for transformative point cloud analysis. J Supercomput 81, 562 (2025). https://doi.org/10.1007/s11227-025-07066-4
Accepted:
Published:
DOI: https://doi.org/10.1007/s11227-025-07066-4