
Abstract
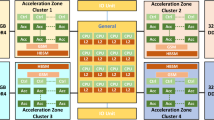
The streaming multiprocessor (SM) count in GPUs continues to increase to provide high computing power. To construct a scalable crossbar network that connects the SMs to the LLC slices and memory controllers, a cluster structure is exploited in GPUs where a group of SMs shares a network port. Unfortunately, current GPU spatial multitasking is unaware of this underlying network-on-chip infrastructure which poses the challenges and also the opportunities for the performance. In this paper, we observe that compared to the cluster-unaware multitasking, considering the cluster structure, the SM partition within a cluster and also the injecting policy of sharing the network port can bring significant performance improvement. Next, we propose a low-cost online profiling and scheduling policy that consists of two steps. The cluster-aware scheduling first determines the best SM partition within a cluster and then finds the proper injecting policy between the two co-executing applications. Both steps are achieved in online profiling which only incurs limited runtime overhead. The evaluation results show that for all workloads, our cluster-aware multitasking increases the system throughput by 12.9% on average (and up to 76.5%).














Similar content being viewed by others


Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Notes
Compared to the performance estimation approach, using actual isolated IPC offline only brings minimal performance difference (within 2%). To assess the impact of online profiling overhead, we also compared our cluster-aware scheduling approach to an offline analysis approach that determines the optimum SM allocation and NoC injection policy. We found the profiling overhead to be relatively small at 1.06% on average.
Our design is evaluated in the simulator since the current commercial GPUs do not provide the users with its detailed NoC architecture nor the programming interfaces to flexibly and explicitly control SMs based on its NoC location. The simulator-based methodology is widely used in computer architecture research. Please see examples in Bakhoda et al. (2010), Zhao et al. (2016a, 2016b), Ziabari et al. (2015), Cheng et al. (2018), Zhao et al. (2022) and so on.
References
Abdolrashidi A, Esfeden HA, Jahanshahi A, Singh K, Abu-Ghazaleh N, Wong D (2021) BlockMaestro: enabling programmer-transparent task-based execution in GPU systems. In: ISCA, pp. 333–346
Adriaens JT, Compton K, Kim NS, Schulte MJ (2012) The case for GPGPU spatial multitasking. In: HPCA, pp. 1–12
Aguilera P, Morrow K, Kim NS (2014) Fair share: allocation of GPU resources for both performance and fairness. In: ICCD, pp. 440–447
Ahn J, Kim J, Kasan H, Delshadtehrani L, Song W, Joshi A, Kim J (2021) Network-on-chip microarchitecture-based covert channel in GPUs. In: MICRO, pp. 565–577
Avalos Baddouh C, Khairy M, Green RN, Payer M, Rogers TG (2021) Principal kernel analysis: a tractable methodology to simulate scaled GPU workloads. In: MICRO, pp. 724–737
Bakhoda A, Yuan GL, Fung WWL, Wong H, Aamodt TM (2009) Analyzing CUDA workloads using a detailed GPU simulator. In: ISPASS, pp. 163–174
Bakhoda A, Kim J, Aamodt TM (2010) Throughput-effective on-chip networks for manycore accelerators. In: MICRO, pp. 421–432
Che S, Boyer M, Meng J, Tarjan D, Sheaffer JW, Lee S-H, Skadron K (2009) Rodinia: a benchmark suite for heterogeneous computing. In: IISWC, pp. 44–54
Cheng X, Zhao Y, Zhao H, Xie Y (2018) Packet pump: overcoming network bottleneck in on-chip interconnects for GPGPUs. In: DAC, pp. 84:1–84:6
Dai H, Lin Z, Li C, Zhao C, Wang F, Zheng N, Zhou H (2018) Accelerate GPU concurrent kernel execution by mitigating memory pipeline stalls. In: HPCA, pp. 208–220
Grauer-Gray S, Xu L, Searles R, Ayalasomayajula S, Cavazos J (2012) Auto-tuning a high-level language targeted to GPU Codes. In: InPar, pp. 1–10
He B, Fang W, Luo Q, Govindaraju NK, Wang T (2008) Mars: a mapreduce framework on graphics processors. In: PACT, pp. 260–269
Hsieh K, Ebrahimi E, Kim G, Chatterjee N, O’Connor M, Vijaykumar N, Mutlu O, Keckler SW (2016) Transparent offloading and mapping (TOM): Enabling programmer-transparent near-data processing in gpu systems. In: ISCA, pp. 204–216
Jog A, Kayiran O, Kesten T, Pattnaik A, Bolotin E, Chatterjee N, Keckler SW, Kandemir MT, Das CR (2015) Anatomy of GPU memory system for multi-application execution. In: MEMSYS, pp. 223–234
Lee J, Kim H (2012) TAP: A TLP-aware cache management policy For a CPU-GPU heterogeneous architecture. In: HPCA, pp. 1–12
Liang Y, Huynh HP, Rupnow K, Goh RSM, Chen D (2015) Efficient GPU spatial-temporal multitasking. IEEE Trans Parallel Distrib Syst 26(3):748–760
Liu L, Chang W, Demoullin F, Chou YH, Saed M, Pankratz D, Nowicki T, Aamodt TM (2021) Intersection prediction for accelerated GPU ray tracing. In: MICRO, pp. 709–723
Muthukrishnan H, Lustig D, Nellans D, Wenisch T (2021) GPS: a global publish-subscribe model for multi-GPU memory management. In: MICRO, pp. 46–58
Muthukrishnan H, Nellans D, Lustig D, Fessler JA, Wenisch TF (2021) Efficient multi-GPU shared memory via automatic optimization of fine-grained transfers. In: ISCA, pp. 139–152
Nvidia (2016) NVIDIA GP100 pascal architecture. http://www.nvidia.com/object/pascal-architecture-whitepaper.html
Nvidia (2017) NVIDIA Tesla V100 volta architecture. http://www.nvidia.com/object/volta-architecture-whitepaper.html
Nvidia (2017) Parallel thread execution ISA version 6.1. http://docs.nvidia.com/cuda/parallel-thread-execution/index.html
NVIDIA CUDA SDK code samples. https://developer.nvidia.com/cuda-downloads
Park JJK, Park Y, Mahlke S (2015) Chimera: collaborative preemption for multitasking on a shared GPU. In: ASPLOS, pp. 593–606
Sewell K, Dreslinski RG, Manville T, Satpathy S, Pinckney N, Blake G, Cieslak M, Das R, Wenisch TF, Sylvester D, Blaauw D, Mudge T (2012) Swizzle-switch networks for many-core systems. IEEE J Emerg Selected Topics Circuits Syst 2:278–294
Stratton JA, Rodrigues C, Sung I-J, Obeid N, Chang L-W, Anssari N, Liu GD, Hwu W-MW (2012) Parboil: a revised benchmark suite for scientific and commercial throughput computing. Tech. rep
Tanasic I, Gelado I, Cabezas J, Ramirez A, Navarro N, Valero M (2014) Enabling preemptive multiprogramming on GPUs. In: ISCA, pp. 193–204
Wang Z, Yang J, Melhem R, Childers B, Zhang Y, Guo M (2016) Simultaneous multikernel GPU: multi-tasking throughput processors via fine-grained sharing. In: HPCA, pp. 358–369
Wang L, Zhao X, Kaeli D, Wang Z, Eeckhout L (2018) Intra-cluster coalescing and CTA scheduling to reduce GPU NoC pressure. In: IPDPS
Wang H, Luo F, Ibrahim M, Kayiran O, Jog A (2018) Efficient and fair multi-programming in GPUs via effective bandwidth management. In: HPCA
Xu Z, Zhao X, Wang Z, Yang C (2019) Application-aware NoC management in GPUs multitasking. J Supercomput 75(8):4710–4730
Zhao X, Ma S, Li C, Eeckhout L, Wang Z (2016) A heterogeneous low-cost and low-latency ring-chain network for GPGPUs. In: ICCD, pp. 472–479
Zhao X, Ma S, Liu Y, Eeckhout L, Wang Z (2016) A low-cost conflict-free NoC for GPGPUs. In: Proceedings of the Design Automation Conference (DAC), pp. 34:1–34:6
Zhao X, Jahre M, Eeckhout L (2020) HSM: a hybrid slowdown model for multitasking GPUs. In: ASPLOS, pp. 1371–1385
Zhao X, Eeckhout L, Jahre M (2022) Delegated replies: alleviating network clogging in heterogeneous architectures. In: HPCA, pp. 1014–1028
Zhang J, Jung M (2021) Ohm-GPU: integrating new optical network and heterogeneous memory into gpu multi-processors. In: MICRO, pp. 695–708
Ziabari AK, Abellán JL, Ma Y, Joshi A, Kaeli D (2015) Asymmetric NoC architectures for GPU systems. In: NoCs, pp. 25:1–25:8
Acknowledgements
We thank the anonymous reviewers for their valuable comments. The work is supported by the National Natural Science Foundation of China (Grant No. 62102438), the Young Elite Scientists Sponsorship Program (No. 2020-JCJQ-QT-038, No.2022-JCJQ-QT-032) and sponsored by Beijing Nova Program.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
Research does not have any financial and non-financial competing interests.
Ethical approval
This manuscript belongs to the scope of engineering and does not involve human and animal research.
Consent for publication
Research does not include details, images, or videos relating to an individual person.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhao, X., Wang, H., Huang, A. et al. Cluster-aware scheduling in multitasking GPUs. Real-Time Syst 60, 1–23 (2024). https://doi.org/10.1007/s11241-023-09409-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11241-023-09409-x