
Abstract
How to generate robust image representations, when there is contamination from noisy pixels within the images, is critical for boosting the performance of image classification methods. However, such an important problem is not fully explored yet. In this paper, we propose a novel image representation learning method, i.e., collaborative linear coding (CLC), to alleviate the negative influence of noisy features in classifying images. Specifically, CLC exploits the correlation among local features in the coding procedure, in order to suppress the interference of noisy features via weakening their responses on coding basis. CLC implicitly divides the extracted local features into different feature subsets, and such feature allocation is indicated by the introduced latent variables. Within each subset, the features are ensured to be highly correlated, and the produced codes for them are encouraged to activate on the identical basis. Through incorporating such regularization in the coding model, the responses of noisy local features are dominated by the responses of informative features due to their rarity compared with the informative features. Thus the final image representation is more robust and distinctive for following classification, compared with the coding methods without considering such high order correlation. Though CLC involves a set of complicated optimization problems, we investigate the special structure of the problems and then propose an efficient alternative optimization algorithm. We verified the effectiveness and robustness of the proposed CLC on multiple image classification benchmark datasets, including Scene 15, Indoor 67, Flower 102, Pet 37, and PASCAL VOC 2011. Compared with the well established baseline LLC, CLC consistently enhances the classification accuracy, especially for the images containing more noises.


Similar content being viewed by others

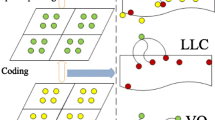

Notes
Here the “linear” in CLC means the reconstructed data term is a linear combination of basis in the codebook. Readers should not confuse the meaning of linear here with the one in linear convolutions.
The background features can be included if they are helpful for classifying the image, e.g., in the scene classification tasks as the extreme cases.
A small part of images have the annotations specially for the object segmentation challenge.
The annotations can be downloaded at http://www.cs.berkeley.edu/~bharath2/codes/SBD/download.html.
References
Boiman, O., Shechtman, E., & Irani, M. (2008). In defense of nearest-neighbor based image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1–8). Anchorage, AK, USA.
Bosch, A., Zisserman, A., & Muñoz, X. (2008). Scene classification using a hybrid generative/discriminative approach. IEEE Transactions on Pattern Analysis and Machine Intelligence, 30(4), 712–727.
Boureau, Y.-L., Bach, F. R., LeCun, Y., & Ponce, J. (2010). Learning mid-level features for recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2559–2566). San Francisco, CA, USA.
Candès, E. J., Li, X., Ma, Y., & Wright, J. (2011). Robust principal component analysis? Journal of the ACM (JACM), 58(3), 11.
Carreira, J., Li, F., & Sminchisescu, C. (2012). Object recognition by sequential figure-ground ranking. International Journal of Computer Vision, 98(3), 243–262.
Coates, A., & Ng, A. Y. (2011). The importance of encoding versus training with sparse coding and vector quantization. In Proceedings of the International Conference on Machine Learning (pp. 921–928). Bellevue, Washington, USA.
Everingham, M., Van Gool, L., Williams, C. K. I., Winn, J., & Zisserman, A. (2010). The pascal visual object classes (voc) challenge. International Journal of Computer Vision, 88(2), 303–338.
Fan, R.-E., Chang, K.-W., Hsieh, C.-J., Wang, X.-R., & Lin, C.-J. (2008). Liblinear: A library for large linear classification. The Journal of Machine Learning Research, 9, 1871–1874.
Gao, S., Tsang, I. W.-H., Chia, L.-T., & Zhao, P. (2010). Local features are not lonely - laplacian sparse coding for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 3555–3561). San Francisco, CA, USA.
Gao, S., Tsang, I. W.-H., & Chia, L.-T. (2013). Laplacian sparse coding, hypergraph laplacian sparse coding, and applications. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(1), 92–104.
van Gemert, J., Geusebroek, J.-M., Veenman, C. J., & Smeulders, A. W. M. (2008). Kernel codebooks for scene categorization. In Proceedings of the European Conference on Computer Vision (pp. 696–709). Marseille, France.
van Gemert, J., Veenman, C. J., Smeulders, A. W. M., & Geusebroek, J.-M. (2010). Visual word ambiguity. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(7), 1271–1283.
Gu, C., Lim, J. J., Arbelaez, P., & Malik, J. (2009). Recognition using regions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1030–1037). Miami, Florida, USA.
Hariharan, B., Arbelaez, P., Bourdev, L., Maji, S., & Malik, J. (2011). Semantic contours from inverse detectors. In Proceedings of the International Conference on Computer Vision (pp. 991–998). Barcelona, Spain.
Khan, F. S., van de Weijer, J., & Vanrell, M. (2009). Top-down color attention for object recognition. In Proceedings of the International Conference on Computer Vision (pp. 979–986). Kyoto, Japan.
Lazebnik, S., Schmid, C. & Ponce, J. (2006). Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition vol 2, (pp. 2169–2178). New York, NY, USA.
Li F.-F., Perona P. (2005) A bayesian hierarchical model for learning natural scene categories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition vol 2, (pp. 524–531). San Diego, CA, USA.
Li, L.-J., Su, H., Xing, E. P., & Li, F.-F. (2010). Object bank: A high-level image representation for scene classification & semantic feature sparsification. In Advances in Neural Information Processing Systems (pp. 1378–1386). British Columbia, Canada: Vancouver.
Liu, L., Wang, L., & Liu, X. (2011). In defense of soft-assignment coding. In Proceedings of the International Conference on Computer Vision (pp. 2486–2493). Barcelona, Spain.
Long, M., Ding, G., Wang, J., Sun, J., Guo, Y., & Yu, P. S. (2013). Transfer sparse coding for robust image representation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, IEEE (pp. 407–414). Portland, OR, USA.
Lowe, D. G. (2004). Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 60(2), 91–110.
Moosmann, F., Larlus, D. & Jurie, F. (2006). Learning saliency maps for object categorization. In Proceedings of the Conference on ECCV06 Workshop on the Representation and Use of Prior Knowledge in Vision, Graz, Austria.
Nilsback, M.-E. & Zisserman, A. (2008). Automated flower classification over a large number of classes. In Proceedings of the Indian Conference on Computer Vision, Graphics and Image Processing (pp. 722–729). Bhubaneswar, India.
Nilsback, M. E., & Zisserman, A. (2010). Delving deeper into the whorl of flower segmentation. Image and Vision Computing, 28(6), 1049–1062.
Oliva, A., & Torralba, A. (2001). Modeling the shape of the scene: A holistic representation of the spatial envelope. International Journal of Computer Vision, 42(3), 145–175.
Parkhi, O. M., Vedaldi, A., Zisserman, A., & Jawahar, C. V. (2012). Cats and dogs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 3498–3505). Providence, Rhode Island, USA.
Perronnin, F., Sánchez, J., & Mensink, T. (2010). Improving the fisher kernel for large-scale image classification. In Proceedings of the European Conference on Computer Vision (pp. 143–156). Springer: Berlin.
Quattoni, A., & Torralba, A. (2009). Recognizing indoor scenes. In IEEE Conference on Computer Vision and Pattern Recognition (pp. 413–420). Miami, Florida, USA.
Sánchez, J., Perronnin, F., Mensink, T., & Verbeek, J. J. (2013). Image classification with the fisher vector: Theory and practice. International Journal of Computer Vision, 105(3), 222–245.
van de Sande, K. E. A., Gevers, T., & Snoek, C. G. M. (2010). Evaluating color descriptors for object and scene recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(9), 1582–1596.
Vedaldi, A. & Fulkerson, B. (2008). Vlfeat: An open and portable library of computer vision algorithms. http://www.vlfeat.org/.
Vedaldi, A., Gulshan, V., Varma, M., & Zisserman, A. (2009). Multiple kernels for object detection. In Proceedings of the International Conference on Computer Vision (pp. 606–613). Kyoto, Japan.
Wang, J., Yang, J., Yu, K., Lv, F., Huang, T. S., & Gong, Y. (2010a). Locality-constrained linear coding for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 3360–3367). San Francisco, CA, USA.
Wang Z., Hu Y., Chia L.-T. (2010b) Image-to-class distance metric learning for image classification. In Proceedings of the European Conference on Computer Vision vol 1, (pp. 706–719). Crete, Greece.
Wang, Z., Feng, J., Yan, S., & Xi, H. (2013a). Image classification via object-aware holistic superpixel selection. IEEE Transactions on Image Processing, 22(11), 4341–4352.
Wang, Z., Feng, J., Yan, S., & Xi, H. (2013b). Linear distance coding for image classification. IEEE Transactions on Image Processing, 22(2), 537–548.
Wu, J., & Rehg, J. M. (2009). Beyond the euclidean distance: Creating effective visual codebooks using the histogram intersection kernel. In Proceedings of the International Conference on Computer Vision (pp. 630–637). Kyoto, Japan.
Xu, H., Caramanis, C., & Mannor, S. (2012). Sparse algorithms are not stable: A no-free-lunch theorem. IEEE Transactions on Pattern Analysis and Machine Intelligence, 34(1), 187–193.
Yang, J., Yu, K., Gong, Y., & Huang, T. S. (2009). Linear spatial pyramid matching using sparse coding for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1794–1801). Miami, Florida, USA.
Yao, B., Khosla, A., & Li, F.-F. (2011). Combining randomization and discrimination for fine-grained image categorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1577–1584). Colorado Springs, CO, USA.
Yu, K., & Zhang, T. (2010). Improved local coordinate coding using local tangents. In Proceedings of the International Conference on Machine Learning (pp. 1215–1222). Haifa, Israel.
Yu, K., Zhang, T., Gong, Y. (2009). Nonlinear learning using local coordinate coding. In Proceedings of the Conference on Advances in Neural Information Processing Systems vol 22, (pp. 2223–2231). Vancouver, Canada.
Yuan, X., & Yan, S. (2010). Visual classification with multi-task joint sparse representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 3493–3500). San Francisco, CA, USA.
Zarzoso, V., & Comon, P. (2010). Robust independent component analysis by iterative maximization of the kurtosis contrast with algebraic optimal step size. IEEE Transactions on Neural Networks, 21(2), 248–261.
Zhang, T., Ghanem, B., Liu, S., Xu, C., & Ahuja, N. (2013). Low-rank sparse coding for image classification. In Proceedings of the International Conference on Computer Vision (pp. 281–288). Sydney, Australia.
Acknowledgments
This work is supported partially by the National Natural Science Foundation of China under Grant 61203256 and 61233003, Natural Science Foundation of Anhui Province (1408085MF112), the Singapore National Research Foundation under its International Research Centre @Singapore Funding Initiative and administered by the IDM Programme Office, and the Fundamental Research Funds for the Central Universities (WK2100100018 and WK2100100021).
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Julien Mairal, Francis Bach, and Michael Elad.
Rights and permissions
About this article

Cite this article
Wang, Z., Feng, J. & Yan, S. Collaborative Linear Coding for Robust Image Classification. Int J Comput Vis 114, 322–333 (2015). https://doi.org/10.1007/s11263-014-0739-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-014-0739-z