
Abstract
This paper proposes a multi-level video representation by stacking the activations of motion features, atoms, and phrases (MoFAP). Motion features refer to those low-level local descriptors, while motion atoms and phrases can be viewed as mid-level “temporal parts”. Motion atom is defined as an atomic part of action, and captures the motion information of video in a short temporal scale. Motion phrase is a temporal composite of multiple motion atoms defined with an AND/OR structure. It further enhances the discriminative capacity of motion atoms by incorporating temporal structure in a longer temporal scale. Specifically, we first design a discriminative clustering method to automatically discover a set of representative motion atoms. Then, we mine effective motion phrases with high discriminative and representative capacity in a bottom-up manner. Based on these basic units of motion features, atoms, and phrases, we construct a MoFAP network by stacking them layer by layer. This MoFAP network enables us to extract the effective representation of video data from different levels and scales. The separate representations from motion features, motion atoms, and motion phrases are concatenated as a whole one, called Activation of MoFAP. The effectiveness of this representation is demonstrated on four challenging datasets: Olympic Sports, UCF50, HMDB51, and UCF101. Experimental results show that our representation achieves the state-of-the-art performance on these datasets.







Similar content being viewed by others



Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.Notes
Here we use the notation of \(\#\)-motion phrase to represent motion phrase of size \(\#\).
Fig. 5 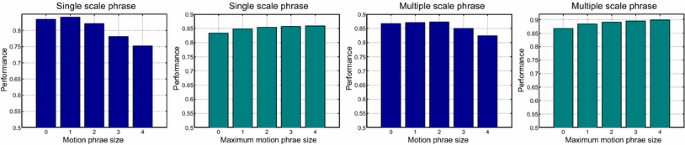
Exploration of the effect of motion phrase size on the Olympic Sports dataset. We first conduct experiments using the motion phrases from a single scale (first two figures). Then, we investigate the motion phrases mined from the multiple scales and verify the effectiveness hierarchical motion phrases (last two figures)

References
Aggarwal, J. K., & Ryoo, M. S. (2011). Human activity analysis: A review. ACM Computing Surveys, 43(3), 16.
Agrawal, R., & Srikant, R. (1994). Fast algorithms for mining association rules in large databases. In VLDB (pp. 487–499).
Amer, M. R., Xie, D., Zhao, M., Todorovic, S., & Zhu, S. C. (2012). Cost-sensitive top-down/bottom-up inference for multiscale activity recognition. In ECCV (pp. 187–200).
Berg, T. L., Berg, A. C., & Shih, J. (2010). Automatic attribute discovery and characterization from noisy web data. In ECCV (pp. 663–676).
Bishop, C. (2006). Pattern recognition and machine learning (Vol. 4). Berlin: Springer.
Bourdev, L. D., & Malik, J. (2009). Poselets: Body part detectors trained using 3d human pose annotations. In ICCV (pp. 1365–1372).
Cai, Z., Wang, L., Peng, X., & Qiao, Y. (2014). Multi-view super vector for action recognition. In CVPR (pp. 596–603).
Chang, C. C., & Lin, C. J. (2011). Libsvm: A library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2(3), 27.
Chen, Y., Zhu, L., Lin, C., Yuille, A. L., & Zhang, H. (2007). Rapid inference on a novel and/or graph for object detection, segmentation and parsing. In NIPS.
Csurka, G., Dance, C., Fan, L., Willamowski, J., & Bray, C. (2004). Visual categorization with bags of keypoints. In Workshop on statistical learning in computer vision, ECCV, Prague (Vol. 1, pp. 1–2).
Doersch, C., Gupta, A., & Efros, A. A. (2013). Mid-level visual element discovery as discriminative mode seeking. In NIPS pp. 494–502.
Felzenszwalb, P. F., Girshick, R. B., McAllester, D. A., & Ramanan, D. (2010). Object detection with discriminatively trained part-based models. IEEE Transactions Pattern Analysis and Machine Intelligence, 32(9), 1627–1645.
Forsyth, D. A., Arikan, O., Ikemoto, L., O’Brien, J. F., & Ramanan, D. (2005). Computational studies of human motion: Part 1, tracking and motion synthesis. Foundations and Trends in Computer Graphics and Vision 1(2/3).
Frey, B. J., & Dueck, D. (2007). Clustering by passing messages between data points. Science, 315, 972–976.
Gaidon, A., Harchaoui, Z., & Schmid, C. (2013). Temporal localization of actions with actoms. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(11), 2782–2795.
Gaidon, A., Harchaoui, Z., & Schmid, C. (2014). Activity representation with motion hierarchies. International Journal of Computer Vision, 107(3), 219–238.
Gorelick, L., Blank, M., Shechtman, E., Irani, M., & Basri, R. (2007). Actions as space-time shapes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 29(12), 2247–2253.
Jain, A., Gupta, A., Rodriguez, M., & Davis, L. S. (2013a). Representing videos using mid-level discriminative patches. In CVPR (pp. 2571–2578).
Jain, M., Jegou, H., & Bouthemy, P. (2013b). Better exploiting motion for better action recognition. In CVPR (pp. 2555–2562).
Jiang, Y., Dai, Q., Xue, X., Liu, W., & Ngo, C. (2012). Trajectory-based modeling of human actions with motion reference points. In ECCV (pp. 425–438).
Jiang, Y. G., Liu, J., Roshan Zamir, A., Laptev, I., Piccardi, M., Shah, M., & Sukthankar, R. (2013). THUMOS challenge: Action recognition with a large number of classes. http://crcv.ucf.edu/ICCV13-Action-Workshop/.
Karpathy, A., Toderici, G., Shetty, S., Leung, T., Sukthankar, R., & Fei-Fei, L. (2014). Large-scale video classification with convolutional neural networks. In CVPR (pp. 1725–1732).
Kliper-Gross, O., Gurovich, Y., Hassner, T., & Wolf, L. (2012). Motion interchange patterns for action recognition in unconstrained videos. In ECCV (pp. 256–269).
Kuehne, H., Jhuang, H., Garrote, E., Poggio, T., & Serre, T. (2011). HMDB: A large video database for human motion recognition. In ICCV (pp. 2556–2563).
Laptev, I. (2005). On space-time interest points. International Journal of Computer Vision, 64(2–3), 107–123.
Laxton, B., Lim, J., & Kriegman, D. J. (2007). Leveraging temporal, contextual and ordering constraints for recognizing complex activities in video. In CVPR (pp. 1–8).
Liu, J., Kuipers, B., & Savarese, S. (2011). Recognizing human actions by attributes. In CVPR (pp. 3337–3344).
Niebles, J. C., Chen, C. W., & Li, F. F. (2010). Modeling temporal structure of decomposable motion segments for activity classification. In ECCV (pp. 392–405).
Oliver, N., Rosario, B., & Pentland, A. (2000). A bayesian computer vision system for modeling human interactions. IEEE Transactions on Pattern Analysis and Machine Intelligence, 22(8), 831–843.
Parikh, D., & Grauman, K. (2011). Relative attributes. In ICCV (pp. 503–510).
Pirsiavash, H., & Ramanan, D. (2014). Parsing videos of actions with segmental grammars. In CVPR (pp. 612–619).
Raptis, M., Kokkinos, I., & Soatto, S. (2012). Discovering discriminative action parts from mid-level video representations. In CVPR (pp. 1242–1249).
Reddy, K. K., & Shah, M. (2013). Recognizing 50 human action categories of web videos. Machine Vision and Applications, 24(5), 971–981.
Rohrbach, M., Regneri, M., Andriluka, M., Amin, S., Pinkal, M., & Schiele, B. (2012). Script data for attribute-based recognition of composite activities. In ECCV.
Sadanand, S., & Corso, J. J. (2012). Action bank: A high-level representation of activity in video. In CVPR (pp. 1234–1241).
Sánchez, J., Perronnin, F., Mensink, T., & Verbeek, J. J. (2013). Image classification with the fisher vector: Theory and practice. International Journal of Computer Vision, 105(3), 222–245.
Sapienza, M., Cuzzolin, F., & Torr, P. H. S. (2012). Learning discriminative space-time actions from weakly labelled videos. In BMVC (pp. 1–12).
Schüldt, C., Laptev, I., & Caputo, B. (2004). Recognizing human actions: A local svm approach. In ICPR.
Si, Z., & Zhu, S. C. (2013). Learning AND-OR templates for object recognition and detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(9), 2189–2205.
Simonyan, K., & Zisserman, A. (2014). Two-stream convolutional networks for action recognition in videos. In NIPS (pp. 568–576).
Singh, S., Gupta, A., & Efros, A. A. (2012). Unsupervised discovery of mid-level discriminative patches. In ECCV (pp. 73–86).
Sivic, J., & Zisserman, A. (2003). Video google: A text retrieval approach to object matching in videos. In ICCV (pp. 1470–1477).
Soomro, K., Zamir, A. R., & Shah, M. (2012). UCF101: A dataset of 101 human actions classes from videos in the wild. CoRR abs/1212.0402.
Tang, K. D., Li, F. F., & Koller, D. (2012). Learning latent temporal structure for complex event detection. In CVPR (pp. 1250–1257).
Turaga, P. K., Chellappa, R., Subrahmanian, V. S., & Udrea, O. (2008). Machine recognition of human activities: A survey. IEEE Transactions on Circuits and Systems for Video Technology, 18(11), 1473–1488.
Wang, H., & Schmid, C. (2013a). Action recognition with improved trajectories. In ICCV (pp. 3551–3558).
Wang, H., & Schmid, C. (2013b). Lear-inria submission for the thumos workshop. In: ICCV Workshop on Action Recognition with a Large Number of Classes.
Wang, H., Kläser, A., Schmid, C., & Liu, C. L. (2013a). Dense trajectories and motion boundary descriptors for action recognition. International Journal of Computer Vision, 103(1), 60–79.
Wang, L., Qiao, Y., & Tang, X. (2013b). Mining motion atoms and phrases for complex action recognition. In ICCV (pp. 2680–2687).
Wang, L., Qiao, Y., & Tang, X. (2013c). Motionlets: Mid-level 3D parts for human motion recognition. In CVPR (pp. 2674–2681).
Wang, L., Qiao, Y., & Tang, X. (2014a). Latent hierarchical model of temporal structure for complex activity classification. IEEE Transactions on Image Processing, 23(2), 810–822.
Wang, L., Qiao, Y., & Tang, X. (2014b). Video action detection with relational dynamic-poselets. In ECCV (pp. 565–580).
Wang, L., Qiao, Y., & Tang, X. (2015). Action recognition with trjectory-pooled deep-convolutional descriptors. In CVPR (pp. 4305–4314).
Wang, S. B., Quattoni, A., Morency, L. P., Demirdjian, D., & Darrell, T. (2006). Hidden conditional random fields for gesture recognition. In CVPR (pp. 1521–1527).
Wang, X., Wang, L., & Qiao, Y. (2012). A comparative study of encoding, pooling and normalization methods for action recognition. In ACCV (pp. 572–585).
Wu, J., Zhang, Y., & Lin, W. (2014). Towards good practices for action video encoding. In CVPR (pp. 2577–2584).
Yao, B., & Li, F. F. (2010). Grouplet: A structured image representation for recognizing human and object interactions. In CVPR.
Zhang, W., Zhu, M., & Derpanis, K. G. (2013). From actemes to action: A strongly-supervised representation for detailed action understanding. In ICCV (pp. 2248–2255).
Zhao, Y., & Zhu S. C. (2011). Image parsing with stochastic scene grammar. In NIPS (pp. 73–81).
Zhu ,J., Wang, B., Yang, X., Zhang, W., & Tu, Z. (2013). Action recognition with actons. In ICCV (pp. 3559–3566).
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Ivan Laptev, Josef Sivic, and Deva Ramanan.
Rights and permissions
About this article

Cite this article
Wang, L., Qiao, Y. & Tang, X. MoFAP: A Multi-level Representation for Action Recognition. Int J Comput Vis 119, 254–271 (2016). https://doi.org/10.1007/s11263-015-0859-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-015-0859-0